Sabitlenmiş Tweet

Excited to announce @Pulse__AI's $3.9M seed led by @natfriedman and @danielgross with participation from YC and some amazing angels!
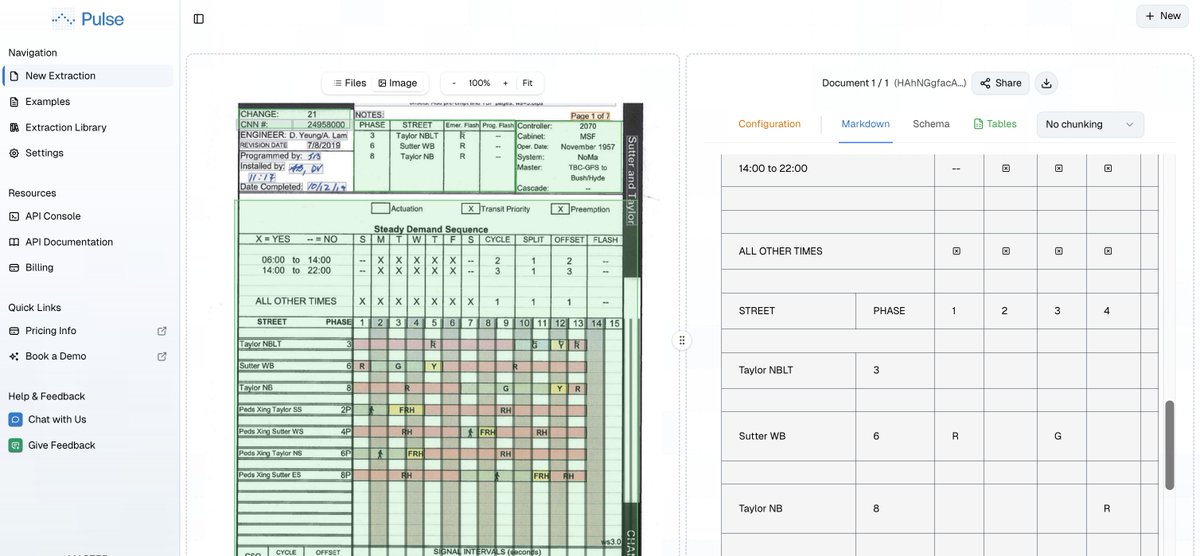
Document processing has existed for decades, yet both legacy players and AI startups still struggle with real-world extraction. We're solving this with intelligent schema mapping that maintains accuracy across millions of complex documents.
We’re hiring, please reach out!

English