
Ryan Tabrizi
80 posts

Ryan Tabrizi
@ryan_tabrizi
phding @columbia
a pale blue dot Katılım Ekim 2018
843 Takip Edilen321 Takipçiler
Ryan Tabrizi retweetledi

Gave my PhD dissertation talk on Friday!
It's been an incredible journey made possible by the best advisor who believed in me and gave me the freedom and support to explore. Thank you @pabbeel!
And thank you to everyone who came to support and share this milestone with me 🙏

English
Ryan Tabrizi retweetledi

Really excited to release this! Vista4D lets you reshoot a video by not just moving the camera 🎥 but also manipulating the scene 🌄, all grounded in a 4D point cloud ☁️ and designed in a friendly UI 🖌
Check out our project! eyeline-labs.github.io/Vista4D/
Ning Yu@realNingYu
📢 Eyeline Labs and Netflix’s latest research, 🎥Vista4D🎥, accepted at #CVPR2026 as a 🌟Highlight🌟 paper, advances virtual cinematography and scene control with video generation. 🎥 Vista4D synthesizes the dynamic scene represented by an input video from novel camera trajectories and viewpoints by grounding video generation in a 4D point cloud. Our method maintains geometric and physical plausibility under imprecise 4D reconstruction of real-world videos. 🎥 Vista4D unlocks video reshooting beyond camera control. By directly editing the 4D point cloud, our method preserves scene information from casual captures and enables 4D scene editing and recomposition. This work is part of the ongoing research and development at @eyelinestudios and @netflix, and we look forward to seeing its techniques and workflows adopted in future productions. ✊ Kudos to the team: @kuanhenglin, Zhizheng Liu, @pablosalamancal, @yash2kant, @RyanBurgert, @Yuancheng_Xu0, @Koichi_N_, Yiwei Zhao, @zhoubolei, @micahgoldblum, @debfx, @realNingYu 📰 Paper: arxiv.org/pdf/2604.21915 🌐 Project: eyeline-labs.github.io/Vista4D/ ⌨️ Code: github.com/Eyeline-Labs/V…
English
Ryan Tabrizi retweetledi

📢 Eyeline Labs and Netflix’s latest research, 🎥Vista4D🎥, accepted at #CVPR2026 as a 🌟Highlight🌟 paper, advances virtual cinematography and scene control with video generation.
🎥 Vista4D synthesizes the dynamic scene represented by an input video from novel camera trajectories and viewpoints by grounding video generation in a 4D point cloud. Our method maintains geometric and physical plausibility under imprecise 4D reconstruction of real-world videos.
🎥 Vista4D unlocks video reshooting beyond camera control. By directly editing the 4D point cloud, our method preserves scene information from casual captures and enables 4D scene editing and recomposition.
This work is part of the ongoing research and development at @eyelinestudios and @netflix, and we look forward to seeing its techniques and workflows adopted in future productions.
✊ Kudos to the team: @kuanhenglin, Zhizheng Liu, @pablosalamancal, @yash2kant, @RyanBurgert, @Yuancheng_Xu0, @Koichi_N_, Yiwei Zhao, @zhoubolei, @micahgoldblum, @debfx, @realNingYu
📰 Paper: arxiv.org/pdf/2604.21915
🌐 Project: eyeline-labs.github.io/Vista4D/
⌨️ Code: github.com/Eyeline-Labs/V…
English
Ryan Tabrizi retweetledi

We developed a simple, sample-efficient online RL technique for post-training image generation models. We see it as a possible steerable alternative to CFG, driven by any scalar reward, including human preference.
English
Ryan Tabrizi retweetledi

New paper: What Do LLMs Know About Opinions?
If we want LLMs to reflect diverse human views or simulate human responses well, we need to understand what they know about human opinions.
Current evaluations mostly rely on next-token probs, but what if that misses a lot of what the model actually knows? 💡
In our ICLR 2026 paper, we find that models know much more about human opinions than their outputs reveal.

English
Ryan Tabrizi retweetledi

excited to share some recent work!
tldr; models trained on multi-view sensory data are the first to match human-level 3D shape perception—all zero shot, with no training on experimental data/images
project page: tzler.github.io/human_multiview
1/🧠
English
Ryan Tabrizi retweetledi

✨Thinking with Blender~
Meet VIGA: a multimodal agent that autonomously codes 3D/4D blender scenes from any image, with no human, no training!
@berkeley_ai #LLMs #Blender #Agent 🧵1/6
English
Ryan Tabrizi retweetledi

New work!
What if we used sparse autoencoders to analyze data, not models—where SAE latents act as a large set of data labels 🏷️?
We find that SAEs beat baselines on 4 data analysis tasks and uncover surprising, qualitative insights about models (e.g. Grok-4, OpenAI) from data.
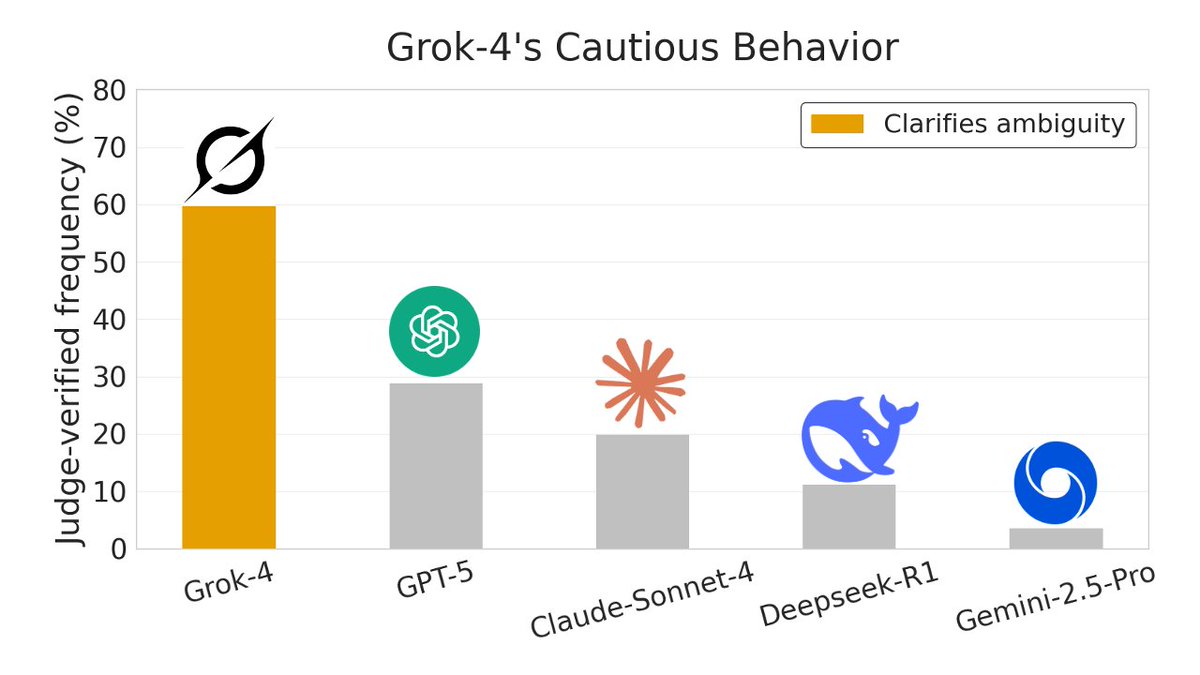
English
Ryan Tabrizi retweetledi

For a long time, Yann LeCun and others believed in gradient-based planning, but it didn’t work very well … until now. Here’s how we did it using incredibly simple techniques. But first, an introduction to gradient-based planning: 🧵1/11
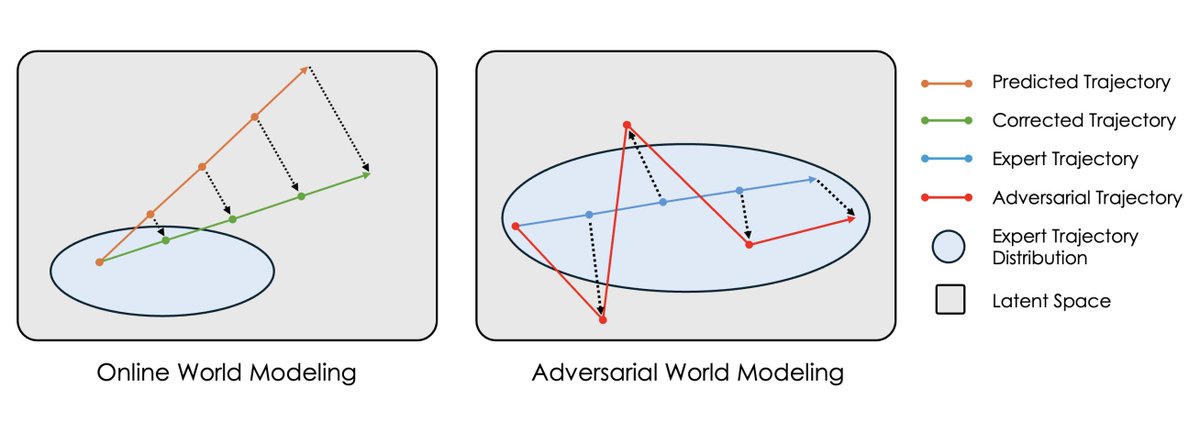
English
Ryan Tabrizi retweetledi
starting fall 2026 i'll be an assistant professor at @Penn 🥳
my lab will develop scalable models/theories of human behavior, focused on memory and perception
currently recruiting PhD students in psychology, neuroscience, & computer science!
reach out if you're interested😊


English
Ryan Tabrizi retweetledi

(1/7) Glad to see that people are following up on our work studying topological properties of modern neural network architectures. It was cool to see that widely used neural architectures can almost always generate any output given appropriate inputs, a.k.a. are surjective.

GLADIA Research Lab@GladiaLab
LLMs are injective and invertible. In our new paper, we show that different prompts always map to different embeddings, and this property can be used to recover input tokens from individual embeddings in latent space. (1/6)
English
Ryan Tabrizi retweetledi

Everyone says they want general-purpose robots.
We actually mean it — and we’ll make it weird, creative, and fun along the way 😎
Recruiting PhD students to work on Computer Vision and Robotics @umdcs for Fall 2026 in the beautiful city of Washington DC!



English
Ryan Tabrizi retweetledi

Diffusion models operate step-by-step, hence they are serial models right?
However, that doesn't sit well because we have been seeing that diffusion models don't scale well with "steps".
In this thread: Diffusion models are not truly serial models.

English
Ryan Tabrizi retweetledi

VideoMimic team won Best Student Award in CoRL 2025!!!
I am so proud of our team:)
@arthurallshire @junyi42 @davidrmcall @AnthonyZhang123 @ChungMinKim
English
Ryan Tabrizi retweetledi

Congratulations to the videomimic team for winning the best student paper award at CoRL 2025 🥹🎉 Grateful to the CoRL community for the recognition!

Arthur Allshire@arthurallshire
our new system trains humanoid robots using data from cell phone videos, enabling skills such as climbing stairs and sitting on chairs in a single policy (w/ @redstone_hong @junyi42 @davidrmcall)
English
Ryan Tabrizi retweetledi
Best student paper at CoRL 🎉
Not pictured but not possible without @junyi42 @AnthonyZhang123

Arthur Allshire@arthurallshire
our new system trains humanoid robots using data from cell phone videos, enabling skills such as climbing stairs and sitting on chairs in a single policy (w/ @redstone_hong @junyi42 @davidrmcall)
English
Ryan Tabrizi retweetledi
I'm super excited to announce mjlab today!
mjlab = Isaac Lab's APIs + best-in-class MuJoCo physics + massively parallel GPU acceleration
Built directly on MuJoCo Warp with the abstractions you love.
English
Ryan Tabrizi retweetledi

Should robots have eyeballs? Human eyes move constantly and use variable resolution to actively gather visual details. In EyeRobot (eyerobot.net) we train a robot eyeball entirely with RL: eye movements emerge from experience driven by task-driven rewards.
English
Ryan Tabrizi retweetledi

I'm so proud to have worked on making this model and product a reality over the past 14 months.
Give Reve a try... and watch yourself become impressed by your own creativity
Reve@reve
Reimagine reality. reve.com
English