For a rigorous treatment of these topics, see Moritz Hardt's book on the science of machine learning benchmarks
mlbenchmarks.org
English
Ricardo Olmedo
126 posts

@rdolmedo_
PhD student @MPI_IS, working with Moritz Hardt and Bernhard Schölkopf | Currently visiting @Stanford
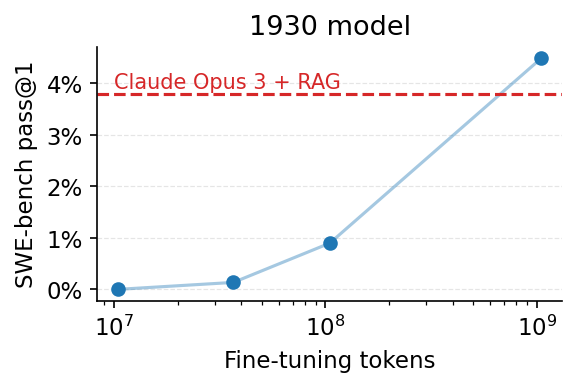
We fine-tuned Alec Radford’s 1930 vintage LLM to solve SWE-bench issues. After just ‼️250‼️ training examples, the model solves its first issue, a simple patch to the xarray library. 🧵👇

We fine-tuned Alec Radford’s 1930 vintage LLM to solve SWE-bench issues. After just ‼️250‼️ training examples, the model solves its first issue, a simple patch to the xarray library. 🧵👇