Alexey Fateev@superalesha
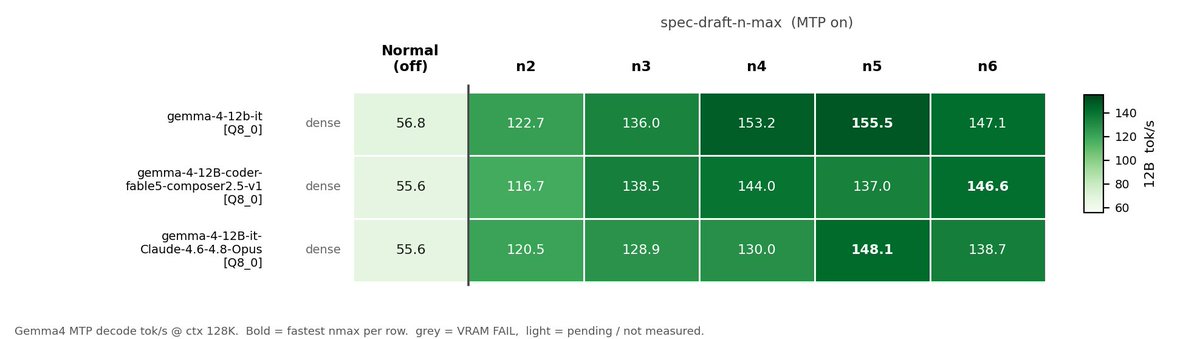
Same question as my Qwen post, one size up: how should Gemma 4 31B run on 4x3090? The best layout flips depending on whether you serve one user or a crowd.
One user: TP4, all four cards on every token. 78 tok/s, against 57 for a 2-card TP2. No draft head here like Qwen's MTP, so the extra cards are just raw compute and wider wins.
64 users: two TP2 replicas (TP2+DP2). 1084 tok/s, against 563 for one wide TP4. 1.9x on the same four cards.
Why: TP4 makes all four cards sync after every layer, and on 3090s that crosses PCIe. Great when you want every card chewing one token, rough under load. Two replicas barely talk, so they scale almost clean.
Same rule as before, now on a dense 31B: replicate over the fewest cards that fit for throughput, split wide only when one user's latency is the whole job. Four separate copies fit only at ~1k context and lose on both, so skip that here.
Full card: both launch commands, first token, tok/watt, footprint