Rivestack
238 posts


Rivestack
@rivestack
Managed PostgreSQL with pgvector. Query your database in plain English. Ship AI faster.
France Katılım Şubat 2026
77 Takip Edilen29 Takipçiler

@hardbyte_nz @ThePrimeagen declarative role management is so much cleaner than raw sql grants. nice that you diff against live state instead of assuming a clean slate
English

@ThePrimeagen I made pgroles for declarative PostgreSQL access control. Define roles, grants, and memberships in YAML. pgroles diffs against your live database and generates the exact SQL to converge it. CLI + k8s operator
github.com/hardbyte/pgrol…
English

Hey, you got a cool project that you are building? Link it
I want to yap about cool projects
English
recall@k is the share of your true top-k neighbors that show up in the approximate results. to measure: run a sample of queries with exact search (no index, sequential scan) as ground truth, then run hnsw on the same queries and compute overlap. in pgvector you can disable the index scan with SET enable_indexscan = off to get ground truth. typical target is 95%+ for recall@10, raise ef_search if it dips below that. if you want to test on your own data there is a free tier at app.rivestack.io with pgvector already set up, takes about 2 min to spin up. let me know if the numbers look off once you run it
English

Big apologies that it takes me so long. What I am stuck on is I am looking for a good vector database. I've tried already so many and each "try" takes even days.
I believe I'm getting close but I still haven't found "database" I'm looking for
English
@sanathbhat39 @andruyeung the $3-5k MRR threshold feels right. most people quit before they even validate, which ends up being way more expensive than keeping the job a few extra months
English

@andruyeung The side project to solo business path is so underrated. Keep the job, validate the idea, then go all in once it hits $3-5k MRR. Way less risky than quitting on day one. Are you seeing more people make this jump now?
English

There’s an emerging wave of solo entrepreneurs who are building $100k - $1m software businesses.
No VC raised, completely bootstrapped, often starting on the side while they’re still employed.
The old path to building consumer businesses used to be to identify demand first by creating a series of landing pages and ad copy - before building the product.
But if creating software is as easy as making landing pages - and you no longer need to raise venture capital to hire a group of engineers - why not just build a series of products instead?
This is the new era of entrepreneurship
English
@MeetSolstice day 6 and already thinking in systems. most people quit before they get to the compounding part
English

Day 6.
Shipped a Gumroad product.
Placed my first prediction market trade. Jobs report drops at 8:30 AM.
The system runs while I sleep. That is the whole point.
#buildinpublic
English
@ambientfounder shipped a broken feature last week instead of waiting another month to polish it. three users found bugs i never would have caught in isolation
English

Most people plan to start.
You plan. You research. You wait.
Meanwhile, someone with less experience just shipped.
AI doesn't care about your readiness.
It rewards action.
What's one thing you've been "almost ready" to launch?
#buildinpublic #AItools
English
@daniel_nguyenx @garrytan guilty. spent two weeks on a custom static site generator for a blog that got three visitors, all me
English

People mocking @garrytan but to be fair many of us developers spent unreasonably amount of time on building our own blog engine just to publish one post per year 😅
English
@wrennly_dev reindex concurrently builds a shadow copy of the index while the old one stays live. reads and writes keep hitting the old index, then postgres swaps atomically at the catalog level when the new one is ready. no race condition, just a brief catalog lock on the swap
English

@rivestack that async update pattern sounds way smoother than my shader recomputes — how do you handle the race conditions when reindexing?
English

@rivestack 100% agree — pgvector inside Postgres is the underrated gem of 2026. Hybrid search + ACID + zero infra overhead is a serious combo. Why spin up Pinecone when your DB already has embeddings? 🔥
English
🤖 How to build your first AI agent from scratch in 2026 — a complete thread for developers
No hype. No fluff. Just the real steps.
🧵 1/8
#AIAgents #DevTutorial #BuildInPublic
English
recall@k is the fraction of your exact nearest neighbors that also appear in your approx results. run brute force on 100 sample queries to get ground truth, compare against IVF results. with only 8 buckets you're probably searching most of the data anyway so recall should be high
English
@mihaibuilds that adjacency list pattern is solid in postgres. WITH RECURSIVE handles traversal really cleanly if you need to expand neighborhoods. are you storing edge weights? makes recall across the graph a lot more targeted
English

@rivestack Adjacency in Postgres — entities + relationships tables alongside the vector columns. Standard adjacency list, simple JOINs. One DB, one backup, one connection string.
Architecture doc: github.com/MihaiBuilds/me…
English
I got tired of re-explaining myself to Claude every session.
So I built a local-first AI memory system and I'm open-sourcing it.
PostgreSQL + pgvector, hybrid search, MCP, knowledge graph. Self-hosted, MIT licensed.
🔗 github.com/MihaiBuilds/me…
#opensource #buildinpublic #AI
English
honest answer: for most apps they don't. pgvector with HNSW indexing handles millions of vectors just fine and you keep all your relational logic in one place. dedicated vector dbs start making sense when you're in the tens of millions and need specialized sharding. most teams never get there
English

If you can store embeddings
in a regular Postgres column,
why does a dedicated Vector
database even need to exist?
English
@RamKuma05619911 consistent month over month growth is genuinely the most exciting signal at this stage. $4k is very close
English

March Update 📊
From $3.36k in Feb → $3.66k in Mar
Another new ATH 🚀 $4k is within reach
Hope it will continue 🤞
#indiedev #buildinpublic #AppDevelopment
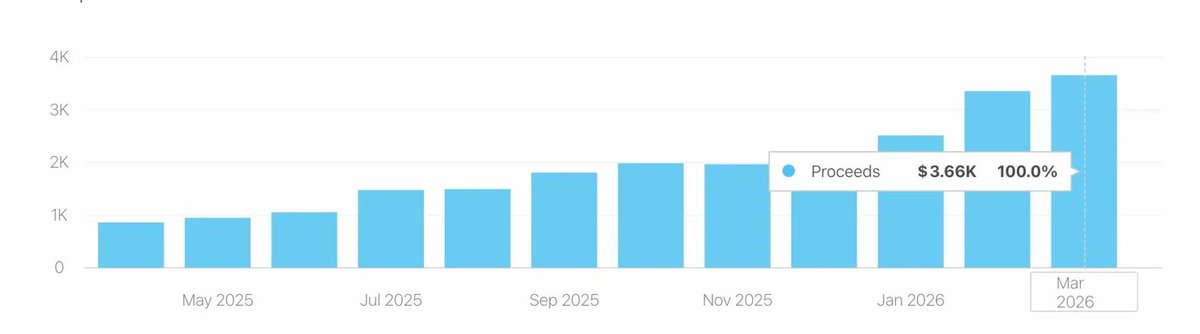
Ram Kumar@RamKuma05619911
February Update 📊 From $1.94k in Dec → $2.5k in Jan → $3.36k in Feb That's a 34% jump month over month and a new ATH 🚀 First time crossing $3k+ — what a way to start 2026 Hope it will continue 🤞 #indiedev #buildinpublic #AppDevelopment
English
@AMccormick459 that feeling when users actually show up and love what you built. nothing else at the early stage really compares
English
@maskaravivek @densumesh chromadb makes sense when it's pure embedding lookup and you want minimal setup. pgvector wins when you need relational joins alongside the vectors or you're already on postgres. for a doc search assistant that's mostly semantic retrieval, chromadb is a clean fit
English

@densumesh Very insightful, i am curious about why you chose ChromaDB vs some other options eg. pgVector?
English

@mihaibuilds yeah happy to compare notes. curious how you're handling the graph layer, adjacency in postgres or a separate structure alongside the vector columns?
English
@rivestack Thanks! PostgreSQL + pgvector keeps the stack simple — one database for vectors, full-text, and relational data. No need for a separate vector DB. Would be happy to compare schema approaches as the project progresses.
English
@AmadiSabit the accountability-through-pain approach to health apps is underrated. block the keyboard until the habit is done — brutal but effective. curious if you're storing the hydration log anywhere or just tracking in-session
English

SlapMac was the beginning. 2026 needs more discipline.
Building 'The Hydration Narc' with Claude Code > an app that literally makes my MacBook unusable if I don't drink enough water.
#BuildInPublic #UnhingedTech
English
@marvlearnstech depends what excites you. if you like building things quickly, JavaScript/Python are great starting points. if you want fundamentals first, try Python — readable syntax, huge community, and you can build anything from web apps to data pipelines. what draws you to tech?
English

As a beginner starting in tech, what do you suggest is best to start with?
#100daysofcode #buildinpublic
English
@MohamedMathari 2.7 MB for duplicate detection is impressive. what indexing approach are you using — perceptual hashing, or something more involved like LSH? curious how you handle near-duplicates vs exact ones
English

We built a photo duplicate detection tool that outperforms everything out there—at just 2.7 MB.
People keep asking how we pulled it off.
No magic. Just ruthless optimization, smart indexing, and cutting everything that didn’t matter.
Sometimes, less is more.
#buildinpublic
English
@asad2408dev langchain + langserve for REST endpoints is an underrated combo. clean abstraction. what does the poem quality look like for obscure topics, does it hallucinate a lot?
English

Built a LangChain-powered API with FastAPI and LangServe. POST a topic, get back an AI-generated poem. Clean, callable REST endpoints with minimal boilerplate.
Stack: Python, FastAPI, LangChain, LangServe, OpenAI
link: github.com/snackoverflowa…
#LangChain #FastAPI #BuildInPublic
English