
Cristián Llull
29 posts

Cristián Llull
@cllullt
PhD student in Computer Science - U. of Chile Passionate to learn the workings of the world and interact with the environment through computers
Katılım Kasım 2022
307 Takip Edilen13 Takipçiler

CAPTCHA for 3D vision people
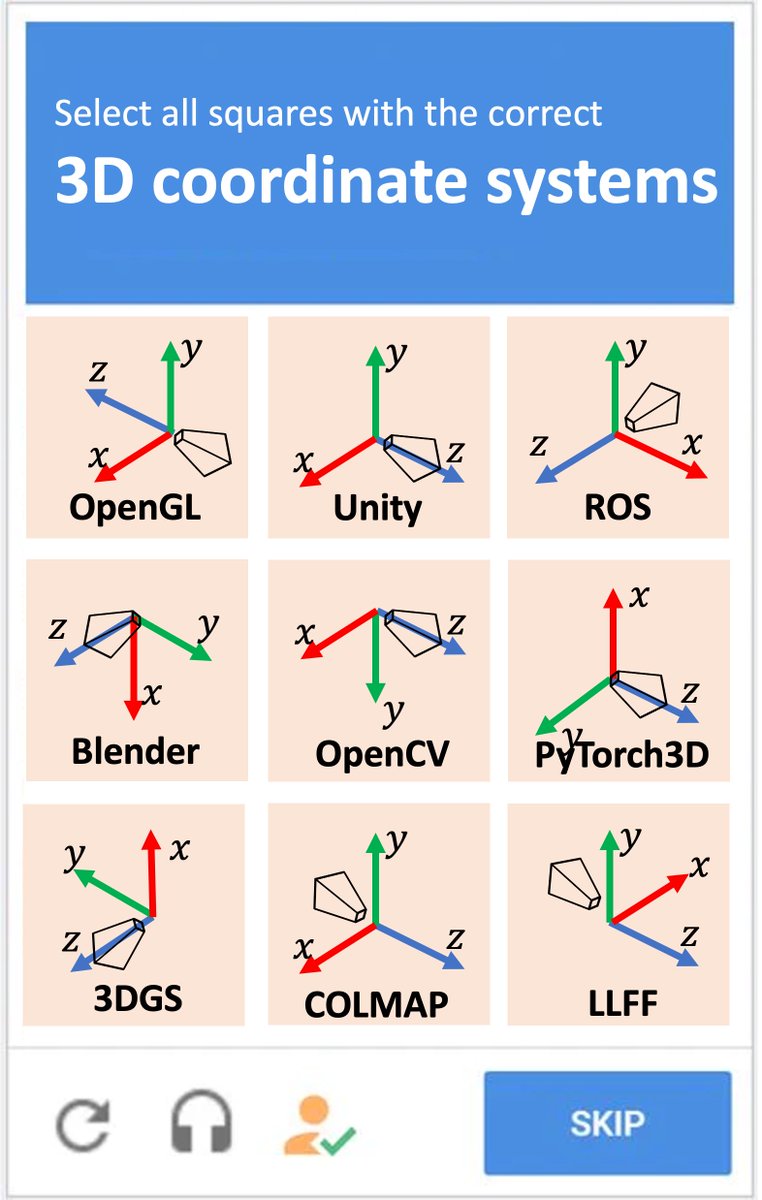
Ryan Schmidt@rms80
wait wait wait. So a new kind of 3D representation (gaussian splats) was invented and they decided to use Y-DOWN as the standard up-direction ?? In 2023 ?!?!!! Need to have some words w/ my old friends at INRIA...and I guess we need a new chart...
English
Cristián Llull retweetledi

VoroUDF: Meshing Unsigned Distance Fields with Voronoi Optimization
Ningna Wang, Zilong Wang, Xiana Carrera, Xiaohu Guo, Silvia Sellán
arxiv.org/abs/2602.02907 [𝚌𝚜.𝙶𝚁]

Filipino
Great news!
Really excited to continue the research and academic travel :)
---
Excelente noticia!
Agradecido del apoyo recibido. Con todo el ánimo de seguir dando la mejor.
---
Els meus més sincers agraïments als qui m'han ajudat en aquest trajecte. Cap amunt!
Shape Vision Lab UChile@ShapeVisionLab
Congratulations to our student Cristián Llull for successfully passing his doctoral qualification exam! This achievement marks an important first step on his path earning a Ph.D. We are confident he will continue to demonstrate dedication, research excellence and academic rigor.
Català
Cristián Llull retweetledi

Congratulations to our student Cristián Llull for successfully passing his doctoral qualification exam!
This achievement marks an important first step on his path earning a Ph.D. We are confident he will continue to demonstrate dedication, research excellence and academic rigor.
English
Cristián Llull retweetledi

Quite literally all of 3D vision
This includes VGGT, Dust3r and friends which are trained on COLMAP-generated data
Also gaussian splatting and NERFs in most cases use COLMAP-generated poses

English

🚀 Exciting news! We’re introducing VGG-T³: a scalable model for offline feed-forward 3D reconstruction that finally tackles the "quadratic bottleneck."
Ever wanted to have VGGT reconstruct a 1,000-image scene in seconds instead of 10 minutes and use it for visual localization?
GIF
English
@s_elflein Awesome project!
We are hosting the SHREC26 Track on 3D Reconstruction and your work could be a valuable addition to the track.
Challenge: reconstruct objects from 2D images. After, we'll evaluate their quality using a novel feature-aware metric. See: shapevision.dcc.uchile.cl/cllull-shrec20…
English
@ruilong_li Awesome!
We are hosting the SHREC2026 Track on 3D Reconstruction and this work seems to be a valuable addition to participate.
Challenge: reconstruct the objects from 2D images. We'll evaluate their quality with a novel metric.
See more: shapevision.dcc.uchile.cl/cllull-shrec20…
English

With this you can run reconstruction on 1000 images with 1x GPUs in 1 minute🔥.
Also this allows for arbitrary tradeoff between runtime and VRAM so you never have to suffer with OOM with even more images. Or throw in more GPUs and further scaling/speed up!
Sven Elflein@s_elflein
🚀 Exciting news! We’re introducing VGG-T³: a scalable model for offline feed-forward 3D reconstruction that finally tackles the "quadratic bottleneck." Ever wanted to have VGGT reconstruct a 1,000-image scene in seconds instead of 10 minutes and use it for visual localization?
English
SECOND CALL: SHREC'26 Challenge on 3D Reconstruction
Our dataset features intricate geometries, ideal for benchmarking of high-frequency detail recovery.
All participants will co-author a joint paper submitted to Computers & Graphics.
Track Details shapevision.dcc.uchile.cl/cllull-shrec20…
Cristián Llull@cllullt
SHREC 2026: reconstruct high-frequency geometry from 90 views (COLMAP poses). Dataset out now. Registration → cllull@dcc.uchile.cl. Submissions due Apr 3, 2026. Details: shapevision.dcc.uchile.cl/cllull-shrec20… #ComputerVision #3DReconstruction #Photogrammetry
English
@rsasaki0109 Great!
We are hosting the SHREC2026 Track on 3D Reconstruction and this work seems to be a valuable addition to participate.
The challenge is to reconstruct the objects from 2D images. We'll evaluate their quality with a novel metric.
See more shapevision.dcc.uchile.cl/cllull-shrec20…
English
Cristián Llull retweetledi

[SIGGRAPH Asia 2025 - TOG] Official implementation of MILo: Mesh-In-the-Loop Gaussian Splatting for Detailed and Efficient Surface Reconstruction
github.com/Anttwo/MILo
Our method introduces a novel differentiable mesh extraction framework that operates during the optimization of 3D Gaussian Splatting representations. At every training iteration, we differentiably extract a mesh—including both vertex locations and connectivity—only from Gaussian parameters. This enables gradient flow from the mesh to Gaussians, allowing us to promote bidirectional consistency between volumetric (Gaussians) and surface (extracted mesh) representations. This approach guides Gaussians toward configurations better suited for surface reconstruction, resulting in higher quality meshes with significantly fewer vertices. Our framework can be plugged into any Gaussian splatting representation, increasing performance while generating an order of magnitude fewer mesh vertices. MILo makes the reconstructions more practical for downstream applications like physics simulations and animation.

English
@Almorgand @jingwu23 @ziruiwang_ @irolaina @UniofOxford Very interesting!
I think you would be a great fit for the SHREC 2026 Challenge on 3D reconstruction we are hosting.
I would like to invite you or anyone in your group to participate reconstructing the synthetic objects of our dataset:
See description shapevision.dcc.uchile.cl/cllull-shrec20…
English

@jingwu23 @ziruiwang_ @IroLaina Victor Adrian Prisacariu
@UniofOxford
Project page: jingwu2121.github.io/reflect3r/
Paper: arxiv.org/abs/2509.20607
Source code: github.com/jingwu2121/ref…
English
"Reflect3r: Single-View 3D Stereo Reconstruction Aided by Mirror Reflections"
TL;DR: uses mirror reflections as auxiliary virtual views to generate stereo cues and improve 3D reconstruction from a single image.
English
@taiyasaki @rvandeghen @janheld14 Awesome project!
I'm hosting a SHREC26 Challenge on 3D Reconstruction.
Would you like to submit your results, or anyone you work with, reconstructing the objects on this dataset? shapevision.dcc.uchile.cl/cllull-shrec20…
Any question, feel free to contact me at cllull@dcc.uchile.cl
English

📢📢📢 new paper alert: Mesh Splatting
meshsplatting.github.io
Yet another step closer to classical computer graphics for differentiable rendering. No need to write custom shaders… just a classical mesh renderer!
Great job @janheld14
Was a pleasure to have you at SFU
Jan Held@janheld14
🚀 I’m excited to share my final work as a PhD student: 𝙈𝙚𝙨𝙝𝙎𝙥𝙡𝙖𝙩𝙩𝙞𝙣𝙜: 𝘿𝙞𝙛𝙛𝙚𝙧𝙚𝙣𝙩𝙞𝙖𝙗𝙡𝙚 𝙍𝙚𝙣𝙙𝙚𝙧𝙞𝙣𝙜 𝙬𝙞𝙩𝙝 𝙊𝙥𝙖𝙦𝙪𝙚 𝙈𝙚𝙨𝙝𝙚𝙨 - Arxiv: arxiv.org/abs/2512.06818 - Code: github.com/meshsplatting/… - Project page: meshsplatting.github.io
English
SHREC 2026: reconstruct high-frequency geometry from 90 views (COLMAP poses). Dataset out now. Registration → cllull@dcc.uchile.cl. Submissions due Apr 3, 2026. Details: shapevision.dcc.uchile.cl/cllull-shrec20… #ComputerVision #3DReconstruction #Photogrammetry
English
Cristián Llull retweetledi

My brain broke when I read this paper.
A tiny 7 Million parameter model just beat DeepSeek-R1, Gemini 2.5 pro, and o3-mini at reasoning on both ARG-AGI 1 and ARC-AGI 2.
It's called Tiny Recursive Model (TRM) from Samsung.
How can a model 10,000x smaller be smarter?
Here's how it works:
1. Draft an Initial Answer: Unlike an LLM that writes word-by-word, TRM first generates a quick, complete "draft" of the solution. Think of this as its first rough guess.
2. Create a "Scratchpad": It then creates a separate space for its internal thoughts, a latent reasoning "scratchpad." This is where the real magic happens.
3. Intensely Self-Critique: The model enters an intense inner loop. It compares its draft answer to the original problem and refines its reasoning on the scratchpad over and over (6 times in a row), asking itself, "Does my logic hold up? Where are the errors?"
4. Revise the Answer: After this focused "thinking," it uses the improved logic from its scratchpad to create a brand new, much better draft of the final answer.
5. Repeat until Confident: The entire process, draft, think, revise, is repeated up to 16 times. Each cycle pushes the model closer to a correct, logically sound solution.
Why this matters:
Business Leaders: This is what algorithmic advantage looks like. While competitors are paying massive inference costs for brute-force scale, a smarter, more efficient model can deliver superior performance for a tiny fraction of the cost.
Researchers: This is a major validation for neuro-symbolic ideas. The model's ability to recursively "think" before "acting" demonstrates that architecture, not just scale, can be a primary driver of reasoning ability.
Practitioners: SOTA reasoning is no longer gated behind billion-dollar GPU clusters. This paper provides a highly efficient, parameter-light blueprint for building specialized reasoners that can run anywhere.
This isn't just scaling down; it's a completely different, more deliberate way of solving problems.

English
Cristián Llull retweetledi

insane
Over the Reality 🌐@OVRtheReality
Excited to share this demo from Over the Reality! Watch our Unitree Go2 robodog navigating our office while reconstructing the 3D space in real-time using the VGGT-based foundation vision model. This is a prime example of machine perception in action, turning raw RGB camera feeds into rich, detailed 3D maps! The robodog's RGB cam generates a dense, textured 3D reconstruction via VGGT from a few photograms, capturing nuances like object shapes and surfaces with impressive fidelity (main view). Compare that to the standard LiDAR system (top right), it's sparser, more point-cloud focused, lacking the visual richness. Vision models are closing the gap fast! What's powering this? VGGT, a cutting-edge foundation model for 3D perception, trained on datasets orders of magnitude smaller than our massive OVER 3D maps dataset. docs.google.com/spreadsheets/d… Imagine the leap when we apply OVER's scale to VGGT-like transformer based architectures, denser reconstructions, better generalization, revolutionary for robotics, machine perception & AR! Stay tuned for more breakthroughs at the intersection of AI, robotics, and DePIN. We're building the future of Physical AI and Spatial Computing at @OVRtheReality What do you think, ready for robodogs in your world? Drop your thoughts! 🤖🌐
Türkçe
Cristián Llull retweetledi

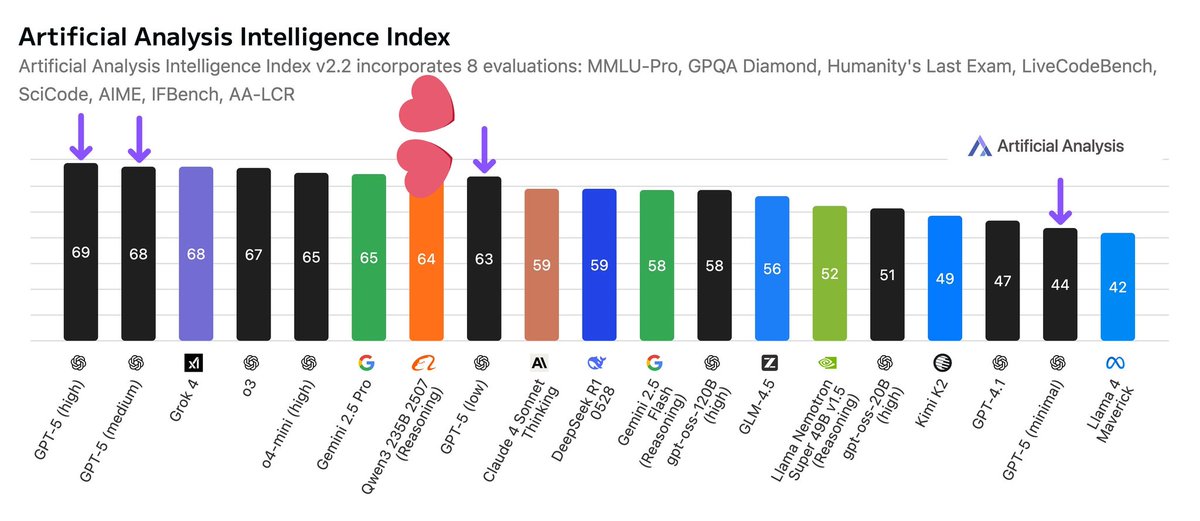
@Alibaba_Qwen I keep looking at this and wonder how selfless Qwen has been, open Sourcing everything. Everyone is guilty if not supporting Qwen. SOTA open source model every single time!.
May all the people behind Qwen live for many years.
English
Fascinating analysis.
Pi-sica en Movimiento caldostrong.com/2025/08/pi-sic… via @caldostrong
HT
Cristián Llull retweetledi

Cristián Llull retweetledi

Milei atacó a los científicos y ellos prepararon éste video para domarlo, digo o sea digamos educarlo. Mentendesss???
#SoberaniaCientifica
#SiALaEducacionPublica
#ElPeorGobiernoDeLaHistoria
#LosLapicesSiguenEscribiendo
Español