@jay_k Any chance you solved a 60second timeout I’m bumping into for anything local? SW only here and anything above 60, gets error red out. Client side timeout it seems…
English
Victor Laynez
11.3K posts
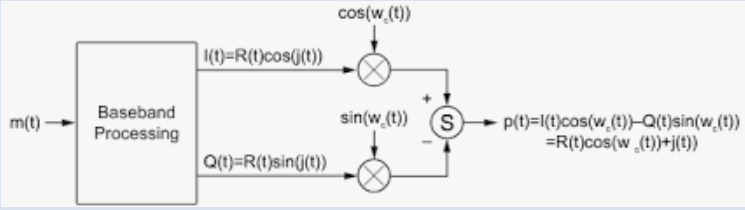
@roteno
Builder of RF embedded sensors & systems for work and play!


Available in four sizes: 🔵 31B Dense & 26B MoE: state-of-the-art performance for advanced local reasoning tasks – like custom coding assistants or analyzing scientific datasets. 🔵 E4B & E2B (Edge): built for mobile with real-time text, vision, and audio processing.