We just released code and model! Go check it out!
Code: github.com/nv-dvl/vgg-ttt
Model: huggingface.co/nvidia/vgg-ttt
Sven Elflein@s_elflein
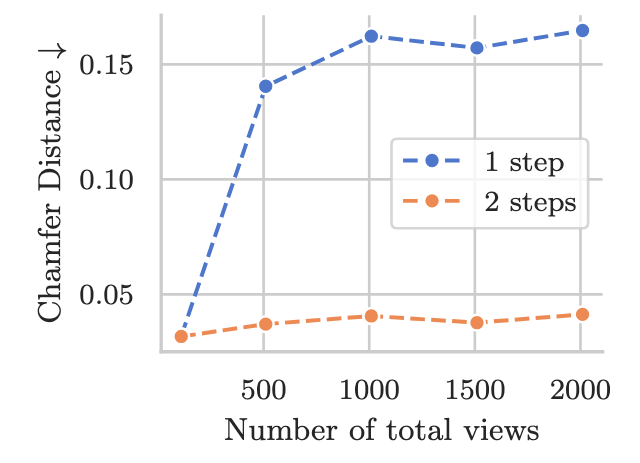
🚀 Exciting news! We’re introducing VGG-T³: a scalable model for offline feed-forward 3D reconstruction that finally tackles the "quadratic bottleneck." Ever wanted to have VGGT reconstruct a 1,000-image scene in seconds instead of 10 minutes and use it for visual localization?
English