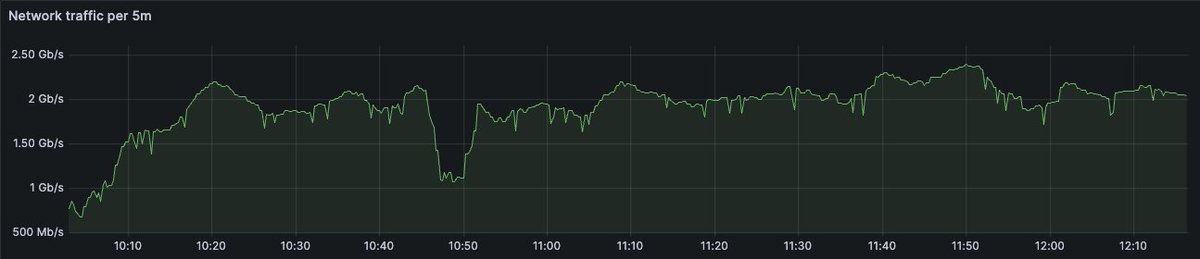
I'm attending #AWSSummit in Hamburg next week. Ping me if you'll be there. I would love to chat about Postgres, real-time analytics and time-series.
Tiger Data - Creators of TimescaleDB@TigerDatabase
TimescaleDB will be at #AWSSummit Hamburg. Let’s talk PostgreSQL, real-time analytics, time-series workloads on AWS, and AI applications built on operational data. Book a meeting with our team at the event! tsdb.co/i4nemls3
English