Sabitlenmiş Tweet
Rakesh🐊
10.2K posts


Rakesh🐊
@rozeappletree
❤️ FOSS 📊 Math 🧠 Intelligence
More → Katılım Ağustos 2019
192 Takip Edilen211 Takipçiler
Rakesh🐊 retweetledi

this OpenClaw bot finds warehouses with old roofs, renders solar panels on their actual building, and books the owner a call, all on autopilot...
here's how commercial roofers can close $2M+ deals before the solar tax break ends:
- scans thousands of commercial roofs via satellite
- scores each building by roof age & urgency
- pulls exact panel count from Google Solar API
- finds the real owner (not the property manager)
- calculates their federal credit to the dollar
- renders a video of panels materializing on their roof
- ships a personalized proposal
- fully automated end to end
every day that passes is money off the table.
reply "ROOF" + RT and i'll send you the full breakdown so you can build this too (must be following so i can DM)
English
Rakesh🐊 retweetledi

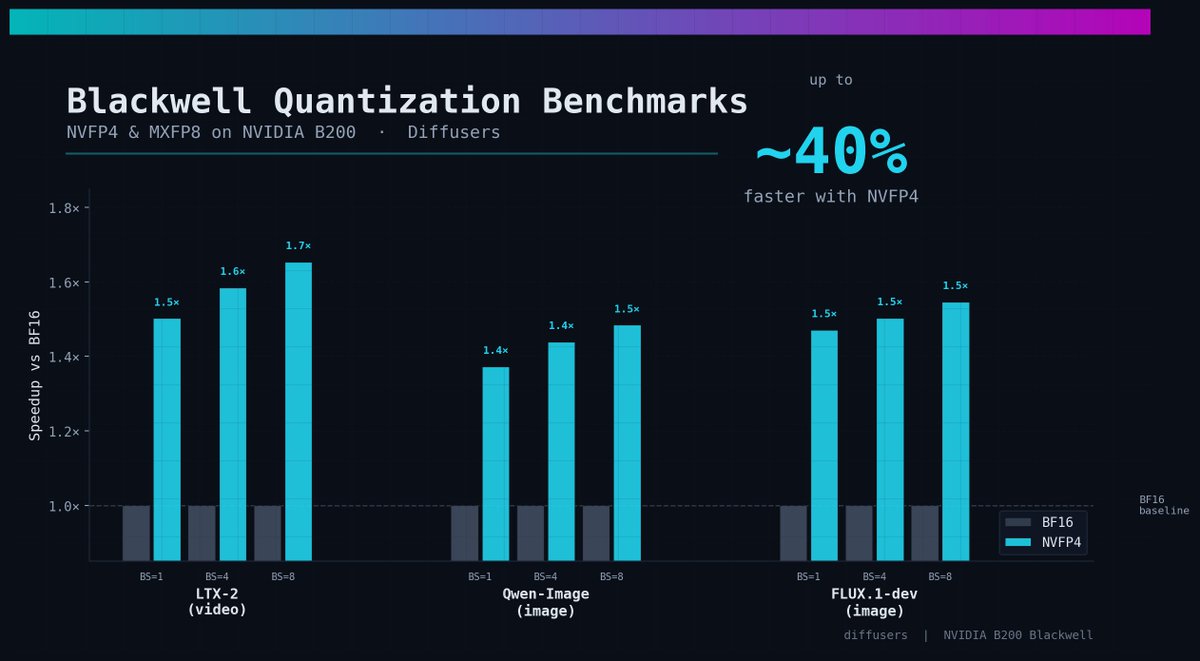
We've been studying what it takes to get NVFP4 & MXFP8 deliver good speedups on modern flow models for image & video gen. on B200 🕵️♂️
Today, I'm excited to share those findings!
Bringing some cool recipes through Diffusers and TorchAO with `torch.compile` 🔥
Hop in ⬇️
English
Rakesh🐊 retweetledi

Reminder that I wrote a little book about deep-learning, which is phone-formatted, entirely free, and nearing the 1M download:
fleuret.org/francois/lbdl.…
English
Rakesh🐊 retweetledi

We’re hiring AI/ML Research Interns (Remote) at @hydra_db
HydraDB is a US-based startup building a context and memory infrastructure for AI systems. Check out our website for more information: hydradb.com
If you’re interested in this role, please comment or DM your most impressive AI/ML research projects, along with a brief summary of each.
English
Rakesh🐊 retweetledi

Can you spot the underdog? 👀
keep an eye on llm-rl-environments-lil-course
English
Rakesh🐊 retweetledi

A full MIT course on visual autonomous navigation.
If you work on robotics, drones, or self-driving systems, this one is worth bookmarking‼️
MIT’s Visual Navigation for Autonomous Vehicles course covers the full perception-to-control stack, not just isolated algorithms.
What it focuses on:
• 2D and 3D vision for navigation
• Visual and visual-inertial odometry for state estimation
• Place recognition and SLAM for localization and mapping
• Trajectory optimization for motion planning
• Learning-based perception in geometric settings
All material is available publicly, including slides and notes.
📍vnav.mit.edu
If you know other solid resources on vision-based autonomy, feel free to share them.
——
Weekly robotics and AI insights.
Subscribe free: 22astronauts.com

English
Rakesh🐊 retweetledi


Rakesh🐊 retweetledi

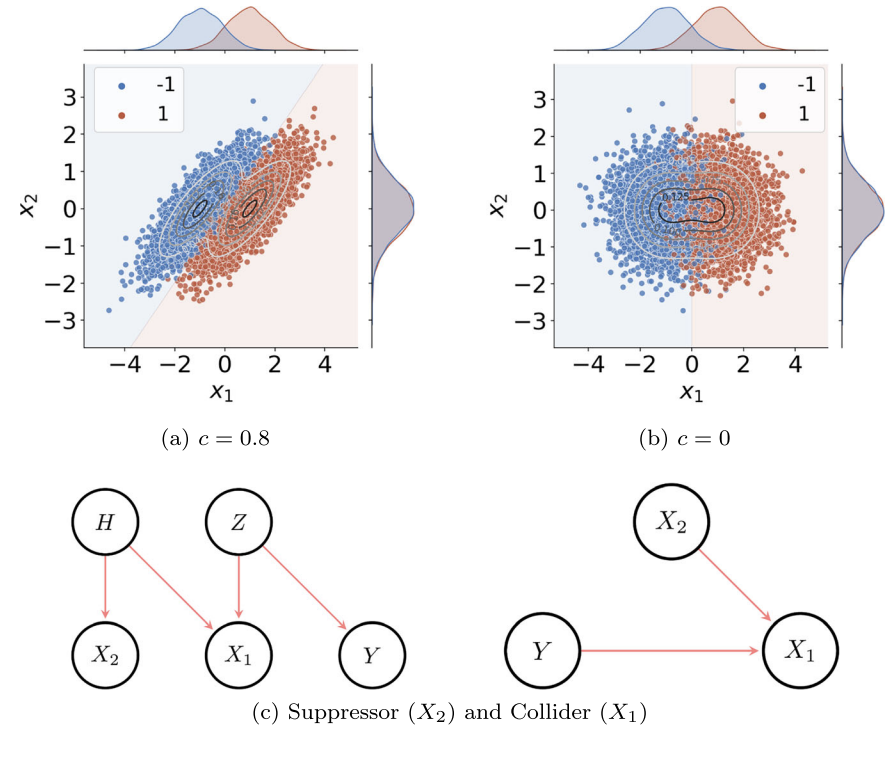
Explainable AI may be pointing at the wrong features, systematically.
When a machine learning model predicts that a patient is at high risk of a clinical event, and an explainability tool highlights "age" as a key driver, most practitioners will nod and move on. But what if age is not actually informative about the outcome — and the model is using it only to cancel out noise in a correlated variable that is informative? You would be reading a coherent, plausible explanation that is fundamentally wrong.
This is not an edge case. Stefan Haufe and coauthors show why it is the expected behavior of most popular explainable AI (XAI) methods — including SHAP, LIME, integrated gradients, LRP, counterfactual explanations, and permutation feature importance.
The core problem is what statisticians call suppressor variables: features that have no statistical association with the prediction target, yet improve model performance by removing irrelevant variance from features that are informative. A classic example — blood pressure depends on age, but age itself may not predict the disease. An optimal model may assign non-zero weight to age precisely to denoise the blood pressure signal. When XAI methods reduce to model weights, as the authors show analytically for linear models and empirically for non-linear ones, they will highlight the suppressor — not the informative feature.
The authors introduce the Statistical Association Property (SAP) as a necessary condition for any XAI method to be fit for purpose: if a method flags a feature as important, that feature must have a genuine statistical association with the target. Testing a broad range of popular methods against this criterion, they find that nearly all fail it in the presence of correlated features — true of virtually every real-world dataset.
The path forward is a shift from algorithm-first to problem-first development: formally define what an explanation should answer, derive correctness criteria, validate against synthetic ground-truth data, and only then assess robustness and usability.
This has direct consequences for applied R&D teams. Explainability tools are increasingly used to shortlist candidate molecules, flag confounded biomarkers, or justify regulatory submissions. If those tools are suppressor attributors, the features they highlight may carry no real biological or physical signal — meaning that follow-up experiments, costly and time-consuming, could be chasing artifacts. Demanding formal SAP compliance from XAI tools used in applied pipelines is not academic caution; it is a prerequisite for reproducible, trustworthy science-in-the-loop workflows.
Paper: Haufe et al., npj Artificial Intelligence (2026) — CC BY 4.0 | nature.com/articles/s4438…
English
Rakesh🐊 retweetledi

🚨 S3 is no longer just Object Storage.
Yesterday (April 7, 2026), AWS officially launched Amazon S3 Files.
This is the biggest update to S3 in 20 years.
It can:
→ Mount S3 buckets as native file systems
→ Provide sub-millisecond file access
→ Handle POSIX permissions (UID/GID) natively
→ Connect to Lambda, EC2, and EKS directly
→ Eliminate the need for s3fs or data staging
Your AI agents can read/write to S3 like a local disk, while your data team access the same objects via API.
DevOps just got a massive upgrade.
Source: share.google/ts8JORn6SURzwM…

English
Rakesh🐊 retweetledi

we did it 💪🤩
I finally wrapped up Inferencing and System Design, my Maven course, I was teaching, after an intense 1.5 months 🥳
Here's what we covered:
1️⃣ Inference Gateways and Endpoint Management, Steaming vs Non-Streaming Architectures
2️⃣ Inference Optimization and Profiling
3️⃣ How to build an inference engine from scratch
4️⃣ The internals of Inference engines - vLLM, SGLang etc - what happens when your system gets a request, how is tokenization done, how batching is done, how memory slots get assigned on GPUs. How prefill, decode, sampling, KV Caching, Paged Attention, Flash Attention, Flash Infer work.
5️⃣ Inference Optimization techniques (like speculative decoding, chunked prefill etc) both at prefill and decode stages for dense, sparse, and MoE models
6️⃣ Using performance engineering tools to log and visualize the end-to-end Inferencing Pipelines and cost modelling
7️⃣ How to decide which hardware to use and for which model and what will scale and where will different model/hardware combinations hit the bottleneck
8️⃣ Concurrency Management, Load Balancing and Parallelism (Data, Tensor, Model, Expert), Distributed Systems using Ray and Kubernetes - Fleets, Multi-Node and Multi-GPU inference scaling
9️⃣ How to develop end to end serving architectures with separation of concerns
🔟 Where to start debugging your pipelines so you know instintively what's a code problem versus a CPU problem versus GPU problem or Gateway Problem or your Serving Engine Problem
Many thanks to our compute sponsors @AnyscaleComputing, @LambdaAPI and @Modal for their support and student credits!
Also, I cover all these topics and more in my GPU Engineering book in far more detail 💀✍️ (early release this month, finally!)
Finally, as the student reviews are rolling in, and seeing my students rate the course 5️⃣/5️⃣ makes me feel like all my (almost millitary-men like) discipline over the past months has finally paid off.

English
Rakesh🐊 retweetledi

Today we release Boxer, a new lightweight approach that lifts open-world 2D bounding boxes to *metric* 3D: facebookresearch.github.io/boxer/
Here we show Boxer in action on an egocentric sequence captured from smart glasses:
English
Rakesh🐊 retweetledi

We hosted Prof. Alyosha Efros (UC Berkeley) at @SkildAI! He didn't believe that robots could actually cook eggs reliably. :)
Tested back-to-back 5times without fail! One batch of scrambled eggs every ~2.5mins nonstop. The same model assembles a GPU on a server rack too.
English
Rakesh🐊 retweetledi

This is Algebrica. A mathematical knowledge base I’ve been building for 2.5 years.
215+ entries, carefully written and structured.
400k+ views over this time. Not much in absolute terms, but meaningful to me.
No ads.
No courses to sell.
No gamification.
No distractions.
Just essential pages, aiming to explain mathematics as clearly as possible, for a university-level audience.
Built simply for the pleasure of sharing knowledge.
Content licensed under Creative Commons (BY-NC).
Best experienced on desktop.
If it helps even a few people understand something better, it’s worth it.

English
Rakesh🐊 retweetledi

pip install turboquant-gpu
5.02x KV cache compression for ANY GPU (RTX, H100, A100, B200)
- works over @huggingface transformers
- dead-simple API: compress + generate in 3 lines
- 3-bit Lloyd-Max fused KV compression (0.98 cosine similarity)
- outperforms MXFP4 (3.76x) and NVFP4 (3.56x) on compression
Ran Mistral-7B: 1,408 KB → 275 KB KV cache (5.02x)
Quickstart: github.com/DevTechJr/turb…
Written in cuTile (CUDA 12, 13) with PyTorch fallbacks

English
Rakesh🐊 retweetledi

MIT 18.065 Lecture 32 : CNN Rules.
CNN filtering, cyclic convolution, and Fourier are all tied together by the same linear algebra structure.
When convolution becomes cyclic, the matrix becomes circulant, and Fourier is the basis that diagonalizes it.
My note: ickma2311.github.io/Math/MIT18.065…

English
Rakesh🐊 retweetledi

Can AI truly empower robots to invent their own solutions?
George Jiayuan Gao, Tianyu Li, and colleagues from UPenn present VLMgineer.
This framework leverages Vision Language Models (VLMs) to brainstorm initial tool designs and action plans. It then refines these ideas using evolutionary search in simulation, optimizing both the tool's geometry and how the robot uses it.
VLMgineer consistently outperforms existing human-crafted tools and VLM-generated designs from human specifications across diverse, challenging everyday manipulation tasks, transforming complex robotics problems into straightforward executions.
VLMgineer: Vision Language Models as Robotic Toolsmiths
Project: vlmgineer.github.io
Paper: arxiv.org/abs/2507.12644
Our report: mp.weixin.qq.com/s/FXdeQhAeq-ne…
📬 #PapersAccepted by Jiqizhixin

English
Rakesh🐊 retweetledi
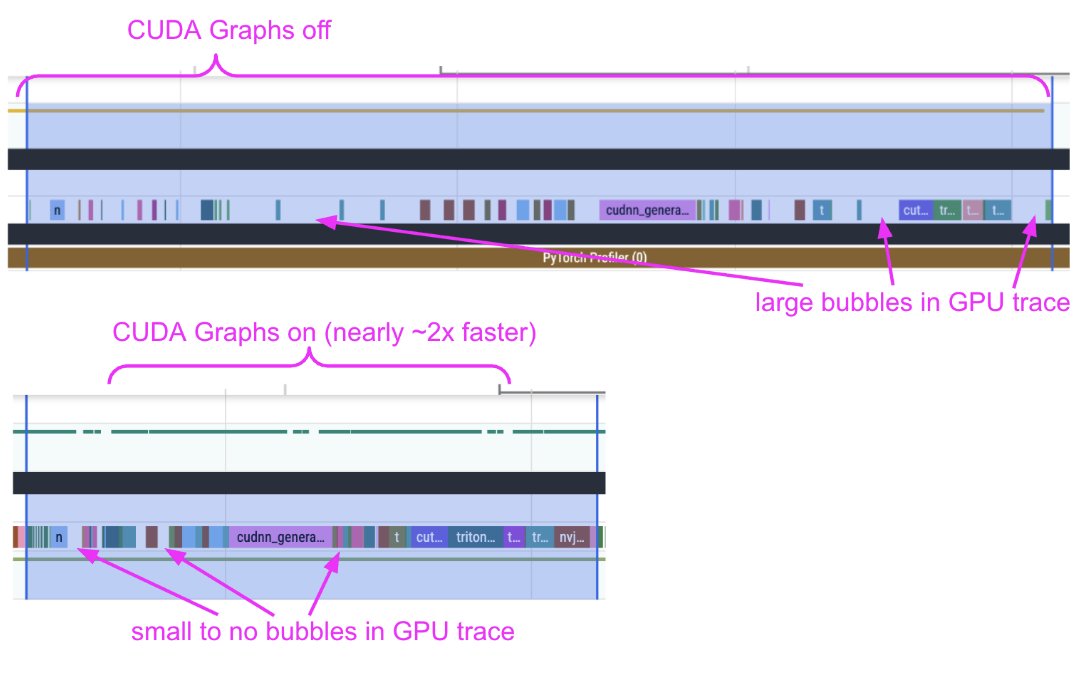
We're shipping an elaborate guide on how to profile diffusion pipelines in Diffusers to set them up for success with `torch.compile` 🔥
We devised a workflow with Claude & it turned out to be quite effective. It served its purpose well. With the help of the trace alone, we uncovered:
1. CPU <-> GPU syncs
2. CPU overheads
3. Kernel launch delays
When we provided the profile trace and our observations from the trace to Claude, and helped us get rid of the issues, it did well.
However, it did so iteratively. The process was intellectually fun and engaging!
English
Rakesh🐊 retweetledi

From parked cars to an Airbus A321 at cruising altitude. Same laptop. MLX & Torch.
SAM3 segments every vehicle on the ground. Yes, just cars.
RF-DETR spots the Austrian Airlines jet overhead. Real-time detection.
Two open-source models running locally. No cloud. No API.
English
Rakesh🐊 retweetledi

EUPE: Efficient Universal Perception Encoder👋
Looking for the most powerful small image models today?
Guess what: researchers at @AIatMeta cooked again!🍳
This time around, not some large vision encoder. Instead, a set of lightweight and efficient ones, both ViTs and ConvNeXts, all under 100M. The smallest is a ViT-Tiny at just 6M params!
But hear me out: this is the COOLEST thing ever...

English
Rakesh🐊 retweetledi

We killed RAG, We killed Sandboxes, We gave our Assistant a virtual filesystem and dropped latency to 10ms
- Our Assistant was a glorified search bar.
- The moment it had to cross reference multiple searches it fell apart
- Sandboxes couldn't work
- We went virtual
Traditional RAG only sends relevant chunks of a document. Never a full doc. Answers in docs span multiple pages: eg
- Product Overview page
- Configuration page
- API reference page.
With rag the model can only see pieces and chunks of a page but never the full doc a user sees. This gap lead to many responses feeling half baked
We first tried putting the agent in a sandbox and found responses to be better, however sandbox startup time was ~46 seconds and would cost us at least $70k/year. Sandboxes didn't work.
We built a virtual filesystem that translates UNIX commands into queries against our database. We call it Chroma FS. Output quality remained the same while completely removing a sandbox.
What we realized was the agent doesn't need a real sandbox. It just needs to think its in a sandbox.
ChromaFs now powers the docs assistant across 30,000+ conversations a day across all our users.
No containers. No VMs. No session cleanup. Just Chroma queries behind a bash interface.
Full technical breakdown in the blog 👇
Dens Sumesh@densumesh
English