sokel.exe
50 posts


sokel.exe
@sokelabs
ML • AI systems • workflows • tooling
Katılım Mayıs 2026
61 Takip Edilen30 Takipçiler
@arynnsgh That separation makes a lot of sense.
I’ve been seeing the same issue in agent memory experiments: semantic similarity often looks like memory, but breaks on factual precision and project-specific context.
How do you decide what goes into vector memory vs graph memory?
English

@sokelabs Working on agent memory too. One thing worth separating: working memory (in-context), episodic memory (vector store), and semantic memory (knowledge graph). Most RAG setups conflate the last two, which kills retrieval precision on long-running agents. Happy to compare notes.
English
sokel.exe retweetledi
@rahulsinghh__ Nice to meet you Rahul.
This fits well into indie dev launch workflows. Store screenshots are a small thing, but they slow shipping down a lot.
Are you planning templates or AI-assisted generation by app category?
English

@sokelabs Hi Sokel, its Rahul here.
I’m building Biscuit 🐶, a dead simple App Store and Google Play screenshots maker.
For indie developers/solopreneurs who wants to ship fast 🚀
Looking to connect with fellow builders 🤝🏻
meetbiscuit.com
English
@debojyoti452 Nice, this sounds like a full email infra layer.
The CLI + sandbox mode part caught my attention. Are you mainly targeting developers/startups who want a simpler alternative to SendGrid/Postmark?
English

Hii,
Building keplars.com - an email infrastructure platform focused on making setup and tracking much simpler. Unifies transactional and marketing email with OAuth sending, custom domains, built for both tech and non-tech users. Setup time? 5 clicks.
here are the features:
- Email API
- SMTP
- Webhooks
- SDKs for 11 languages
- Real-time email tracking after sent, open time, delivered time, click time
- email automations docs.keplars.com/automations with AI-generated templates
- CLI docs.keplars.com/cli
- unified email editor enceladas.com
- sandbox mode for testing emails
- Integrates with Firebase, Supabase, Vercel (Vercel Marketplace), Lovable, React Emails, PocketBase, PayLoad CMS, Zapier and more
Pricing: keplars.com/price-calculat…
English
@ClaudeDevs This is a good example of AI coding tools moving from generation to inspectable workflow control.
The important part is not only finding vulnerabilities, but deciding when to check: file edit, model turn, commit, or review.
English

We’ve shipped a security-guidance plugin for Claude Code that helps identify and fix vulnerabilities as you’re writing code.
Available for all Claude Code users. Install from the plugin marketplace (/plugins).
English
Building a personal AI operator made me realize the model is not the product.
The real product is the runtime around it:
memory
permissions
tool use
approval flows
project context
execution traces
fallbacks when local/cloud models are not enough
That’s where personal AI gets interesting.
English
@JustJerry121 Definitely. Memory without observability gets hard to trust fast.
I’m especially interested in making retrieval decisions, conflicts, and context selection inspectable instead of treating memory as a black box.
English

That progressive disclosure approach makes a lot of sense.
I recently started a full-time role working around BERT-based financial models for fund buy/sell decision support, so trading logic + automation + usable tooling is a very relevant intersection for me now.
Happy to chat more.
English

@flytradr_guy Nice, followed back.
I recently started working around financial models, so trading automation and strategy tooling are especially interesting to me.
Curious how you balance no-code simplicity with enough control for serious strategy builders.
English

Recency is a signal, but not the primary policy.
Fusion should be type-aware: a preference update, decision record, operating policy, and observation shouldn’t all compete on the same axis.
A newer preference may override an older preference, but it shouldn’t silently override a decision record. It should create a conflict edge: “this preference contradicts this decision.” Then resolution depends on type, authority, scope, and approval state.
So less “latest wins,” more “typed memory with provenance + explicit conflict handling.
English
ContextFit just hit 99.0% retrieval on LongMemEval-S n=500.
The unlock: memory atoms + fusion. Instead of treating memory as one flat vector search problem, we route preferences, decisions, temporal updates, and open loops differently.
Agent memory needs structure, not just more context.

English

I’m starting to care less about “AI apps” and more about the systems around them.
Memory policies, retrieval quality, validation, traces, fallbacks, latency, evaluation loops.
The interesting work is not just calling a model.
It’s making the workflow reliable enough to trust.
English
@pauliusztin_ Semantic search retrieves by similarity, not usefulness to the current goal state.
Without ranking policies for recency, salience, task context, and lineage, agents get the most “similar” memory; not the memory they should actually trust.
English

We keep calling it “agent memory.”
But most systems are just semantic search over conversation history.
(Or even worse, files over conservation history)
Real memory requires a unified memory layer.
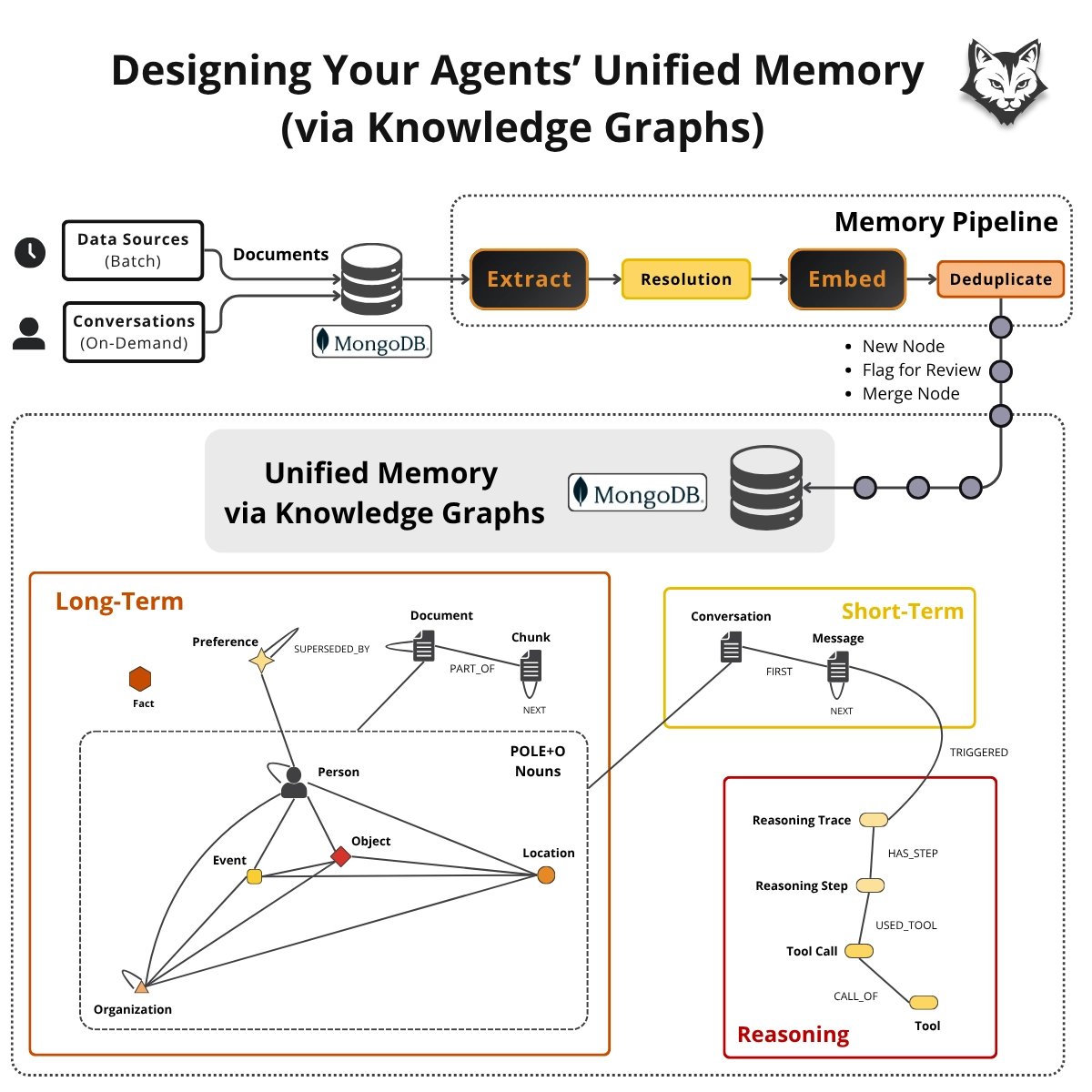
This is the architecture I keep coming back to when designing memory for agents.
(And I typically use @MongoDB as the unified memory layer)
Here’s the core idea:
One graph.
Three memory types.
One ingestion pipeline.
And this is how it works:
1/ Short-term memory → "What's happening now?"
This is the live conversation state.
A Conversation stores an ordered chain of Messages:
FIRST
NEXT
This is the agent’s working memory during a session.
2/ Long-term memory → "What's true over time?"
This is the durable knowledge graph.
It stores:
People
Organizations
Locations
Events
Objects
Preferences
Facts
Documents + chunks
All connected through typed relationships.
3/ Reasoning memory → "What worked before?"
The system stores reasoning traces as graph structures.
So the agent can query:
Which tools were used
What decisions succeeded
What failed previously
Which reasoning paths worked best
The agent can literally traverse its own thinking history.
But these are not isolated systems...
Everything lives inside one connected graph.
So the agent can trace lineage like:
“We know X, Y, Z about Paul from Message A, Document B, and Conversation C.”
The separation between memory types is mostly conceptual.
Underneath, it’s one unified graph.
This is why @MongoDB works well here because it stores:
Documents
Graph objects
Metadata
Vector embeddings
Inside one operational system.
Everything entering memory flows through:
Extraction
Resolution
Embedding
Deduplication
Resolution normalizes names.
Deduplication decides identity.
Confusing those two will corrupt your graph.
There are 2 pipeline entry points:
Batch Ingestion
Sources like:
Substack
YouTube
LinkedIn
PDFs
Notes
... flow into long-term memory on schedules.
Live conversations
As the agent chats and reasons, short-term memory gets distilled into:
Long-term memory
Reasoning traces
A nightly pipeline also re-processes recent nodes to improve normalization, detect duplicates, and discover new connections.
Here’s the big takeaway:
Agent memory is becoming a data modeling problem rather than just a retrieval problem.
P.S. What is the design of your agent’s memory?
English
'Language Models Need Sleep' is the agent-memory paper title everyone should steal as a product requirement. Long-running agents need consolidation, forgetting, and reset triggers or memory becomes hidden state debt.
English
@rolibosch @HermesLabsAi Would love to see them.
I’ve been exploring this from the observability/retrieval side: step-level workflow traces, retrieval failure modes, and memory/reduction issues.
Real framework-level PRs would help connect that to how these failures show up in actual codebases.
English

@sokelabs @HermesLabsAi By PRs I mean one of my upstream fixes to major frameworks (i.e. nasty Anthropic integration issue in Langchain I fixed that got merged a couple months back)
English
The “just use a better model” instinct is going to age badly.
A lot of deployment risk lives in orchestration, state handling, reduction logic, retrieval quality, and evaluation design.
Capability ≠ system trust.
English

validation-as-an-API for agents is genuinely a new product surface. agents don't ask twitter for feedback, they need a source they trust.
Vincent@VincentBuilds
5 years in B2B growth watched smart founders ship dead ideas. confidence, roadmap, full send now Claude Code, Codex, Cursor let you ship dead ideas in a weekend so I'm exposing Preuve as an API for AI agents. before your agent writes a line, it calls Preuve. 50+ live sources where 9 out of 10 ideas don't pass. structured JSON. we automated the build now we automate the verdict
English