Sabitlenmiş Tweet

IMLE Policy introduces a new way to train faster and more data efficient behavior cloning policies.
Will be presented at RSS2025!
imle-policy.github.io
🧵⬇️
English
Rob Lee
63 posts

@roblee_rl
trying to make robots useful @sydekickbot. RL, IL etc. prev woven by toyota, everyday robots, google x, phd in robot learning.


a good model trained on even a simple task with a tiny amount of data feels mesmerising, no matter how many times you see it.


Ran 21 km (13.1 miles) — and the motor was still cold. That’s the detail that matters. 🤖 Honor was the clear dark horse in this year’s robot half marathon. They swept 1st, 2nd, and 3rd, and also posted a strong top-6 finish overall. What stands out to me is that this was not just about bigger motors, or a gait tuned for long-distance running. They seem to have solved something more important — cooling. In a post-race interview, Honor engineers said the robot used liquid-cooling tech adapted from Honor smartphones, with cooling lines running deep into the motor system to carry heat away. Some reports added more detail: the setup used two high-speed micro pumps, with flow rates reaching up to 6 liters per minute, giving the system enough cooling capacity to handle sustained lower-joint motor load. That matters because once a robot starts overheating, output drops, stability goes with it, and the whole run can fall apart fast. And that’s exactly why this detail is interesting. Of course, that does not mean Honor has already surpassed teams like TienKung or Unitree across humanoid robotics as a whole. What it does suggest is that for the marathon task, they built a very strong system solution. And honestly, that alone is already a useful case for the industry. The bigger trend is moving fast. Last year, TienKung won in around 2 hours 40 minutes. This year, the winning time dropped to 50 minutes 26 seconds. Last year, most robots were still fully remote-controlled or only semi-autonomous. This year, around 40% were running with a much higher level of autonomy. So to me, the real signal is not just that robots got faster. It’s that the field is now moving past raw speed, and into the harder problems: autonomy, stability, and system reliability under load. If the pace of progress stays anywhere close to this, then next year’s race should be even more worth watching.



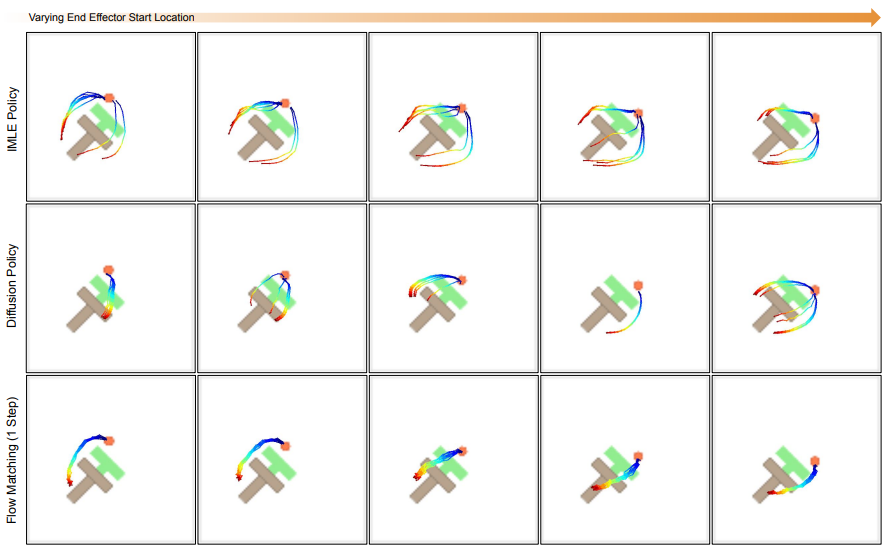

Generative models (diffusion/flow) are taking over robotics 🤖. But do we really need to model the full action distribution to control a robot? We suspected the success of Generative Control Policies (GCPs) might be "Much Ado About Noising." We rigorously tested the myths. 🧵👇



So excited to see that simple but elegant ACT structure has potential to scale up! Congrats @sundayrobotics team!

