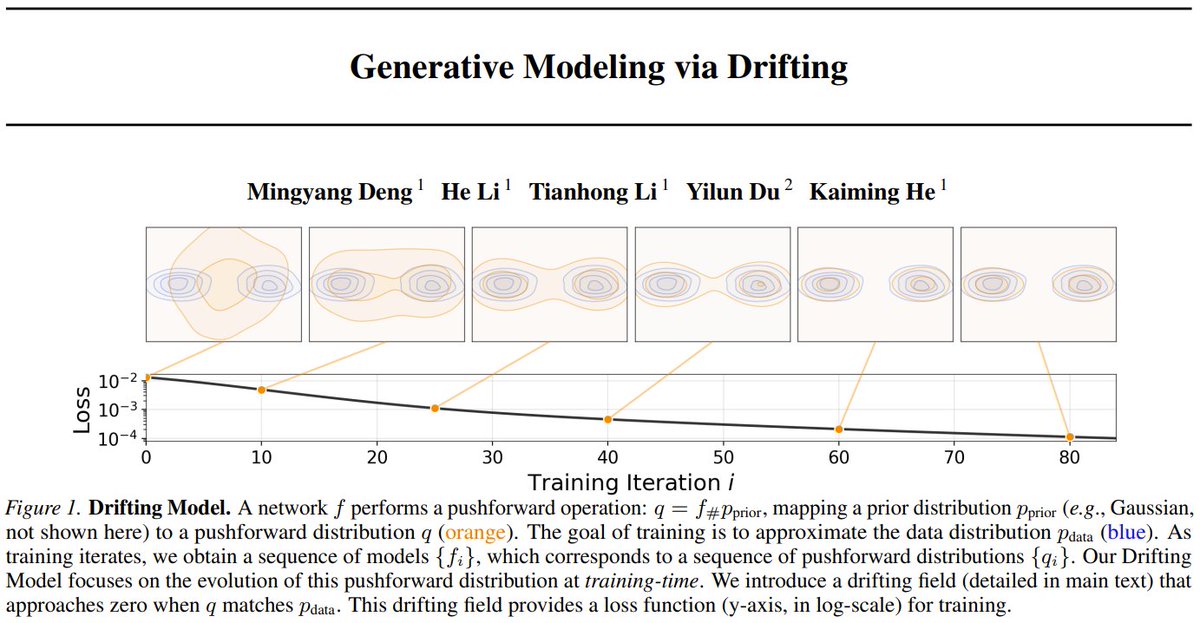

lalo hernandez retweetledi

based off of the original blog i wrote to show ray tracing in 15 minutes in pytorch, this new iteration is a blog that describes the same but in jax for tpus.
the goal is to show that a ton of problems can be expressed in tpu-compliant ways.
link below!
x.com/halcyonrayes/s…

Suvaditya Mukherjee@halcyonrayes
ray tracing ☀️ is among the cleanest algorithms out there that had been fairly out of reach for consumer machines until gpus happened. over the weekend, i wrote a tiny 15-minute intro to ray-tracing in simple @PyTorch to introduce the algorithm and make a ray-traced sphere! (1/n)
English