Sabitlenmiş Tweet

hyperv bugzz bounties fuzzing and bananas, something in between those lines => rezer0dai.github.io/biug-bounties/
English
Chief Banana
3K posts

@rezer0dai
Non-violence leads to the highest ethics, which is the goal of all evolution. Until we stop harming all other living beings, we are still savages. ~ T.A.Edison


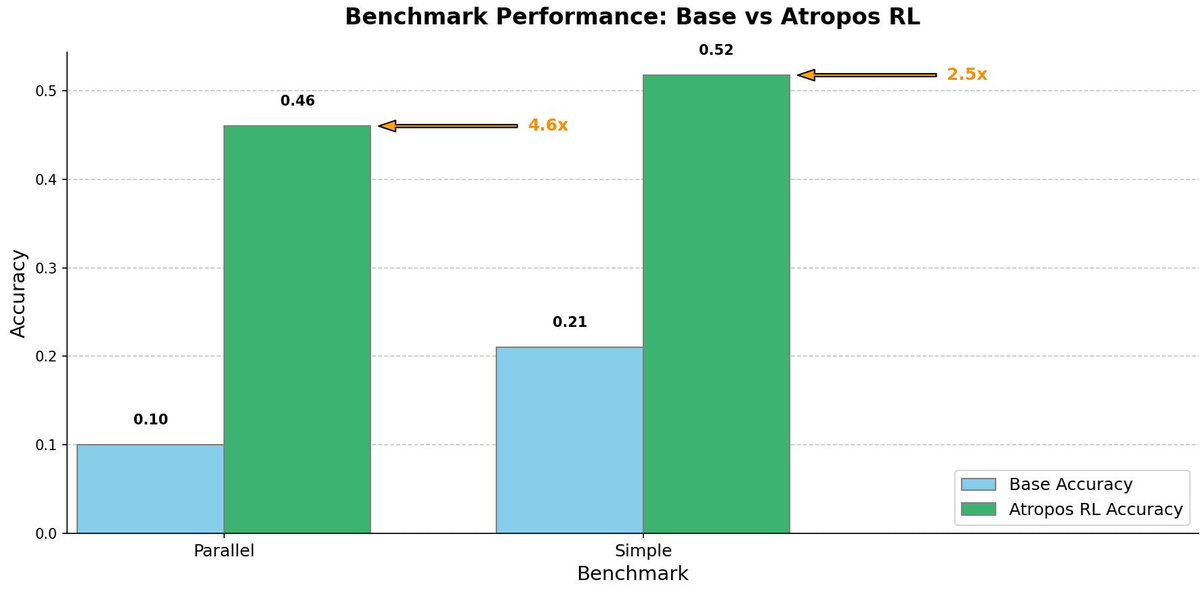
Reinforcement Learning in the era of LLMs requires scalable, distributed systems to push the boundaries of reasoning and alignment. Today - we release Atropos - our RL environments framework. github.com/NousResearch/A… Atropos is a rollout framework for reinforcement learning with foundation models that supports complex and diverse environments for advancing the capabilities of foundation models. In Greek mythology, Atropos was the eldest of the three Fates. While her sisters spun and measured the threads of mortal lives, Atropos alone held the shears that would cut these threads, determining the final destiny of each soul. Just as Atropos guided souls to their ultimate fate, this system guides language models toward their optimal potential through reinforcement learning. The work on Atropos was led by @dmayhem93 and built alongside @teknium, @rogershijin, @max_paperclips, @nullvaluetensor, @JSupa15, @artemsya and @karan4d





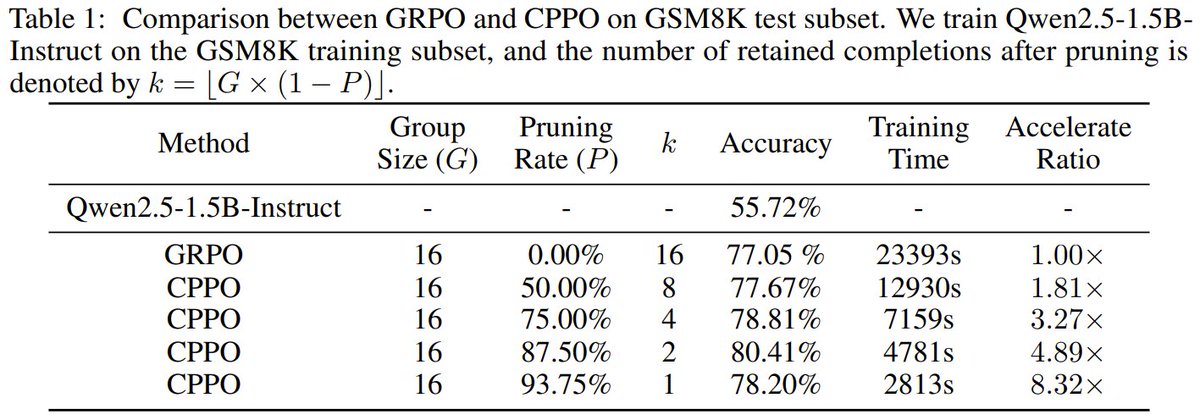












just a reminder trl grpo is not same as same as described in deepseek paper :) Its doesn't have clipping objective, which is key innovation in ppo, grpo has clipping + kl trl just have kl which is technically incorrect

