
Sabitlenmiş Tweet

New work!
What if we used sparse autoencoders to analyze data, not models—where SAE latents act as a large set of data labels 🏷️?
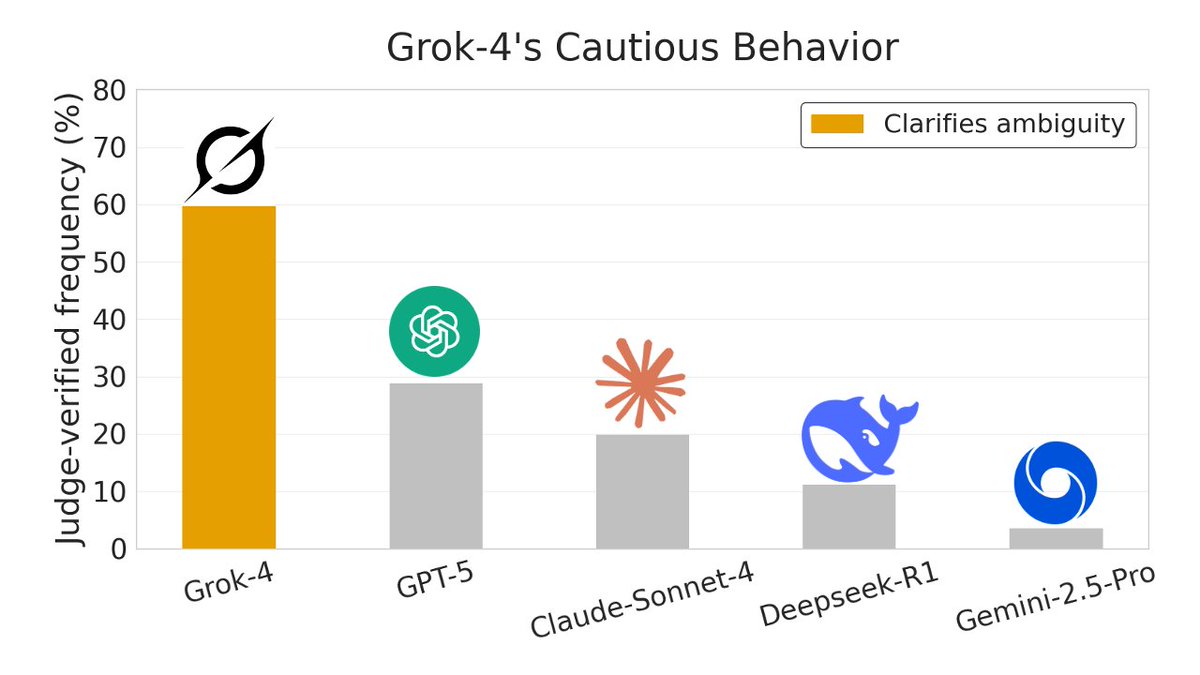
We find that SAEs beat baselines on 4 data analysis tasks and uncover surprising, qualitative insights about models (e.g. Grok-4, OpenAI) from data.
English















