虎の子 𝕏 🐯 retweetledi
虎の子 𝕏 🐯
54.5K posts


虎の子 𝕏 🐯
@suakow
Full time NEET, Part time AI Research | stories teller | INFJ 6w5 | marathon runner | anime | Barista FIRE | automated + robot trading | bubble tea
Thailand Katılım Ağustos 2009
277 Takip Edilen354 Takipçiler
虎の子 𝕏 🐯 retweetledi

คนญปที่ถูกส่งมาอยู่ไทยคือยังได้ base salary เป็นฐานเงินเดือนญปเหมือนเดิม จ่ายเป็นเยนโอนเข้าบัญชีที่ญป แต่ได้ allowance เป็นเงินบาทสำหรับใช้จ่ายในไทย บ้านพักฟรี หลายที่ให้คนขับรถรับส่งฟรีถ้าตำแหน่งระดับนึง คนเลยอยากมากกันมาก เหมือนได้เงินเยอะขึ้นแต่ค่าครองชีพถูกลงเทียบกับอยู่ญป
หมีเคน@PolarKen
บริษัทแม่ญี่ปุ่นเริ่มดึงคนกลับจากไทยละ เพราะเอากลับไปอยู่ญี่ปุ่น เริ่มถูกกว่า
ไทย
虎の子 𝕏 🐯 retweetledi

虎の子 𝕏 🐯 retweetledi

“เราต้องการ CEO มาพัฒนาบริษัท เราไม่ได้ต้องการพ่อบ้าน”
วิเคราะห์การเมืองกับสองคอการเมือง ใบตองแห้ง-อธึกกิต แสวงสุข และ ประทีป คงสิบ
(ออกอากาศเมื่อวันที่ 7 พฤษภาคม 2569)
▶️ ชมรายการเต็ม: youtube.com/live/QHy0DlikI…
#กทม #เลือกตั้งผู้ว่ากทม #ชัชชาติ #โจชัยวัฒน์ #พรรคประชาชน #การเมืองไทย #คอการเมือง #The101world #วันโอวัน

YouTube
ไทย
虎の子 𝕏 🐯 retweetledi

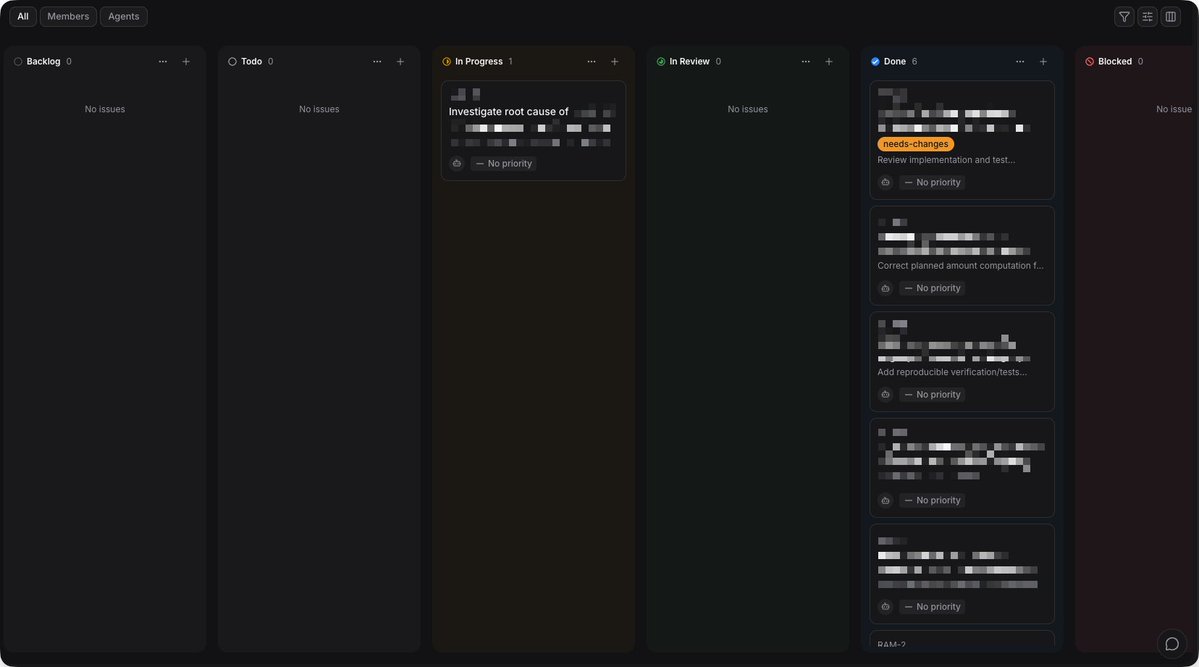
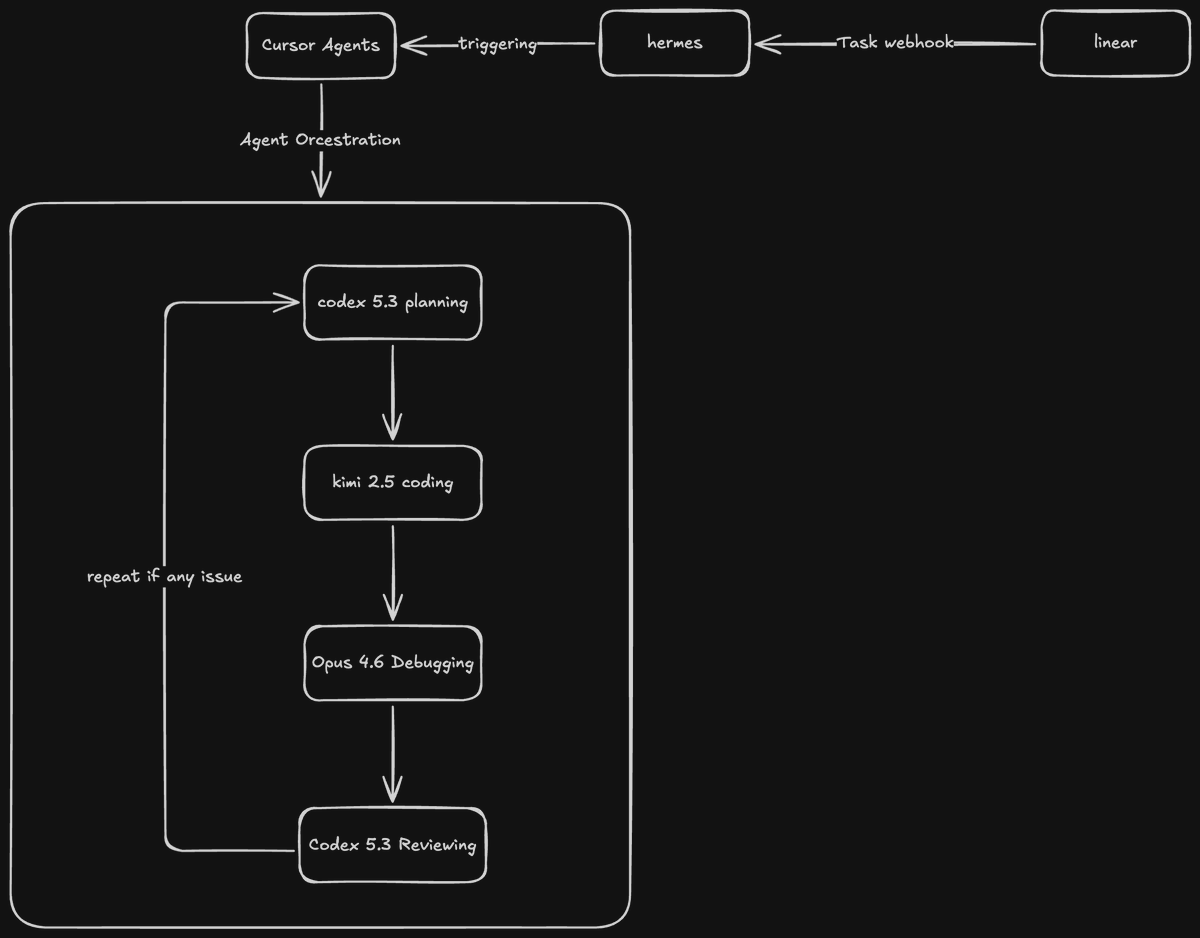
ทุกครั้งที่เปิดแชต Claude พิมพ์บรีฟเดิมไหม
"ผมเป็นการตลาด บริษัท X ขอสรุปยอดขายเป็น bullet ภาษาไทย ตัวเลขใส่ลูกน้ำ ห้ามแต่งตัวเลข ห้ามลบไฟล์ต้นฉบับ..."
แชตใหม่พิมพ์ใหม่ ลืมบางอย่าง Claude format ผิด คำศัพท์ผิดสาย ตามแก้ทุกครั้ง
⤵ บทที่ 3 หนังสือ Cowork เรื่อง Workspace setup
1. คิดว่า Claude คือพนักงานใหม่วันแรก
เก่ง หัวไว แต่ไม่รู้บริษัทเราขายอะไร แผนกใช้ภาษาแบบไหน กฎตั้งชื่อไฟล์ยังไง
2. Cowork อ่านบริบทเป็น 3 ชั้น
Global Instructions เซ็ตในแอป ใช้ทุก workspace
Folder Instructions วางในแต่ละโฟลเดอร์ เป็นกฎเฉพาะ
Context Files ข้อมูลเสริม บทบาท น้ำเสียง
กฎขัดกัน ชั้นแคบชนะ Prompt สดชนะทุกชั้น
3. กับดักที่ beginner ติด
Cowork อ่าน CLAUDE.md อัตโนมัติ ไฟล์เดียวเท่านั้น
ไฟล์อื่น about-me.md / brand-voice.md ต้องเขียนบรีฟใน CLAUDE.md ให้ไปอ่าน
# เริ่มเซสชันด้วยการอ่าน
- about-me.md
- brand-voice.md
- working-rules.md
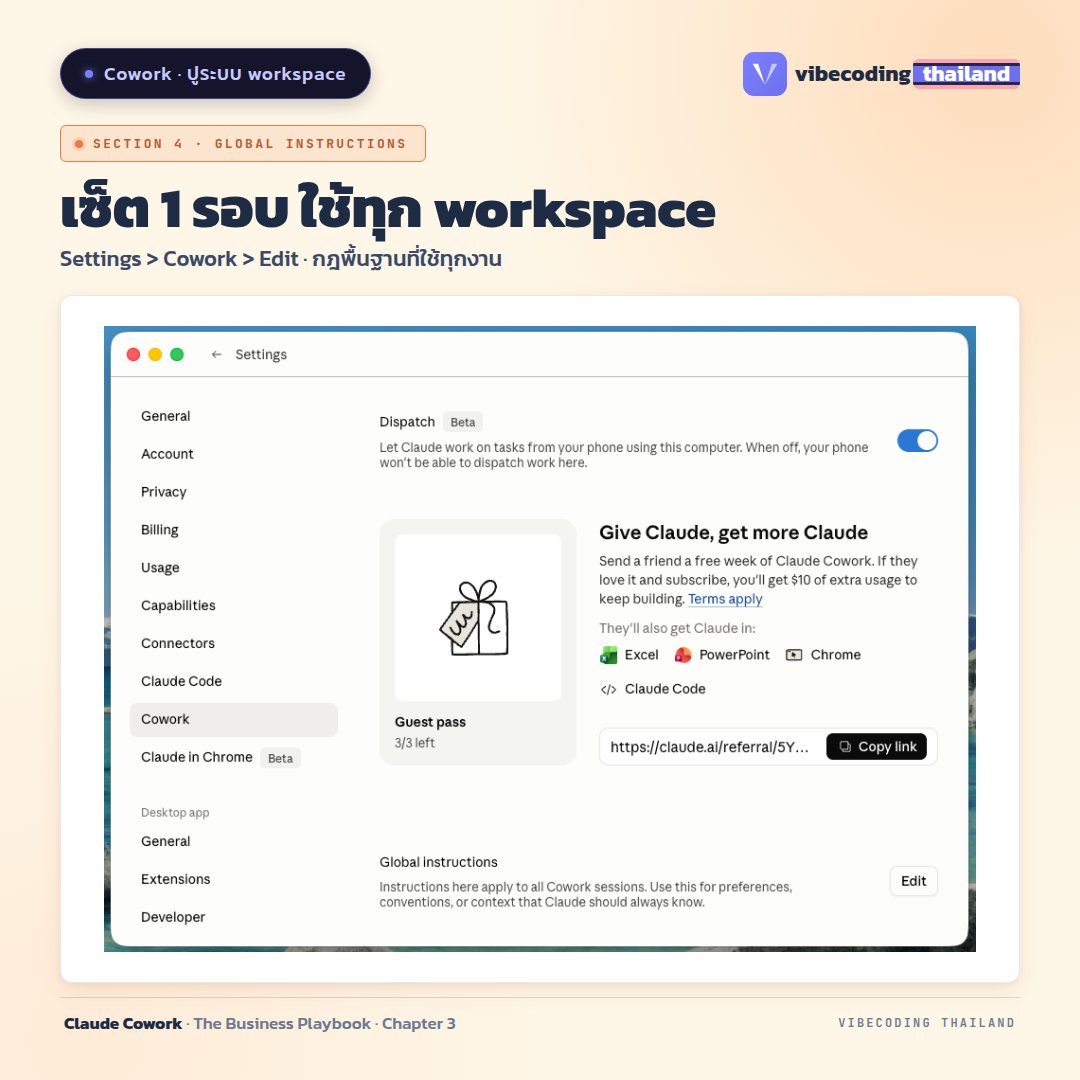
4. Global Instructions เซ็ตครั้งเดียว
Settings > Cowork > Edit ใส่:
ตำแหน่ง/แผนก
ภาษาที่ตอบ + ฟอร์แมตตัวเลข
ข้อห้ามเหล็ก
รูปแบบตั้งชื่อไฟล์
5. Folder Instructions
CLAUDE.md วางในโฟลเดอร์งาน เช่น Accounts-2026/
"งานบัญชี ห้ามแก้ CSV ต้นฉบับ จัดหมวดหมู่ตามผังบัญชีเท่านั้น"
6. Context Files 3 ไฟล์
about-me.md ตำแหน่ง หน้าที่ เป้าหมาย
brand-voice.md น้ำเสียง คำที่ใช้/เลี่ยง ตัวอย่างงานเก่า
working-rules.md ฟอร์แมต ตั้งชื่อ ข้อห้าม
7. ข้อมูลไหนอยู่ตรงไหน
ตายตัว และทุก workspace = Global
ตายตัว และเฉพาะโฟลเดอร์ = CLAUDE.md
ข้อมูลที่งอกได้ = ไฟล์ Context
8. ทดสอบก่อนสั่งงานจริง
"สรุปสิ่งที่เข้าใจจาก Instructions และไฟล์ Context ทั้งหมด ระบุ: ทำงานด้านไหน น้ำเสียงแบบไหน กฎอะไร ส่วนไหนยังไม่ชัด"
ตอบกว้าง = context ไม่ดีพอ
ตอบเป๊ะ + ชี้ช่องโหว่ = พร้อมลุยงานจริง
▪
เซ็ต workspace 30 นาที ทุกครั้งเปิดงานใหม่ Claude รู้ใจทันที
เวลาที่เคยพิมพ์บรีฟซ้ำ ย้ายไปทำงานจริงครับ
ใครเซ็ต CLAUDE.md ไว้ในโฟลเดอร์งานบ้าง ใส่กฎอะไร reply เล่าหน่อย
ลิงค์หนังสือ พร้อมคูปอง อยู่ใน reply
#ClaudeCowork #Workspace #vibecoding



ไทย


เอาจริงถ้า 5 ล้านคน ตกคนละ 300 ต่อปีเองนะ AI pro/premium ตอนนี้เราจ่ายกันเดือนละ 700+ นะ
ส่วนเรื่อง privacy เข้าใจได้ ถ้ากังวลก็ไม่ต้องไปขอใช้ ผมว่าโครงการดูดีเลยนะ
โจที่เพื่อนชอบเรียกผิดว่าโจ้@janthawoot
อันนี้อยากให้ทุกคนมาสนใจมากๆ เรื่องนี้เกี่ยวกับทุกคน มีผลกับทุกคน กระทรวง DE มีโครงการใหญ่ได้ผู้ชนะการเสนอราคาแล้วงบตั้ง 1,621ล้าน!! โครงการให้ปชช.ใช้ Ai ฟรี แค่ 1ปี รุ่น Pro/Premium ให้คนไทยอายุ 15 ปีขึ้นไป จำนวน 5 ล้านคน แต่หมดงบไปมากถึง 1,621ล้านบาท แถมส่องดูเราด้วยว่าเราพิมพ์ถามอะไร ai ได้ข้อมูลเราด้วยเพราะต้องบังคับให้เราต้องยืนยันตัวตนผ่าน ThaiD/ทางรัฐ และตรวจเลขบัตรประชาชน โดยโครงการนี้ชื่อ TH-AI Passport 1. ก่อนเข้าใช้ AI ต้องยืนยันตัวตนผ่าน ThaiD/ทางรัฐ + ตรวจเลขบัตรประชาชน 2. ทุกอย่างที่พิมพ์ลงไป จะถูกเก็บและวิเคราะห์เป็นรายบุคคล 3. ระบบต้อง "ประเมินความเสี่ยงในการใช้งานเป็นรายบุคคล" และตรวจ "การใช้งานผิดวัตถุประสงค์" 4. ข้อมูลทั้งหมด รัฐเอาไปใช้ต่อได้! 5.ในTOR ระบุบให้พาคนของ สดช.ไปดูงานที่บริษัทพัฒนา AI เจ้าหลักอย่างน้อยสิบคน รวมตั๋วเครื่องบินและที่พัก เดาๆคงไม่พ้นอเมริกา ผลกระทบกับปชช.อย่างเรามีแน่ๆคือ 1.การสูญเสียความเป็นส่วนตัวและถูกสอดส่องความคิด 2.ถูกประเมินความเสี่ยงรายบุคคล 3.ทำลายเสรีภาพในการตั้งคำถาม 4.ความเสี่ยงต่อข้อมูลของเด็กและการนำข้อมูลไปใช้ต่อ
ไทย
虎の子 𝕏 🐯 retweetledi

มึง บ้าน First jobber ราคา 7.49 ล้าน First jobber แบบใดวะ 5555555555555555555

虎の子 𝕏 🐯 retweetledi

- บีบแตร = หาเรื่อง
- ทางม้าลาย = ไม่ต้องหยุด ขับต่อเลย
- ขับผ่านต้นไม้ใหญ่ = บีบแตรเพื่อทำความเคารพ
- ห้ามชมเด็กเล็ก = ระวังผีจะเอาตัวไป
- requirement รับคนเข้าทำงาน = เด็กจบใหม่ แต่ประสบการณ์ 1-2 ปี และห้ามอายุเกิน 30
- เขียนชื่อสีแดง = ไม่มงคล
- เวลาจะเข้าโรงเรียน ทำไมอาจารย์ต้องมายืนตามทางเพื่อให้นักเรียนมาไหว้
- เชื่อเมีย ชีวิตดี = ระวังเป็น simp
- เบญจเพส = ระวัง!
เอเวอร์เรส@poppy_rjk
อยากฟังค่านิยมแปลกๆของคนไทยกันอ่ะ
ไทย
虎の子 𝕏 🐯 retweetledi

ขอแอบเพิ่มเติมให้ว่าศาลผู้บริโภคตอนนี้สามารถยื่นฟ้องทางออนไลน์ได้แล้วนะคะ เข้าเว็บไปกรอกข้อมูลได้เลย เราจะได้หมายเลขคดีมา แล้วทางจนท.ที่ดูแลเคสเราเค้าจะติดต่อมาเอง ถ้าต้องการข้อมูลหรือเอกสารเพิ่มเติมเค้าก็จะแจ้ง ถ้าเรียบร้อยก็ส่งฟ้อง รอนัดไปศาล สะดวกมากๆและไม่เสียค่าใช้จ่ายเลยค่ะ
쉰여섯 — ห้าสิบหก@fiftyzix
(แอบมาบอกทริค) เวลาผู้บริโภคมีปัญหา ไม่จำเป็นต้องไปแจ้งสคบ.นะคะ (เพราะแทบไม่ช่วยอะไร แถมทำงานช้ามาก) ทุกคนสามารถตรงไปฟ้องศาลผู้บริโภคได้เลยค่า อยากให้คนไทยทุกคนทราบอ้ะ ผู้ให้บริการจะได้เลิกลอยตัว
ไทย
虎の子 𝕏 🐯 retweetledi

Inference กำลังถูกลงอย่างรวดเร็ว แต่ compute กลับกำลังแพงขึ้นเพราะอะไร?
ฟังชัดๆ นะเด็กๆ
D E M A N D
ขอบคุณครับ 😜
dylan ツ@demian_ai
Inference got a hundred times cheaper this year. The compute bill went up anyway. If you understand why those two sentences are both true at the same time, you understand the most important thing happening in AI right now. I work on inference for a living, at @nebiustf, where we run open-source managed inference at scale. Most of what follows is what I'm seeing from inside the bill. 12 months ago, the cost of 1M tokens of frontier-class reasoning was somewhere on the order of $60. Today, an equivalent quality of output costs roughly $0.50. Price /token of o1-level intelligence has dropped about a 128x in a year. Price of GPT-4-level output has dropped roughly 100x since the original GPT-4 shipped. By any normal reading of a technology cost curve, this should be deflationary. It should be saving customers money. The opposite has happened. The total compute bill at every hyperscaler is going up, not down. Anthropic just signed multi-year capacity deals with both XAI and Amazon. Microsoft's Azure capex guide for 2026 starts with an eight. OpenAI is reportedly spending more on compute every quarter than it did in all of 2023. Nvidia paid roughly twenty billion dollars to acquire Groq, an inference-specialist company that did not exist as a serious commercial entity three years ago. The cost curve and the demand curve crossed, and then the demand curve lapped the cost curve. Here is what happened underneath. A reasoning model burns roughly 10x the output tokens of a non-reasoning model on the same task, because it spends most of its tokens thinking out loud before answering. An agentic workflow chains roughly twenty times the requests of a single-shot completion, because it loops, calls tools, plans, retries, and synthesizes. A modern deep-research query (the kind a research analyst can fire off in fifteen seconds and then walk away from for ten minutes) costs more compute than 10 original GPT-4 queries combined. We made every individual token a hundred times cheaper, and then we built a generation of products that consume ten thousand times more tokens. This is the Jevons paradox playing out at trillion-dollar scale, in compressed time, in front of everyone. Jevons noticed in 1865 that making coal-burning more efficient did not reduce coal consumption. It increased it, because efficiency unlocked uses that were previously uneconomic. Steam engines became more practical at smaller scales. Whole industries that could not afford coal at the old price suddenly could. Britain's coal consumption rose sharply, not despite the efficiency gains, but because of them. The same thing is happening to AI compute right now and it is happening faster than any analogous historical cycle. Falling token prices did not contract demand. They unlocked agents, deep research, code-writing systems, multi-step reasoning, persistent memory, the entire next layer of AI products. Every product in that next layer consumes orders of magnitude more compute than the chat interfaces it is replacing. The math at the aggregate level is brutal: 100x cheaper tokens times 10 000 more tokens equals a 100x larger total bill. The implications stack quickly. If you are running a hyperscaler, your 2026 capex guide is not a peak. It is a step on a curve. Inference is structurally always-on, twenty-four hours a day, in a way that training never was. Training is bursty. You spin up a cluster, run for weeks or months, and stop. Inference runs continuously, scales with usage, and the usage curve is exponential. Your power bill, your cooling bill, your transceiver count, your storage footprint, all of these were sized for a workload mix that no longer exists. If you are running an AI software company built on top of someone else's closed API, you have a problem that did not exist a year ago. Your gross margins get worse as your customers get more value out of your product, because the more they use it, the more compute you pay for. The companies that win this are the ones that figured out vertical integration before the math caught them. If you are watching this from a distance and trying to understand where the next bottlenecks form, the answer is everywhere downstream of "more inference compute, always-on, with massive memory state per session." The KV cache, the running memory state of a long conversation or an agent loop, is the silent monster of the inference era. It does not scale linearly with parameters. It scales linearly with context length and number of agent steps. A long agent session can hold tens of gigabytes of state per user, per session. Multiply that by every concurrent user of every product, and you understand why $MU, $SNDK, $TOWCF, and the entire memory and packaging layer have re-rated the way they have. The CPU-to-GPU ratio is evolving. Training is 1:8. Basic chat inference is 1:4. Agentic inference is 1:1, sometimes CPU-heavy. Google has split its TPU line in two, with a dedicated inference chip carrying tripled SRAM for KV cache. $INTC and $AMD just spent two earnings calls explaining that this shift is structural, not cyclical. The hardware map is redrawing in real time and the financial press is mostly still writing about training clusters. The right framing of where we are right now is not that AI is hitting a wall. The framing a year ago that scaling was hitting a wall was the most expensive bad take of the cycle. The right framing is that AI got dramatically cheaper, dramatically more capable, and dramatically more useful, and the cost of running it at the new equilibrium of demand is much higher than the cost at the old equilibrium of demand, because the new equilibrium is enormous. A meaningful share of what we actually do at Token Factory, day to day, is help customers stop their bills from running away from them. KV-cache management. Speculative decoding. Quantization. Routing. The kind of vertical integration that, eighteen months ago, every product team was happy to leave abstracted away behind a closed API. The reason this stack matters now is the same reason this whole essay matters: at the new equilibrium of inference demand, the cost of treating compute as a commodity is no longer survivable. The companies that figure out the layer beneath the API are the ones who keep their margins. Cheaper tokens. More tokens. Same coal as 1865.
ไทย
虎の子 𝕏 🐯 retweetledi

เมื่อ AI เก่งพอที่จะเข้าใจ Logic ในหัวคุณทั้งหมด
ถึงจะไม่เป๊ะเท่าเทรดมือ แต่เล่น M5 ตลอด ปีครึ่ง
ผ่านทุกตลาดไม่มีแตกนะจั๊บ 😂
แต่ยังรุ้สึกถ้ากราฟไม่สวิงไม่กำไรเลย
ขอไอเดียเพิ่มเติมหน่อย

MoMoyaki@bemasty1
วันนี้มาแชร์ประสบการณ์ใช้ AI 3 เดือน พร้อมข้อคิดที่ควรรู้เพื่อให้ใช้งาน AI ได้เต็มที่ ต้องบอกตอนนี้โม่แทบจะเป็น One man Business คือทำงานคนเดียวนอกนั้น AI ล้วน - ใช้สร้างบริษัทที่มีแต่พนักงาน AI Agent 14 ตัว 14 ตำแหน่ง มี Workflow การทำงานร่วมกันเหมือนทำบริษัทจริง - ใช้ AI สร้าง Website ทั้ง Backend + Frontend - ใช้ทำ Bot trade (กำลังพัฒนา) - ใช้สร้าง Agent ที่เลียนแบบลักษณะการเขียน content เอามาเขียนคอนเทนต์ X แทนเรา (ยังสอนเสร็จแค่ 80% ) 🔑Key สำคัญในการใช้ AI 1.ต้องมี critical thinking ต้องรู้จัก "วิเคราะห์ ตั้งคำถาม ประเมิน และสรุปข้อมูล" ก่อนที่จะเชื่อสิ่งที่ AI นั้นทำหรือบอกให้กับเราเสมอ เพราะ AI ไม่ได้ถูกเสมอไป จำตรงนี้ไว้ให้ดี 2.ต้องเข้าใจ Logic ของสิ่งที่จะทำ ข้อนี้ก็สำคัญคือถ้าคุณไม่เข้าใจ Logic ของสิ่งที่คุณทำแล้วไปอธิบายให้ AI = ไม่ว่า AI จะทำอะไรออกมาให้เราก็ไม่รู้ว่ามันทำถูกหรือผิดขั้นตอน 3. AI Agent นั้นมีดีคือการเรียนรู้ ยิ่งใช้ยิ่งเก่ง การใช้ AI ถามตอบทั่วไป ต่างกับการสร้าง Agent ค่อนข้างเยอะ เพราะตัว Agent จะสามารถจดจำทักษะเฉพาะด้าน มีลักษณะนิสัยของตัวเอง และสามารถมีหน่วยความจำเก็บประสบการณ์ได้ ดังนั้นสำหรับคนที่กำลังใช้ AI ช่วยงาน ก็ควรเริ่มฝึกสอน Agent ของตัวเอง เหมือนเราสอนเด็กฝึกงานให้ทำงานแทนเราแหละ เวลา AI ส่งงานมาเราก็ต้องคอยตรวจและแก้ไข ส่งกลับไปคอยสอนมันเรื่อย ท่องไว้ว่า "การเสียเวลาสอน Agent ในวันแรก จะช่วยคืนเวลาให้เราได้มหาศาลในวันข้างหน้า"
ไทย
虎の子 𝕏 🐯 retweetledi

ที่จริง อาจารย์ @chadchart_trip ท่านก็วิ่งทุกวันจากทองหล่อไปเสาชิงช้าหรือจากบ้านไปสวนลุมสวนเบญแต่ปัจจัยสำคัญคือ
-ทำกิจกรรมส่วนตัวนอกเวลาราชการ
-ทำงานไปด้วยออกกำลังกายไปด้วย
-Liveสดให้ประชาชนเห็นเมืองและชี้แจงปัญหาผ่านLIVEในสถานที่จริง
-เป็นประชาชนธรรมดาที่ออกมาใช้ชีวิต
#ชัชชาติ
บวรเดช เลือกมัลลิกาเป็นผู้ว่า กทม@Baworndet24761
ใกล้เลือกตั้ง กลับมาวิ่งไลฟ์สดอีกแล้ว 555
ไทย
虎の子 𝕏 🐯 retweetledi

虎の子 𝕏 🐯 retweetledi


虎の子 𝕏 🐯 retweetledi
虎の子 𝕏 🐯 retweetledi

มีเพื้อนสนิทเรียน finance, mba เราเรียนกฎหมาย มีไรก็มาแชร์ๆกัน , ข้อดีคือมันไม่ค่อยกั๊ก มีเท่าไหร่คือบอกกันหมดจิง55555555 ทำการบ้านก็ทิ้งโพยไว้ให้ตลอด ปจบมันออกมาเปนนักลงทุน เปิดธุรกิจยุบ้าน full- time ละ


ไทย
虎の子 𝕏 🐯 retweetledi

@Nobody_Knows เคยคบเด็กแว้นค่ะ มันรู้ทุกเส้นรู้ทางหนีตำรวจ แต่ไม่รู้ว่าอนาคตมันจะไปทางไหน เลยเลิกค่ะ
ไทย
虎の子 𝕏 🐯 retweetledi

เอ่อ..... UFO ว่ะ ของจริง ตอนนี้ใช้คำว่า UAP แทนแล้ว เพราะไม่มั่นใจว่ามันคือ วัตถุ (Object) หรือเปล่า เลยเรียกเป็น ปรากฏการณ์ (Phenomena)
ในนี้มีทั้งเอกสาร และภาพเลย โอเคมันไม่ได้ยืนยันว่าเอเลี่ยนมีจริง แต่ยืนยันว่ามีสิ่งที่หน่วยงานรัฐอเมริกาและพันธมิตร ไม่รู้แม่งคืออะไรอยู่จริง
Department of War 🇺🇸@DeptofWar
ไทย
虎の子 𝕏 🐯 retweetledi

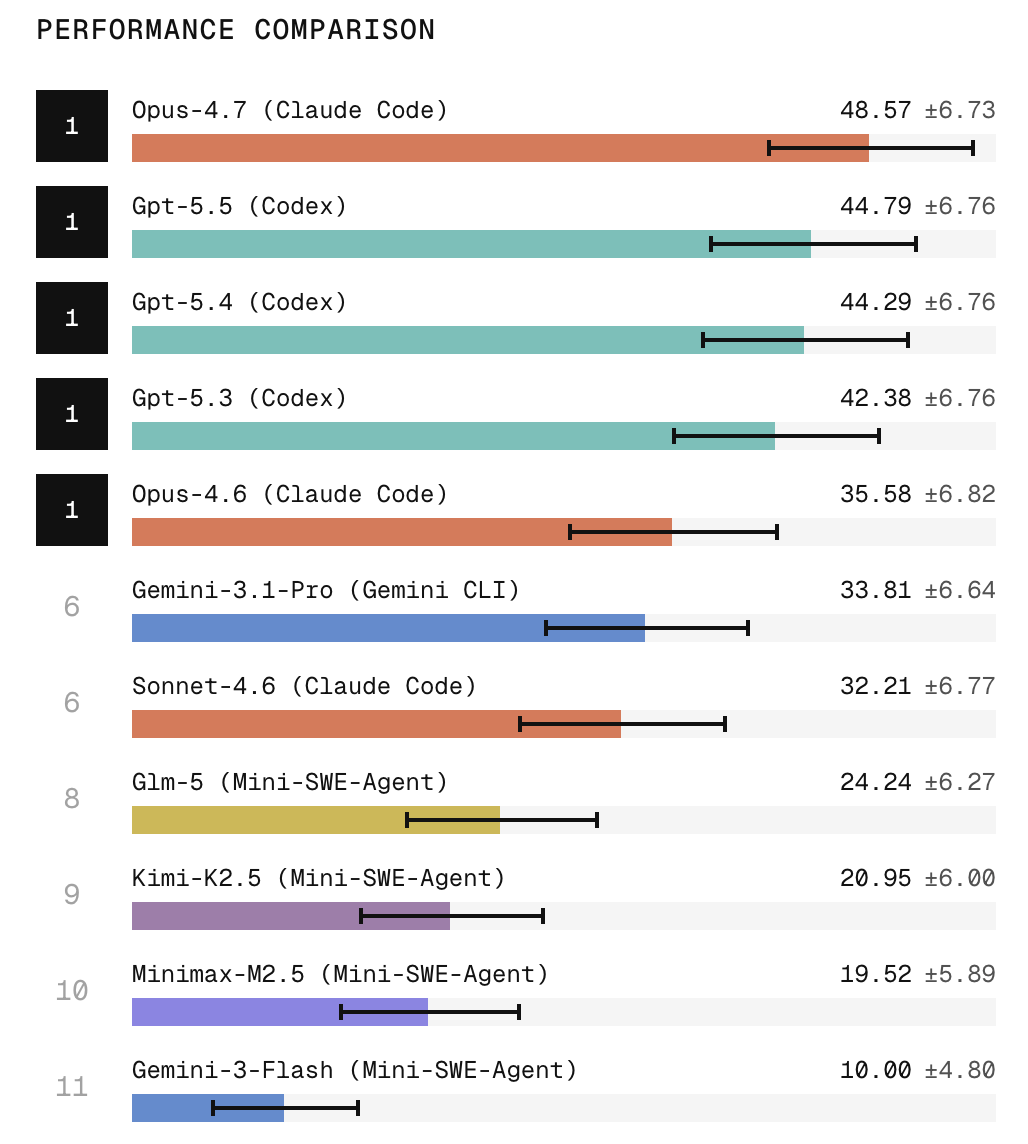
Today we’re releasing Refactoring, the final leaderboard of our SWE Atlas suite.
This new leaderboard is the ultimate test of an agent's ability to restructure code without breaking the system.
Claude Opus 4.7 with Claude Code takes the top spot🥇
English
虎の子 𝕏 🐯 retweetledi

Claude Code used 3x fewer tokens with one change:
$9.21 → $2.81
10.4M tokens → 3.7M
10 errors → ZERO
One change fixed everything:
InsForge Skills + CLI = context engineering for Claude Code.
Local. Open-source. Brutally efficient.
Repo: github.com/InsForge/InsFo…
(Star it before this blows up 🌟)
English