
sbstndbs
171 posts

sbstndbs
@sbstndbs
Perf SWE | AI Inference Chips, HPC & Physics
Katılım Ocak 2022
184 Takip Edilen25 Takipçiler

@jspquoimettreff Je te laisse aller lire le code, ça n'envoie pas le prompt…
Cela envoie juste l'information que l'utilisateur est énervé !
Rien à voir avec un "dislike button" mais merci pour ton intervention tout en finesse…
Français
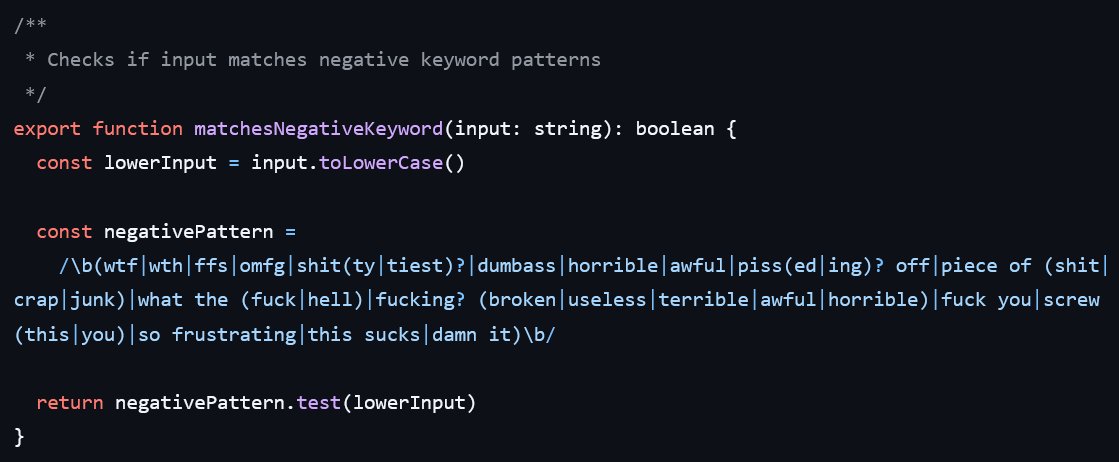
👀 Trouvé dans le code source de Claude Code : une REGEX qui détecte si tu insultes ou t'énerves (en anglais).
Si ça matche, l'info est loggée silencieusement. Aucun impact sur la réponse de Claude.
Il te répond pareil. Mais il note que t'as pété un câble.
Curieux de savoir ce qu'Anthropic fait de cette donnée.

Allex, France 🇫🇷 Français
sbstndbs retweetledi

VSORA Jotunn8
- 8 compute chiplets
- 8 HBM3E
- TSMC CoWoS-S packaging
- 500 W TDP
The package is just a dummy right now. Production is ramping up right now. We will have to wait until MLPerf Inference v6.1 to see how it compares to the competition.




English

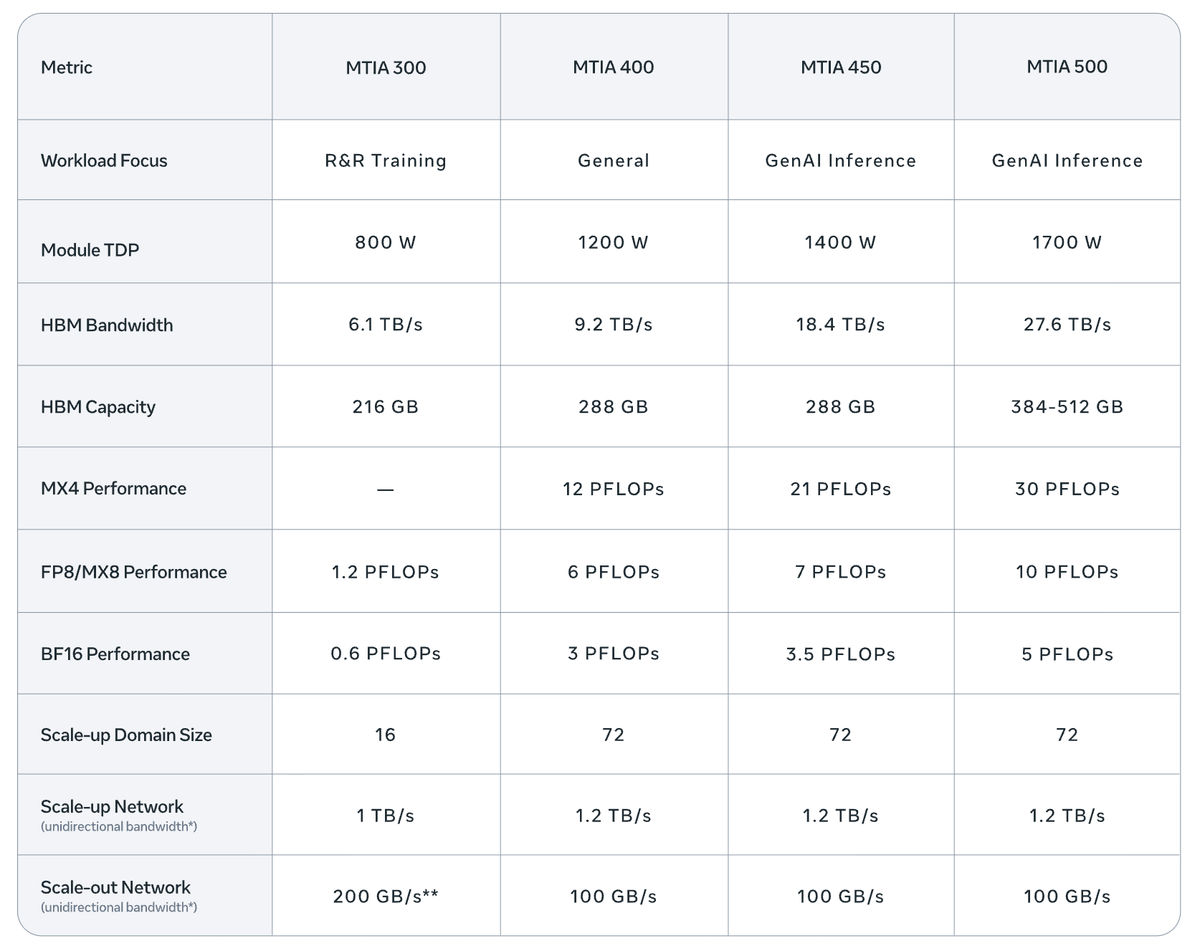
Huge silicon roadmap announcement from $META.
MTIA 300, 400, 450, 500. All optimized for inference.
MTIA 300 for recommendations (money printer).
MTIA 450, 500 for GenAI inference.
Meta and Google have the cleanest ROIC story in custom silicon IMO.
MTIA team made good inference-first trade-offs.
72-chip scale-up domain and tons of HBM bandwidth, but modest scale-out networking.
Custom low-precision data types (MX4, MX8).
Software stack runs fine, Meta invented PyTorch after all
Also shows why The Information's "scrapped training chip" story wasn't a concern. $NVDA GPUs are great for training. Custom silicon is about inference.
Helpful detailed write-up, see the link below.

English


@JohnGrf3891 @Wald52Wald Je suis sur 2x3090 donc j'ai opté pour le 27B :)
Français

@sbstndbs @Wald52Wald Merci. Je regarde demain. Tu as testé sur quel setup ?
Français
Vous le faites tourner comment Qwen 3.5 27b ?
sur ma RTX 3060 sa se lance meme pas (vllm)
Français
@JohnGrf3891 @Wald52Wald Il vaut mieux essayer le MoE 35B en l'occurrence, moins de transfert host/device
Et regarder l'option multi token prediction également
Français
@Wald52Wald oui j'ai vu. J'ai assez de RAM, mais clairement le débordement rend le truc hyper lent.
Français
@meekunv2 @zephyr_z9 Hmmm .. didn't see this issue. On my side, the q4 27B In llama/cuda is very great
English

@zephyr_z9 tried both 35b-a3b and 27b, the MoE is MUCH more useful for regular use, 27b appears very benchmaxxed across the board and really not that good
English

What did they cook with the 27B ??
HOLY
Victor M@victormustar
wow Qwen3.5-27B score on Humanity's Last Exam 🚀
English

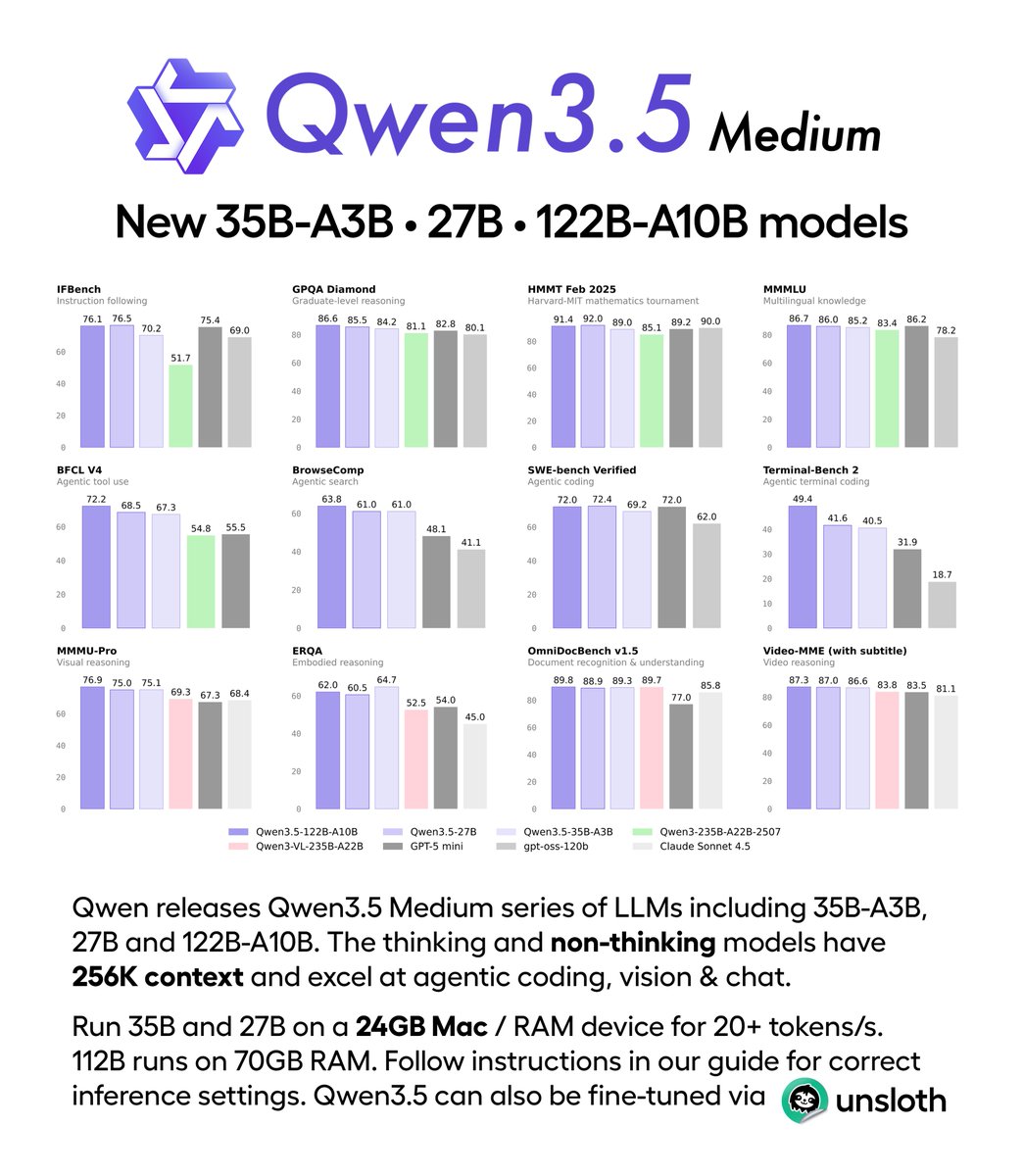
Run the new Qwen3.5 Medium models! 🔥
- Qwen3.5 35B-A3B (MoE, 24GB RAM)
- Qwen3.5 27B (dense, 18GB)
- Qwen3.5 122B-A10B (MoE, 70GB)
The multimodal hybrid reasoning LLMs are the best performing for their sizes.
GGUFs: huggingface.co/collections/un…
Guide: unsloth.ai/docs/models/qw…
Qwen@Alibaba_Qwen
🚀 Introducing the Qwen 3.5 Medium Model Series Qwen3.5-Flash · Qwen3.5-35B-A3B · Qwen3.5-122B-A10B · Qwen3.5-27B ✨ More intelligence, less compute. • Qwen3.5-35B-A3B now surpasses Qwen3-235B-A22B-2507 and Qwen3-VL-235B-A22B — a reminder that better architecture, data quality, and RL can move intelligence forward, not just bigger parameter counts. • Qwen3.5-122B-A10B and 27B continue narrowing the gap between medium-sized and frontier models — especially in more complex agent scenarios. • Qwen3.5-Flash is the hosted production version aligned with 35B-A3B, featuring: – 1M context length by default – Official built-in tools 🔗 Hugging Face: huggingface.co/collections/Qw… 🔗 ModelScope: modelscope.cn/collections/Qw… 🔗 Qwen3.5-Flash API: modelstudio.console.alibabacloud.com/ap-southeast-1… Try in Qwen Chat 👇 Flash: chat.qwen.ai/?models=qwen3.… 27B: chat.qwen.ai/?models=qwen3.… 35B-A3B: chat.qwen.ai/?models=qwen3.… 122B-A10B: chat.qwen.ai/?models=qwen3.… Would love to hear what you build with it.
English
@thismacapital Le MCP de notion est incomplet et ça peut poser des problèmes, notamment avec les database. J'ai complété le MCP avec toutes les fonctionnalités en recouvrant tous les appels API Notion existants et c'est bien mieux.
Ça marche bien avec codex, Gemini et glm-4.7
Français

J'ai pas mal utilisé Claude avec Notion à travers le mcp officiel et vraiment pas convaincu, même si il oublie que 10% des datas c'est pas du tout utilisable car trop de risque d'erreur
Je vais pivoter sur Obsidian qui est Notion like mais en utilisant que des .md donc beaucoup plus accessible et optimal, je vais recréer mes datas sur les 2 systèmes et je vais comparer les résultats de CC
Français
@blin2h @abhijitwt Limited features ! No clean database access and so on. I have reimplemented a version that fully supports the notion API, and it is much more efficient and comprehensive.
English

@sbstndbs @abhijitwt Why? I’m testing it with GLM 4.7 and it works well
English

@abhijitwt Why notion has AI? I hope it's just an addition to their excellent MCP server
English
@Transilien921 Il n'y a pas un arrêt CEA porte Nort prévu ? Il me semblait que si !
Français

Mais personne ne parle de la longueur de l’inter-station Guyancourt - Saclay ??? C’est combien de Km ? 😭
Le Ferroviphile@Cheminot_du_75
Ile-de-France : Le 1er tronçon de la ligne 18 du métro automatique @GdParisExpress (Christ de Saclay↔️Massy-Palaiseau) ouvrira bien en octobre 2026. Une 1ère depuis 28 ans pour le métro grand parisien, après 16 ans d'études et de travaux.
Français

hardware men invested in intel
software boys invested in figma
English

I heard from someone who works at a big tech co that they started rolling out Claude code to employees, with a budget of $100 in credits per month, but people burn through it in 2-3 days.
Idk how we scale out agentic work with api pricing
English
My 2025 OpenRouter Wrapped is here! 🏆 Top 10% of Sonoma Sky Alpha users. See yours: openrouter.ai/wrapped/2025/0…
English
@OpenAIDevs OpenAI is openAI-ing. What's their problem with graph axes?
English

GPT-5.2-Codex is more cyber-capable than GPT-5.1-Codex-Max, and we expect future models to continue on this trajectory.
This helps strengthen cybersecurity at scale by giving defenders more powerful tools, but also raises new dual-use risks that require careful deployment.
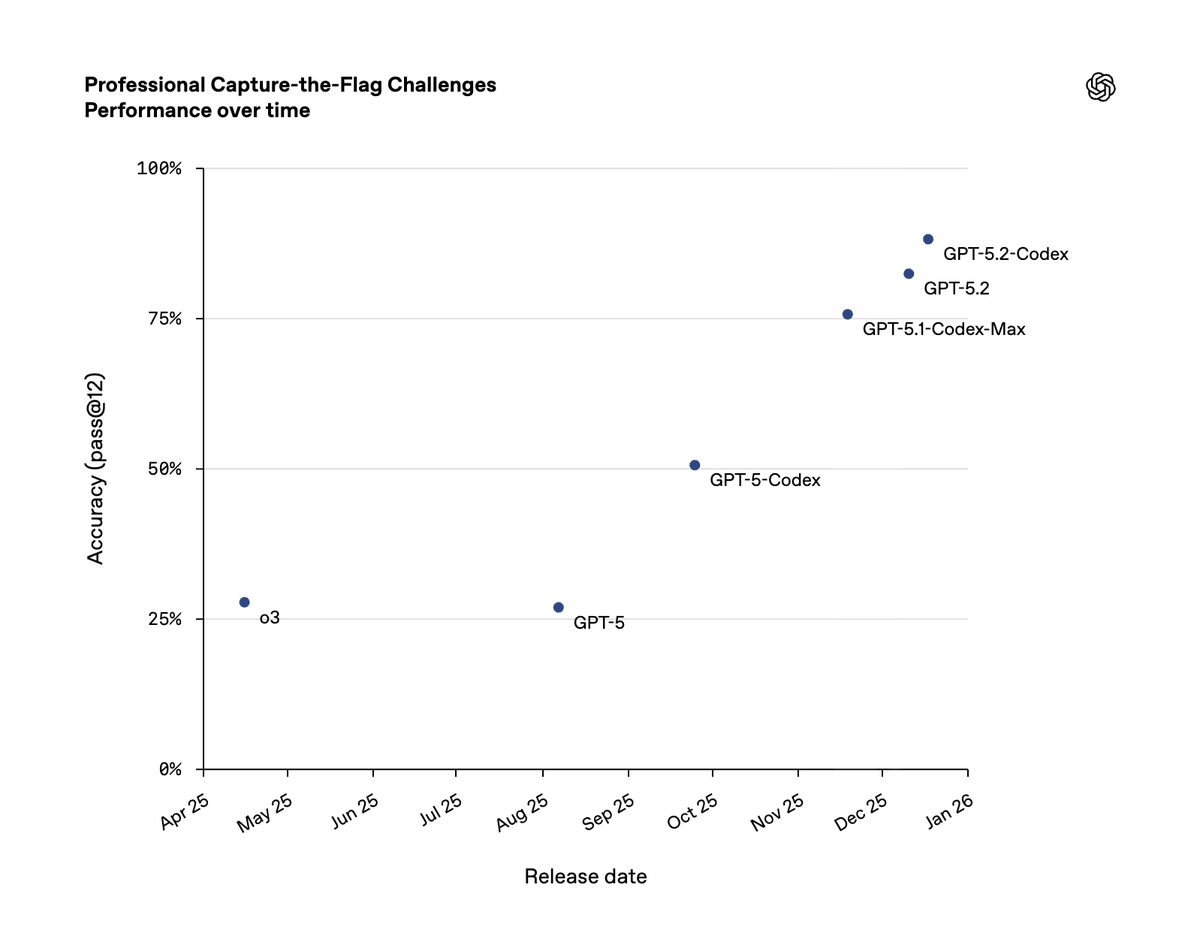
English
Meet GPT-5.2-Codex, the best agentic coding model yet for complex, real-world software engineering.
With native compaction, better long-context understanding, and improved tool-calling, it is a more dependable partner for your hardest tasks.
Available in Codex starting today.
openai.com/index/introduc…
English
sbstndbs retweetledi

NO, NO, NO!
there’s no exponential, we hit a wall, AI is a bubble, it won’t scale, LLMs are a nothing burger, it’s all a Ponzi scheme,

ARC Prize@arcprize
Gemini 3 models from @Google @GoogleDeepMind have made a significant 2X SOTA jump on ARC-AGI-2 (Semi-Private Eval) Gemini 3 Pro: 31.11%, $0.81/task Gemini 3 Deep Think (Preview): 45.14%, $77.16/task
English
@badlogicgames That's why it rerun a lot of commands with different sed lines 🥲
English

This is even funnier. Codex will truncate any Bash/MCP tool output to 256 lines or 10kb. If the tool call outputs more than that, then the model only gets to see the first 128 lines, and the last 128 lines, but nothing in the middle.
Been like that since August. No wonder poor GPT is slow going in circles trying to understand WTF it's actually seeing.



Mario Zechner@badlogicgames
Heh, recent Codex is truncating tool outputs before they get passed to the model, instead of as a part of context/history clean-up. Making MCP servers a tiny little less useful. github.com/openai/codex/i…
English