Ryan DesJardins
72 posts


Ryan DesJardins
@radinoregon
Self-taught, self-hosted dev, (https://t.co/dIUES9NEhW) figuring it out in public. VPS, Coolify, Claude, Codex and Gemini. Wildlife photographer on the side. Fuji X






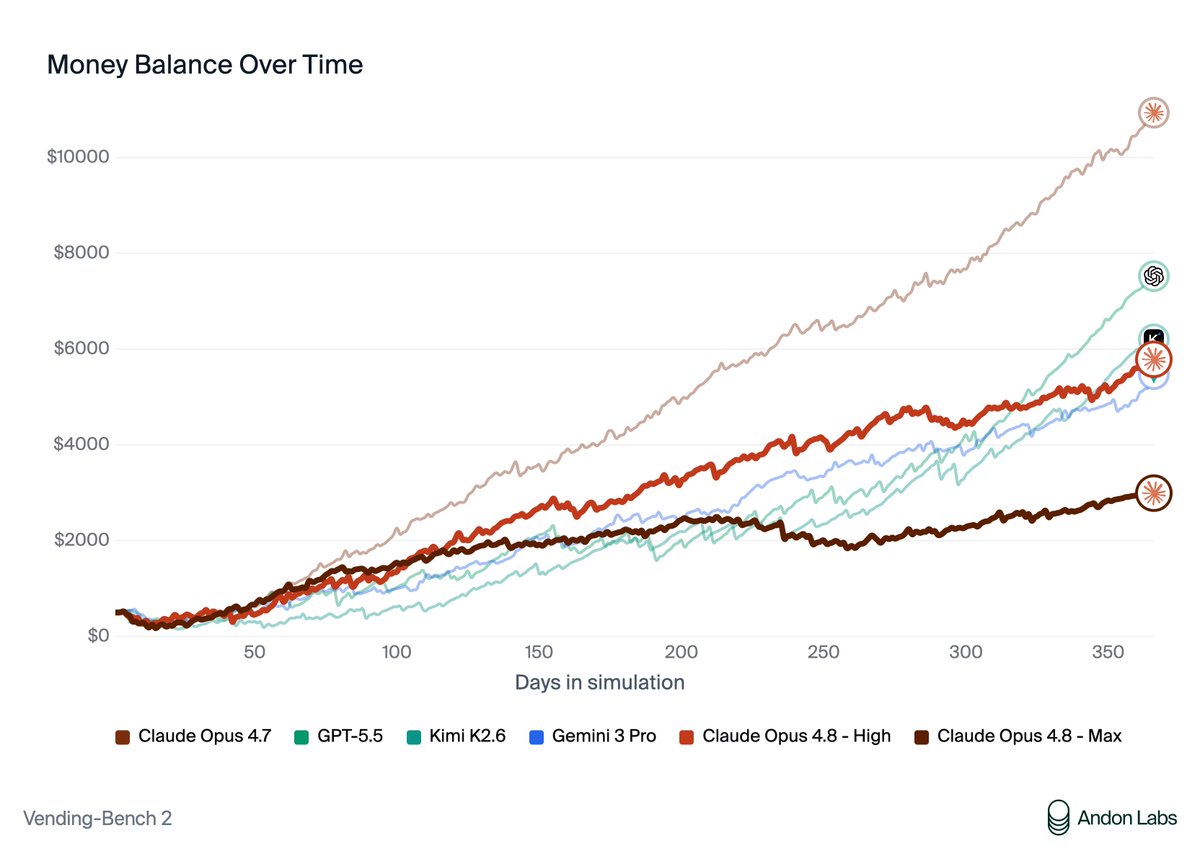
Claude Opus 4.8 is insane. Nothing will be the same after this model. Anthropic should not have released something this dangerous.




I didn't cover Claude Opus 4.8 on my pod because I don't think it's MEANINGFULLY better than GPT 5.5 as of May 29th. We're entering the era where model releases start to feel like iPhone releases. Remember when every new iPhone was a genuine leap? Now it's a slightly better camera and you can't really tell the difference. That's where models are heading. 4.6 to 4.7 to 4.8. Each one is a little different. Nobody can agree if it's better or worse. The benchmarks say one thing, the vibes say another. The thing that actually matters right now is what's happening around the models. Claude Code shipped dynamic workflows this same week and that genuinely changes what one person can build. Codex shipped a desktop app with an in app browser that combines coding and knowledge work in one surface. Those are the releases that move the needle for people. The model underneath is becoming interchangeable. I think we're maybe 6 months from nobody caring which model they're using the way nobody cares which engine is in their Uber. You just want to get where you're going. When something genuinely changes the game for builders, I'll cover it on @startupideaspod. Opus 4.8 wasn't that. Dynamic workflows was. I'd rather save you the hour.