Sabitlenmiş Tweet

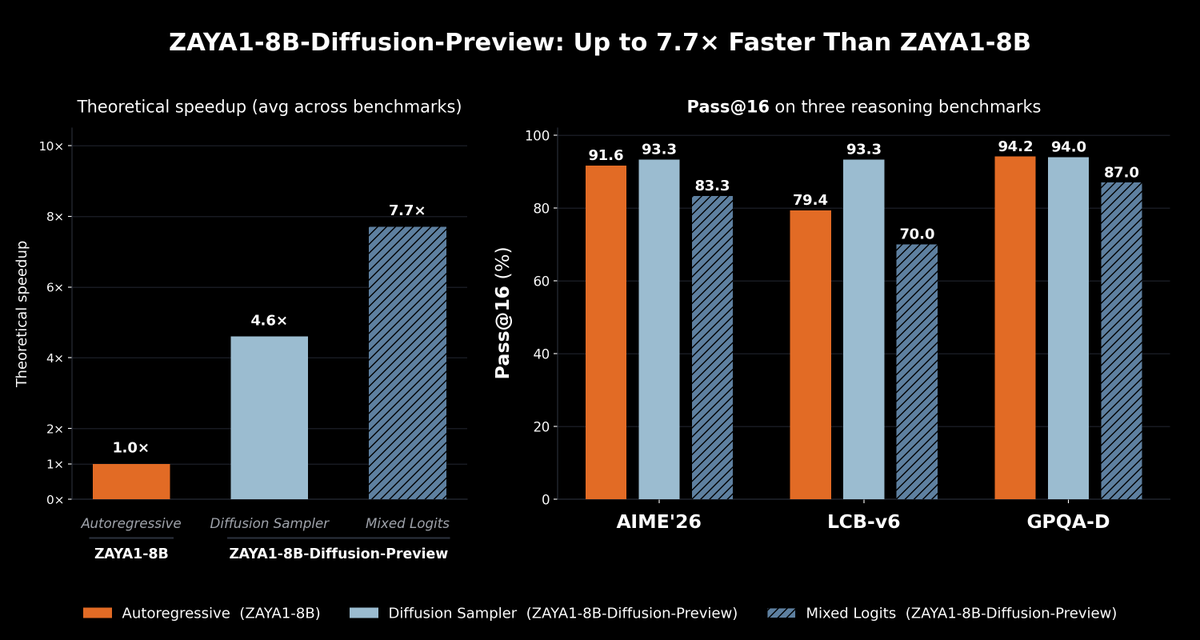
new model! strong <1B active MoE
led data and posttraining for this release. cca goat @rishiiyer01 and the pretraining squad cooked
x.com/ZyphraAI/statu…
Zyphra@ZyphraAI
Today we're releasing ZAYA1-8B, a reasoning MoE trained on @AMD and optimized for intelligence density. With <1B active params, it outperforms open-weight models many times its size on math and reasoning, closing in on DeepSeek-V3.2 and GPT-5-High with test-time compute. 🧵
English