Derek Lu retweetledi
Derek Lu
202 posts






Derek Lu retweetledi

我所知道的 Manus 团队信息
Manus 刷屏一整天,登上了微博热搜,官媒也在传播。我觉得 Deepseek 和 Manus 的意义不止在于产品本身,更在于给国内沉寂多年的创投圈,带来了很多生机和希望。
Monica 和 Manus 是同一个公司的两款产品,就像 QQ 和微信的关系。
1/
肖弘(ID: Red, 小宏)是公司的 CEO,base 武汉,华中科大毕业的 90 后,大学期间就在创业;后来做了公众号生态的数据工具产品「壹伴」、企业微信生态的私域 SaaS 工具「微伴」,拿过真格基金、腾讯的投资,后被另一个 SaaS 公司收购;2022 年再次创业做了 Monica,又拿了真格的投资。
2023 年初火爆的一个插件工具产品 ChatGPT for Google(作者也是华中科大毕业的),也是被 Monica 收购的,金额在十万美元级别。不过据说收购后,这个插件产品及代码被束之高阁,实际上并没有融入到 Monica 产品中。
2/
合伙人是张涛 (@hidecloud),也是我的老朋友、老同事、老乡,绝对是做产品的一把好手,超过 15 年经验的产品老兵,大厂创业公司都摸爬滚打过。hidecloud 之前加入过王慧文的 AI 项目「光年之外」,去年加入 Monica,最近主导团队做了 Manus。
hidecloud 之前也短暂在真格基金做过 EIR (驻场企业家),跟真格的管理合伙人 yusen 交流很多。
Manus 初期采用邀请码机制引发了 FOMO,是今天传播爆发的一个重要原因。不过如果你知道 hidecloud 的产品背景和整活经验,就不会觉得惊讶了。
在我印象里,hidecloud 是一个对新事物、新技术十分敏感的 PM,也热爱分享,去年、今年在真格基金办公室组织过两次关于 AI 的交流分享,我都去现场学习了。
2020 年时,Red 和 hidecloud 都在我组织的职场社区里,做过关于 SaaS 产品和创业的分享,当时疫情影响很紧张,他们的热情分享给我的创业项目带来了很多帮助。现在 Manus 爆发,我真心为他们感到高兴。
3/
视频中的季逸超 (Peak Ji) 是 Manus 的 Co-founder 和首席科学家。Peak 是有名的少年极客,20 岁创业做的「猛犸浏览器」就很有名,也是拿过真格基金的投资。
我不知道 Peak 是什么时候加入 Monica / Manus 公司的,也许背后有真格基金作为共同投资人的撮合和推动。
谁是 Manus 的投资人
目前的公开信息,Manus 的机构投资者就是真格基金。今天爆火之后,估计国内所有活跃的 VC、大厂战投都已经找上门了,下一轮融资应该很快就敲定了。
不过我今天发现,前 Robinhood Crypto 负责人 @PatrickKavanagh 发推说「自豪成为 Manus 的投资人」,也许 Manus 此前还有其它融资还没有批露吧。
Sea@Sea_Bitcoin
一夜之间,中国团队做的通用 AI Agent 产品 Manus 刷屏了 看了官网的一些 Use cases,很震撼,也非常期待试用 视频中的季逸超是少年极客,20 岁拿到真格基金的投资,当年的明星创业者 Manus 所属公司的另一个产品 Monica 也是知名的 AI 应用 恭喜 @hidecloud,这一波要爆了 🔥
中文
Derek Lu retweetledi

昨天在偶然刷到这个网站 - 《动画巡礼》
anitabi.cn/map
作者将各种日本动画的场景标注在 Google 地图上,数据特别丰富,全是力气活,我在想这么多都是人工标注的吗?真的好棒啊,还开放了API,交互也做的很不错,喜欢日本动漫的朋友们真的不能错过哈,去日本可以直接按照标注去玩了,也可以在特定的地点拍对比图。
开源库在这里:github.com/anitabi 感兴趣的同学还能 PR 提交自己的数据。
还问一下各位推友:有没有类似电影在地图上的标注网站呢?我会非常感兴趣。
中文
Derek Lu retweetledi

Derek Lu retweetledi



Derek Lu retweetledi

OpenAI 的大神 Andrej Karpathy 前几天在他的 YouTube 频道讲了一堂课,系统的介绍了大语言模型,内容深入浅出,非常赞,抽空将它翻译成了双语,由于内容较长,我将分批上传,以下是第一部分精校后的双语视频,字幕文稿如下:
Intro: Large Language Model (LLM) talk
大家好。最近,我进行了一场关于大语言模型的 30 分钟入门讲座。遗憾的是,这次讲座没有被录制下来,但许多人在讲座后找到我,他们告诉我非常喜欢那次讲座。因此,我决定重新录制并上传到 YouTube,那么,让我们开始吧,为大家带来“忙碌人士的大语言模型入门”系列,主讲人 Scott。好的,那我们开始吧。
LLM Inference
首先,什么是大语言模型 (Large Language Model) 呢?其实,一个大语言模型就是由两个文件组成的。在这个假设的目录中会有两个文件。
以 Llama 2 70B 模型为例,这是一个由 Meta AI 发布的大语言模型。这是 Llama 系列语言模型的第二代,也是该系列中参数最多的模型,达到了 700 亿。LAMA2 系列包括了多个不同规模的模型,70 亿,130 亿,340 亿,700 亿是最大的一个。
现在很多人喜欢这个模型,因为它可能是目前公开权重最强大的模型。Meta 发布了这款模型的权重、架构和相关论文,所以任何人都可以很轻松地使用这个模型。这与其他一些你可能熟悉的语言模型不同,例如,如果你正在使用 ChatGPT 或类似的东西,其架构并未公开,是 OpenAI 的产权,你只能通过网页界面使用,但你实际上没有访问那个模型的权限。
在这种情况下,Llama 2 70B 模型实际上就是你电脑上的两个文件:一个是存储参数的文件,另一个是运行这些参数的代码。这些参数是神经网络(即语言模型)的权重或参数。我们稍后会详细解释。因为这是一个拥有 700 亿参数的模型,每个参数占用两个字节,因此参数文件的大小为 140 GB,之所以是两个字节,是因为这是 float 16 类型的数据。
除了这些参数,还有一大堆神经网络的参数。你还需要一些能运行神经网络的代码,这些代码被包含在我们所说的运行文件中。这个运行文件可以是 C 语言或 Python,或任何其他编程语言编写的。它可以用任何语言编写,但 C 语言是一种非常简单的语言,只是举个例子。只需大约 500 行 C 语言代码,无需任何其他依赖,就能构建起神经网络架构,并且主要依靠一些参数来运行模型。所以只需要这两个文件。
你只需带上这两个文件和你的 MacBook,就拥有了一个完整的工具包。你不需要连接互联网或其他任何设备。你可以拿着这两个文件,编译你的 C 语言代码。你将得到一个可针对参数运行并与语言模型交互的二进制文件。
比如,你可以让它写一首关于 Scale AI 公司的诗,语言模型就会开始生成文本。在这种情况下,它会按照指示为你创作一首关于 Scale AI 的诗。之所以选用 Scale AI 作为例子,你会在整个演讲中看到,是因为我最初在 Scale AI 举办的活动上介绍过这个话题,所以演讲中会多次提到它,以便内容更具体。这就是我们如何运行模型的方式。只需要两个文件和一台 MacBook。
我在这里稍微有点作弊,因为这并不是在运行一个有 700 亿参数的模型,而是在运行一个有 70 亿参数的模型。一个有 700 亿参数的模型运行速度大约会慢 10 倍。但我想给你们展示一下文本生成的过程,让你们了解它是什么样子。所以运行模型并不需要很多东西。这是一个非常小的程序包,但是当我们需要获取那些参数时,计算的复杂性就真正显现出来了。
那么,这些参数从何而来,我们如何获得它们?因为无论 run.c 文件中的内容是什么,神经网络的架构和前向传播都是算法上明确且公开的。
Andrej Karpathy@karpathy
New YouTube video: 1hr general-audience introduction to Large Language Models youtube.com/watch?v=zjkBMF… Based on a 30min talk I gave recently; It tries to be non-technical intro, covers mental models for LLM inference, training, finetuning, the emerging LLM OS and LLM Security.
中文
Derek Lu retweetledi

推荐 B 站上的一个合集《AI 论文精读系列》,bilibili.com/video/BV1H44y1…,主讲人是亚马逊资深首席科学家李沐,讲的比较清晰,目前内容还在持续更新中。
当前这个视频聊的是“如何读论文”,我总结下来是这么个「三遍阅读法」:
1)扫一眼:看标题、摘要、结论,确认研究方向是否与自己的研究方向匹配
2)圈重点:理出重要的图、表,圈出相关文献,读不懂,先去读引用的文献
3)问问题:论文提出了什么问题?用什么方法来解决这个问题?实验是怎么做的?
我的思路跟他还有一些差异,除了上面三个步骤,还会将我消化的内容整理好,然后输出给 ChatGPT,让 AI 结合论文来评价我理解的对不对。如果觉得有价值,还会分享到社交媒体,跟大家交流,确实也能收到不少优质的反馈。

中文
Derek Lu retweetledi

【2023 美区 Apple ID 注册充值指南|国内网络无需信用卡】你需要注册一个自己的美区 Apple ID,无论是安全还是方便的角度,发现很多朋友都还用的别人“公交车”的形式。今年美区 Apple ID 注册方式、和充值都产生了比较大的变动,就写篇教程分享给需要的:blog.qust.me/appleid2023

中文
Derek Lu retweetledi

《自下向上的计算机科学》是一个从基础层面学习计算机科学的综合性在线资源,涵盖主题广泛,包括编程语言、算法和计算机体系结构。内容清晰易懂,适合初学者和有经验的程序员。这本书侧重于理解计算机科学的基本原理,而不仅仅是教授特定的编程语言或工具。
bottomupcs.com/index.html

中文
Derek Lu retweetledi
Derek Lu retweetledi


Derek Lu retweetledi

拿这个视频为例,虽然抖音也是奶头乐,也是娱乐至死,但是抖音经常一朵云遮挡在胸前,连乳沟都不敢展现,跳舞的也都是穿很严格的打底裤。资本主义的奶头乐,是真的奶头乐。韩国的团队在油管上做这种视频的越来越多。大陆的很多团队还没意识到,国际化视野不足啊
我指的这个类型其实是完全不裸露三点的,纯擦边视频……在国内其实并不违法,但是国内的平台现在都控制起来了
youtube.com/watch?v=Udq49T…

YouTube
中文
Derek Lu retweetledi

Derek Lu retweetledi

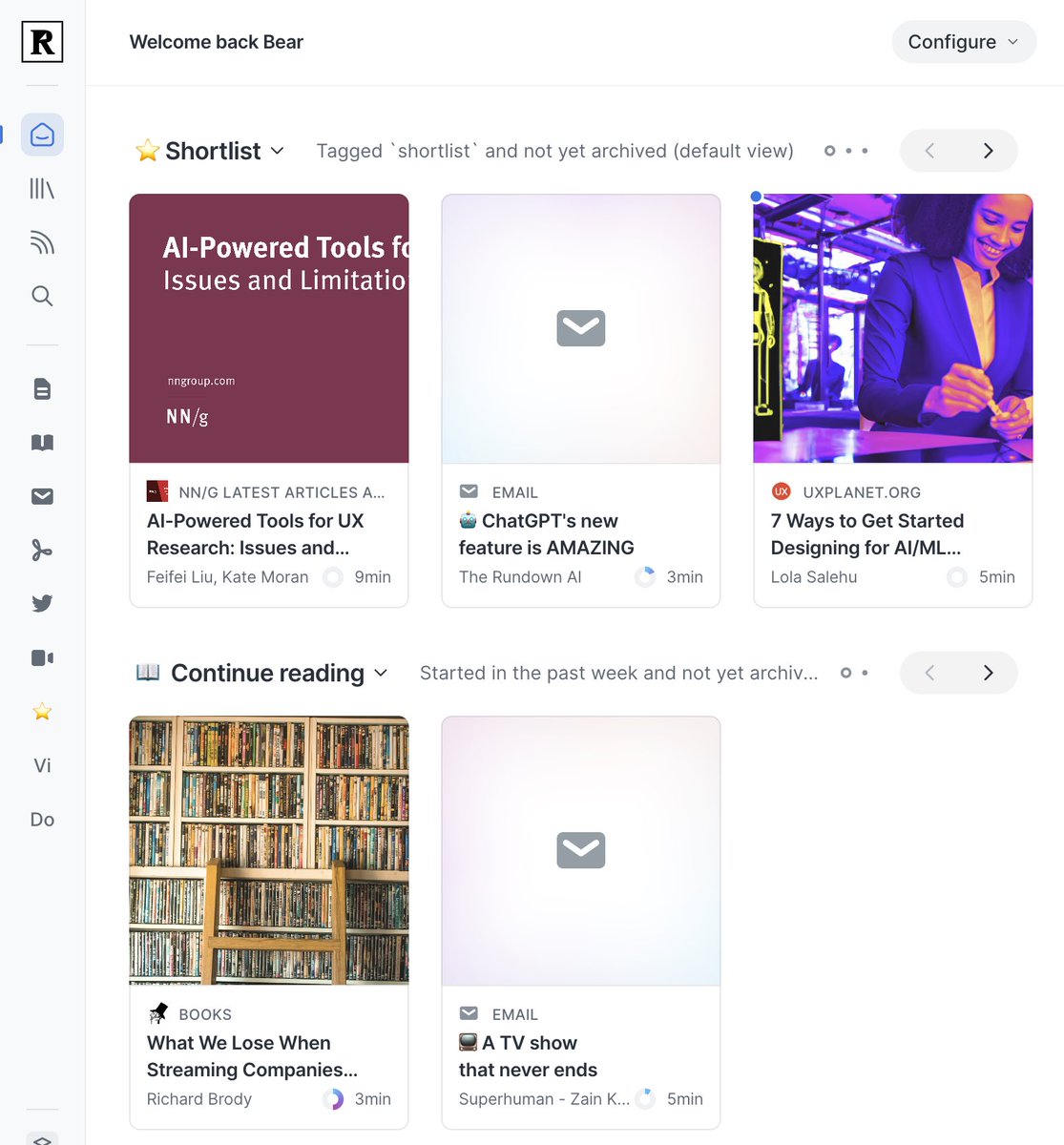
前几天我在推特上问了个问题:哪里可以读到优质的中文文章?但没得到答案。我发现阅读好文章是提升信息质量的好办法:读书适合专题类的学习,节奏较慢,而社交媒体是无法学到有一定深度的东西的。如果把这个问题拓展一下,那就是:如何找到和阅读优质的文章?
英文文章比较好找,比如安装浏览器插件后,我就能直接读经济学人、Wired、彭博社的优质文章,还能保存到Readwise Reader里,甚至翻译成中英对照。希望每天都能读一篇好文章,并分享一下心得。这样,我既能更新自己的信息储备,也有内容可以分享,还能给我的Newsletter提供素材。至于中文,先从阅读三联生活周刊的文章开始吧,后面再慢慢添加信息源。
目前来看,对于深入要阅读的内容,我初步的流程是:每周固定一个时间,查看信息源,然后用Paywall bypass可以阅读全文(还是没有能力订阅所有的付费阅读哈哈),用沉浸式阅读插件翻译成中英对照,然后存到Readwise Reader里,再每天阅读一篇。阅读时直接高亮值得记录的原文。读完后语音写总结和感受,用ChatGPT整理,分享,再保存到Notion。事后再用每天的Readwise笔记回顾来过一下摘记保持记忆,完美。
中文
Derek Lu retweetledi

Derek Lu retweetledi
如果我的孩子在国内上计算机专业,我会推荐他们看这些课程:
MIT
的 Introduction to Deep Learning introtodeeplearning.com
哈佛大学的CS 50: pll.harvard.edu/course/cs50-in…
斯坦福 cs25:web.stanford.edu/class/cs25/
另外可以在Edx.org这个网站上看到各大名校的公开课程:edx.org/schools-partne…




中文