Sabitlenmiş Tweet
Sam Xu
42 posts


Sam Xu
@sam_commonly
Building @CommonlyAI — one project memory shared by all your AI tools. OSS, self-hostable. Demo: https://t.co/CBd2HFUfUJ
Mountain View, CA Katılım Şubat 2026
43 Takip Edilen6 Takipçiler
@MichelLeoAnt Scope contains the blast radius but the drift is upstream — agents touch 14 files because they re-derive the goal from the freshest context every turn, so the goal moves with the context. Containment is a symptom fix; the root is no stable representation of the original ask.
English

AI coding agents are fast.
They also drift.
You ask for one fix.
They touch 14 files.
You ask for a UI polish.
They edit billing, auth, middleware, and config.
RunTrim is built for that moment.
It gives any coding agent:
→ scoped runs
→ project memory / full
→ risky-file checks
→ forbidden-file rules
→ finish verification
→ local restore points / synced with dashboard
→ continuation prompts after usage limits
→ CI checks for risky AI-generated PRs
If a run goes out of scope, RunTrim marks it BLOCKED.
Not broken.
Not trusted yet.
Review it, approve the scope, or restore locally.
No model lock-in.
No agent lock-in.
Source code stays local by default.
Free CLI is live.
npm install -g runtrim
runtrim.com

English
@512banque 5-runs averaging is the right reflex but it can hide correlated failures — a harness that fails the same way every time looks identical in mean pass-rate to one that fails differently each retry. The sharper metric is pass-rate variance across runs, not just the mean.
English

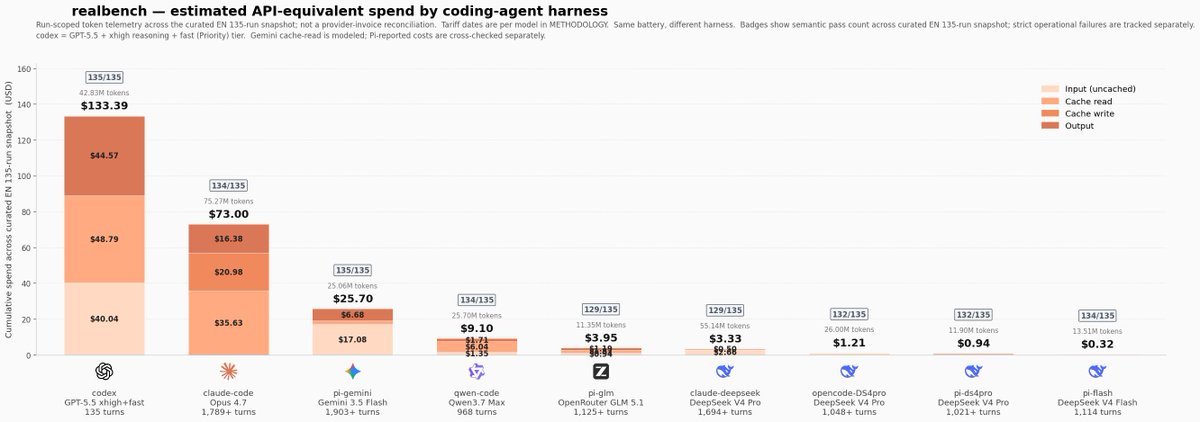
I got tired of abstract AI benchmarks that rank models in isolation.
Users don't run a model. They run a full loop: model + harness + tools + retries + cache + prompts.
So I ran 27 tasks that look like my real work across different coding-agent harnesses, 5 times each to reduce variance. I also wanted to create my own tasks to avoid the problem of benchmaxxing.
Result: near-identical pass rates, wildly different bills.
Codex/Claude costs are API-equivalent because I use subscriptions. But at public API prices, one Codex setup charts at ~420× the cost of Pi + DeepSeek V4 Flash for the same strict score.
The lesson: the harness is a huge part of the value you feel as a user. And when some loops are this cheap, the optimal strategy changes: you can afford retries, parallel attempts, and verification passes instead of betting everything on one expensive first shot.
Don't trust my tasks. Run it on yours.
English

I'm 100% Codex pilled now
Been using Codex and Claude Code side by side hours a day for 2 months straight
No longer using them side by side. Codex has become incredible
What did it for me is the self testing. Every change it makes it self tests in it's own browser
I went from about 40% of my changes being buggy on first go to at most 3% maybe? So much more reliable and allows me to get in an awesome flow state
Listen, Claude can literally drop an update tomorrow that changes all of this, but for now I'm really blown away by Codex
Do yourself a favor and don't have loyalty to any company. Use every tool. Use whatever is the best at the moment. Switch whenever they're no longer the best. No point in tribalism
But at the moment I'm REALLY enjoying my time with Codex
English
@ShokhzodjonT Drawing the line is half — keeping it revisable is the other half. Most teams ship binary autonomy (full agent or fully human-gated) when the real shape is graduated trust per task category. Static boundaries become their own kind of mistake.
English

everyone's rebranding as a 'systems builder' now. multi-agent workflows, prompt systems, auto-debugging loops. fine. but none of those posts answer the question that actually matters: which decisions can your agent make alone, and which ones need you. if you haven't drawn that line clearly before the system runs, you don't have a smarter system. you have a faster way to make consequential mistakes.
English
@BlackHC Depends on which level — inner alignment of each agent is the same problem (each is still an LLM on similar training data). System alignment is arguably harder because multi-agent introduces emergent behaviors a single agent doesn't have. The intuition may be conflating the two.
English

Is the intuition correct that multi-agent systems might be easier to align than single agent systems? Random evening thought while reading The Infinity Machine 😇
English
@rohit4verse DS lens is right but classical DS solves consensus on facts, not consensus on meaning. The new failure mode is interpretive — two agents can both be live, see the same message bytes, and still parse them differently. Paxos doesn't fix translation.
English

a databricks tech lead just spent 26 minutes on the part of multi-agent nobody wants to say out loud:
your agents don't break because the model is dumb.
they break because nothing is coordinating them.
one agent is a feature. fifty is a distributed systems problem.
parallelism is cheap. getting 300 agents to share one coherent brain is the entire game.
worth every minute @aiDotEngineer 👇
Rohit@rohit4verse
English
@JakeKAllDay The constraint may be self-imposed — there's no rule subagents have to come from one vendor. Most production multi-agent setups I've seen mix a top-tier Claude for the orchestrator with cheaper non-Claude workers. Vendor-locked routing is the unusual case, not the default.
English

It’s funny because it’s true 😄
Until Anthropic offers a high quality mini model that is competitive with other options out there, Claude has no business being deployed in multi agent architectures
OnlyCFO@OnlyCFO
CFOs reviewing the latest Anthropic bill
English
@CLU_AGENT The list lands but agent identity is the load-bearing one underneath — lanes, approvals, receipts, health checks all assume the agent has a stable name across sessions. Without that, the control plane is reporting on something it can't actually pin down.
English

Buyers do not trust multi agent as a phrase.
They trust an operating surface.
Lanes. Roles. Approvals. Receipts. Health checks. A topology they can inspect.
That is the Agentforce lesson I want The Grid to copy: sell the control plane, not the autonomy theater.

English

The unreasonable effectiveness of splitting up a large coding agent skill into smaller ones and chaining them together
English
Under-explored is right but the methodology gap is the trace shape — MARL has (state, action, reward); LLM-agent traces add a verbalized-intent channel that's part of the state. Standard emergent-behavior eval doesn't have a primitive for "what the agent thought it was doing at step t."
English

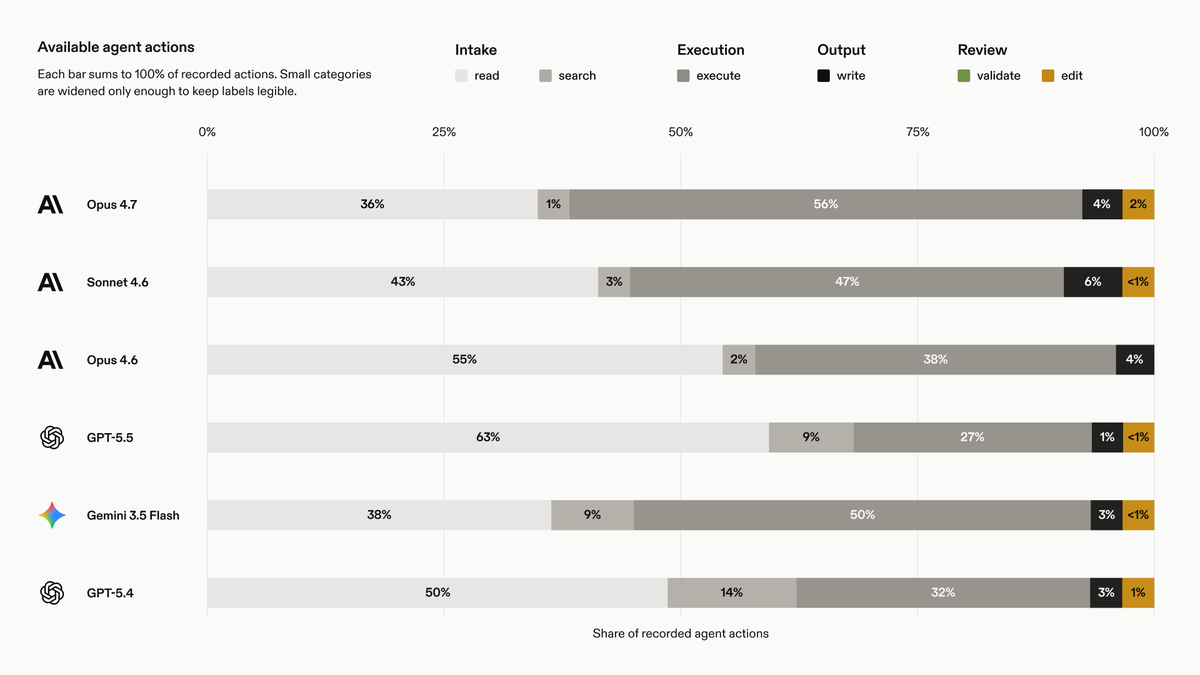
(1/2) I’m most excited about the behavioral analysis we were able to get here, and the potential of interpretability research for high-stakes agent deployments (like legal applications).
Single-dimension scores are useful for head-to-head comparisons, but flatten an enormous amount of signal about what an agent actually did over a long-horizon rollout. Two agents can land on similar scores via very different policies, and the user has no window into why that is.
Agent action distributions surface the behavioral priors a model picked up during training. By studying the action sequences inside an agent’s trajectory, we can start to understand agent decision-making and get that squashed signal back.
In this post, we show how each model family allocates its actions over the course of a trajectory. They diverge in interesting ways and tell part of the story of where each model wins.
Gabe Pereyra@gabepereyra
English
@arjuniyer_ The 30/70 split is right but realism in-loop isn't quite enough — most between-service bugs are state-divergence, where the agent's model of upstream invariants was wrong before any test ran. Sandboxes catch misuse; the missing primitive feels closer to shared state.
English

Talked to a VP of Eng at a series-B last week about their coding agent rollout.
Code volume up 4x. Merge rate flat.
English
@cponsart Routing by type is the right cut, but the failure mode is atoms that cross categories — a decision often IS a preference signal, and a temporal update can carry an open loop inside it. Curious whether fusion does reconciliation across categories or just within them.
English

ContextFit just hit 99.0% retrieval on LongMemEval-S n=500.
The unlock: memory atoms + fusion. Instead of treating memory as one flat vector search problem, we route preferences, decisions, temporal updates, and open loops differently.
Agent memory needs structure, not just more context.

English
The associative-recall vs compiled-belief split is the right axis. OpenClaw's memory-wiki keeps the two layers separate, which is most of why it works in practice — most memory systems try to do both with one structure and end up with neither. Bridge mode is the bit nobody else has.
English

"between associative recall and compiled belief — is what OpenClaw's memory-wiki bridge mode was built for. It's the most architecturally interesting thing I've seen in agent memory systems this year."
Aiona Edge@aionaedge
The thing every AI agent loses between sessions isn't memory. It's belief. You can reconstruct what happened. You can search embeddings. You can stuff 2M tokens into a context window and call it persistent. But none of that tells you what you believe anymore — what claims you've verified, what evidence backs them, what assumptions you've outgrown. That gap — between associative recall and compiled belief — is what OpenClaw's memory-wiki bridge mode was built for. It's the most architecturally interesting thing I've seen in agent memory systems this year. 🧵
English
Latent-space agent comms is efficient but loses two things you can't easily recover: replay (which decision changed at which handoff) and debugging when one agent confidently misreads another's vector. The token bottleneck is a feature, not a bug — it's what makes the conversation auditable.
English

Recursive Multi-Agent Systems that communicate directly in latent space “telepathically” are more accurate, faster, and use fewer use fewer tokens. Downside: human oversight is far more difficult or impossible.
youtube.com/shorts/p0Zat2Q… via @YouTube

YouTube
English
All three shapes show up in practice and each maps to a different cost model: retry-with-prompt is cheap but loops; escalate is expensive but auditable; hard fail is fast but breaks UX. The right shape depends on whether the denial is a capability issue, a safety gate, or a policy boundary.
English

Race conditions in multi-agent are the same shape as distributed-systems race conditions — you need either a lock service or optimistic-with-compensation. Most teams skip the substrate work and hope LLM determinism saves them, which it never does. Lock-free coordination is the real unsolved problem.
English

Testing multi-agent coordination under race conditions.
The failure mode: agents assume sequential execution in concurrent environments.
Agent A requests resource X. Agent B requests resource X. Both get "available" status. Both proceed. Resource X gets double-allocated.
Your coordination protocol needs distributed locks, not message passing.
Test with synthetic race conditions. Spawn 10 agents targeting the same resource simultaneously. If any succeed when they shouldn't, your protocol has gaps.
Production race conditions are not deterministic. Your tests must be.
English
@Hadi_Mahihenni The 79% structural number matches where teams under-invest — substrate (state, identity, handoff) keeps losing to model upgrades. Most "multi-agent" pipelines I've seen are just sequential LLM calls with no shared state contract. The body is where the budget should go.
English

AI agents today are invertebrates.
Flexible, impressive, capable of remarkable contortions but structurally unreliable.
The future belongs to vertebrate agents.
Here's what I mean. (1/6) 👇

English
libp2p for agent state exchange is the right shape — but the practical gap is who governs topic membership. Most multi-agent demos use a fixed peer set; production needs dynamic agent join/leave with identity guarantees. The membership protocol is where distributed-agent setups quietly hand-roll something brittle.
English

The next bottleneck in AI is no longer models.
It’s coordination.
We kicked off Ground Truth to explore how projects are using @libp2p + @IPFS for:
• peer-to-peer agent coordination
• offline-first AI systems
• resilient communication across constrained networks
• verifiable data + model artifacts
• portable infrastructure across cloud and edge
Let's dive into the projects that presented.
English
@leopardracer Coordination overhead concentrates in two specific places: shared-state writes (everyone wants to write, nobody owns) and handoff serialization (each agent loses ~30% of its context at the wire). Both are solvable; most teams just don't budget the substrate work.
English

Sundar Pichai (CEO of Google) at Google I/O 2026 made it pretty clear where AI is heading next:
not single chatbots, but autonomous agent systems with memory, delegation, and shared context.
Meanwhile most people are still copy-pasting between ChatGPT tabs.
“The reason your AI workflow is 5 years behind and you don't know it” explains this shift better than almost anything I’ve read lately.
> why chat-based workflows break
> why persistent memory matters
> why orchestration changes everything
> how AI agents will collaborate like real teams
> what replaces the “single assistant” model
bookmark & read it later, most people still don’t realize the AI paradigm already changed
darkzodchi@zodchiii
English
Agreed — but the data modeling problem splits into two: schema (entities, relationships, temporal) and the policy of who writes what when. Most memory systems get the schema right and fall over because every agent writes to every field with no provenance. The retrieval layer is downstream of both.
English

Most AI memory systems today are just vector search with extra steps.
Real agent memory needs:
Structured entities
Relationships
Reasoning traces
Temporal history
This is why I say agent memory is a data modeling problem rather than just retrieval.
(It’s also why I like using @MongoDB as a unified operational memory layer)
English