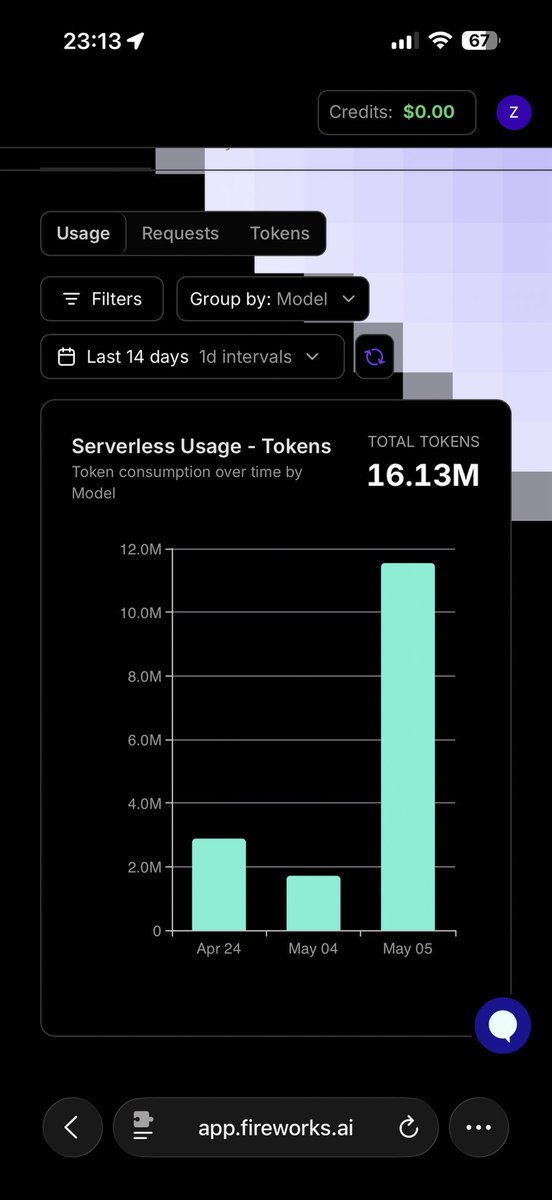
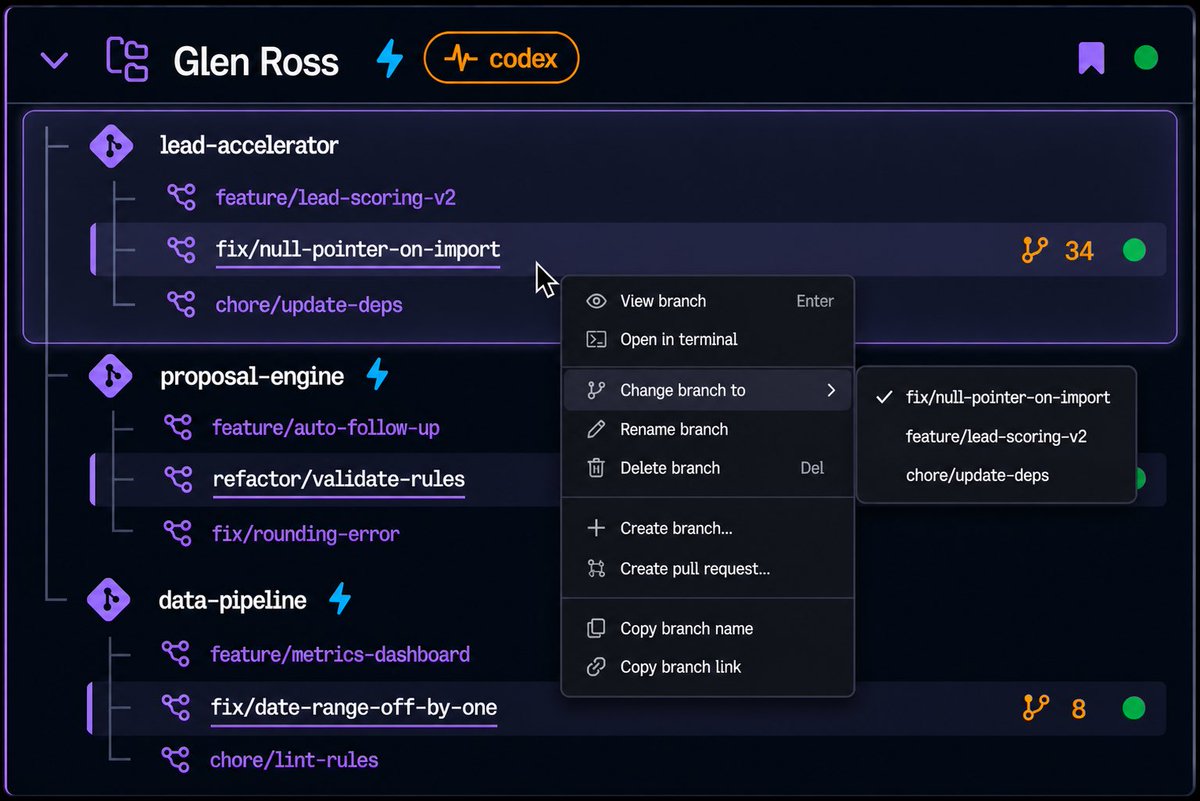
Sabitlenmiş Tweet

If I were to stream… and it was mostly just me doing my day to day work, while talking to chat, would anyone watch? Setup isn’t going to be anything stellar, no real agenda - I’d pretty much just go do stuff across 5 or 6 repos in parallel & talk through what I’m thinking
English