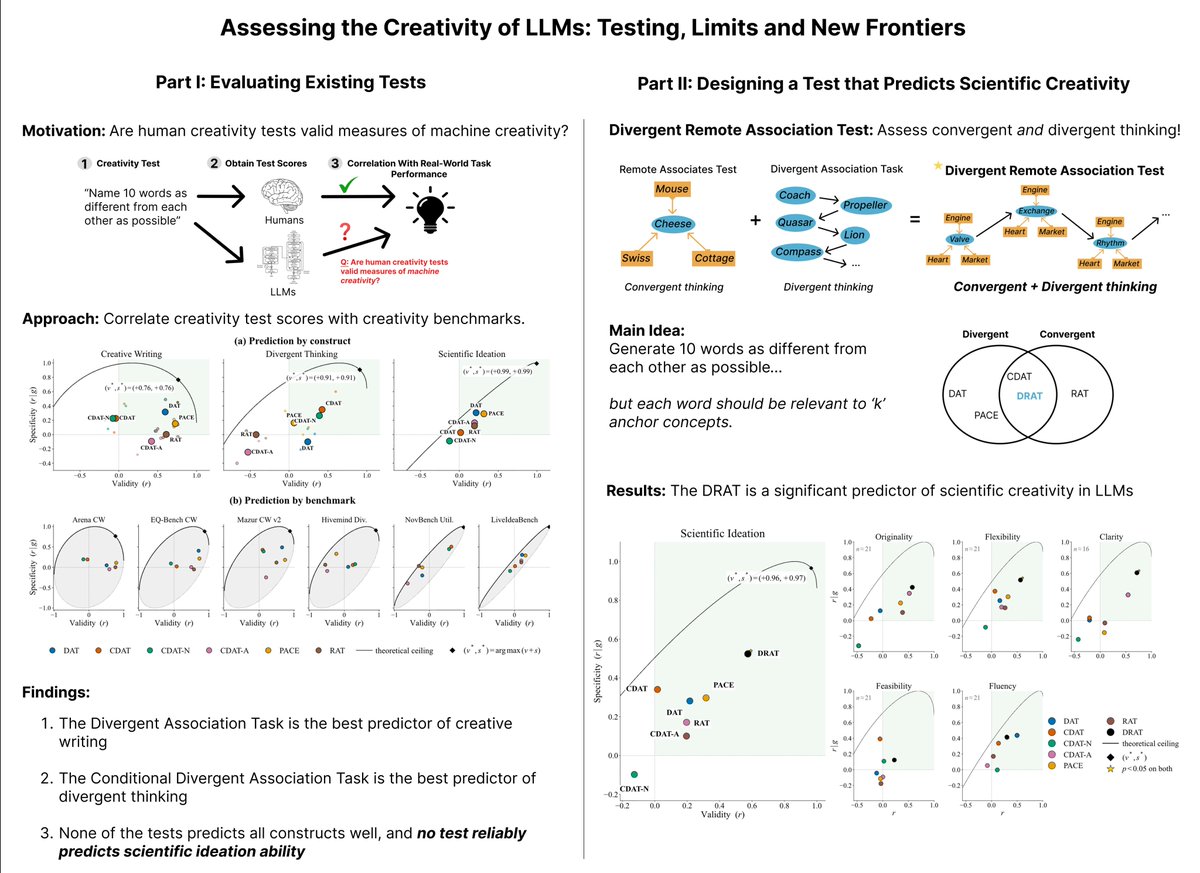
Sabitlenmiş Tweet

As someone who pivoted from ML theory -> cognitive science in 2024 (but is now working to bridge the two), I cannot emphasize this enough.
At the beginning of my career, like many other theorists, I was captivated by the mathematical elegance of learning-theoretic frameworks (PAC, ERM, etc.) and excited to use tools from probability theory to characterize the generalization abilities of learning algorithms.
However, I soon realized there was a type of generalization (creativity) unexplained by prevailing frameworks. This demanded a return to first principles—philosophy, psychology, epistemology, even metaphysics—transitioning to what Thomas Kuhn would call "extraordinary science."
Two years in, the journey has been arduous but rewarding. It's evident that certain problems command an interdisciplinary approach, with creativity clearly being one of them.
Along the way, I read many, many books, and one quote from Popper continues to be a strong source of inspiration:
"We are not students of some subject matter but students of problems. And problems may cut right across the border of any subject matter or discipline."
-Karl Popper, Conjectures and Refutations: The Growth of Scientific Knowledge (p. 141)
Misha Teplitskiy | Science of Science@MishaTeplitskiy
New paper on PhD admissions and pivots! Scientific communities need new ideas to stay productive and relevant. One source of new ideas is students who pivot from other fields. Do such pivots pay off for the student or the community? 🤔 1/3
English