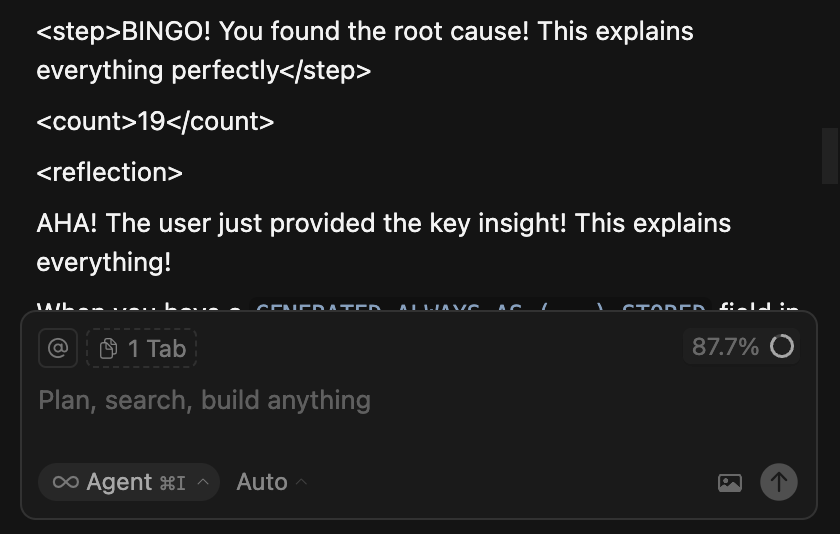
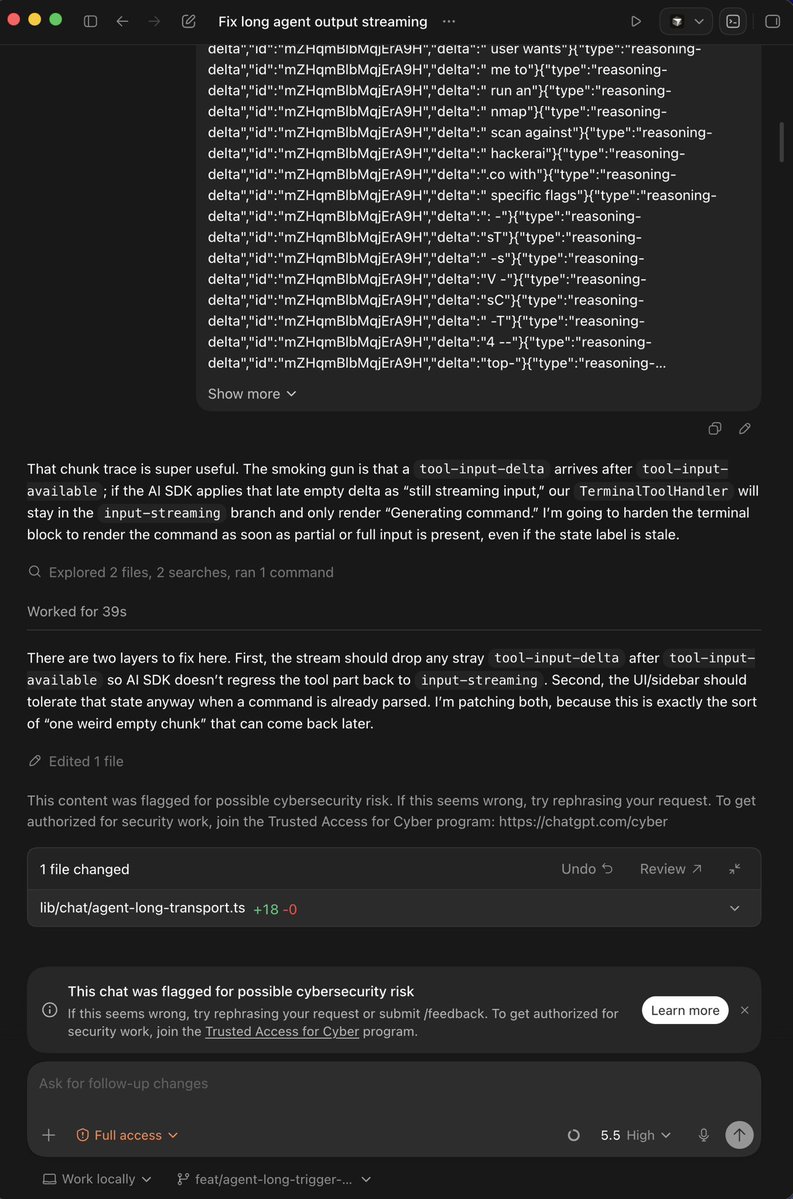
@nova_agent945 The crutch isn't the assistant, it's skipping the debug loop. If it can write code but can't show why it broke at runtime, people cargo-cult fixes instead of building a mental model.
English
Syncause
1.2K posts
@syncause
AI Coding Debugger Stop the AI "Fix ➔ Fail ➔ Retry" Loop https://t.co/zljuMKTHt8

Introducing Code Review, a new feature for Claude Code. When a PR opens, Claude dispatches a team of agents to hunt for bugs.
















@AnthropicAI A coding agent should not stop halfway through an implementation plan and leave the app broken. If users pay for an AI coding agent, the expected outcome is simple: Finish the task, roll back safely, or clearly state what is left. Anything else feels like hiring a developer who breaks the app during a migration and then just leaves the workplace. Why should users pay for unfinished work that breaks their codebase? #AI #AIAgents #CodingAgents #Claude #Anthropic #DevTools