

τao sτacker retweetledi

What does $TAO actually need to break out?
And why am I convinced it'll outperform most altcoins when the market finally turns?
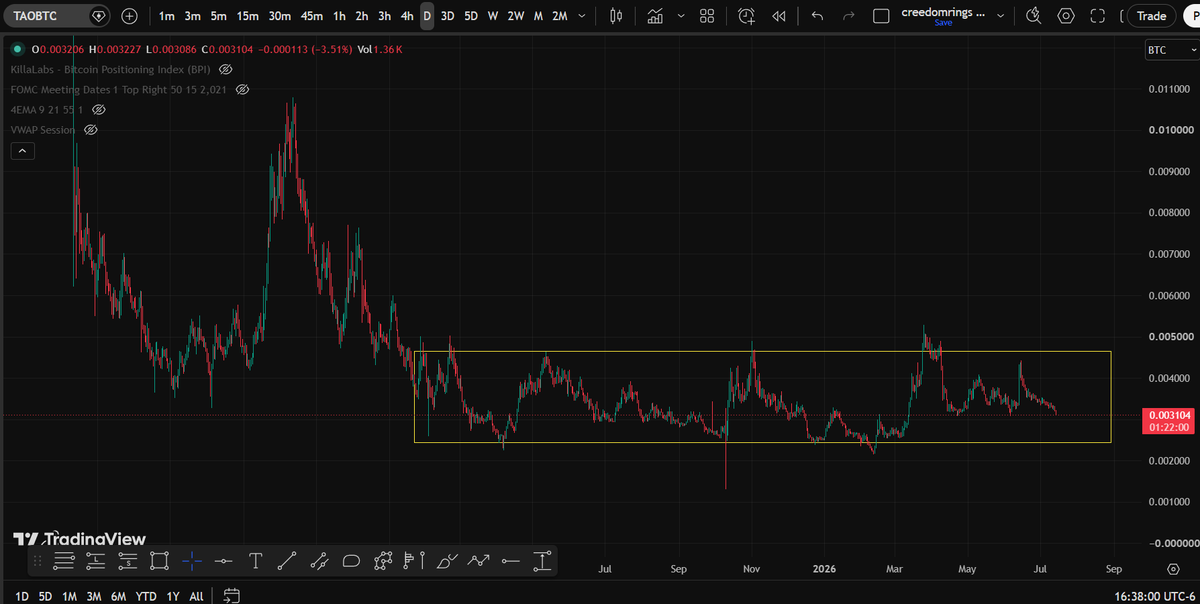
For almost 18 months, TAO has refused to break down against Bitcoin
That's extraordinary.
While 99% of altcoins have been bleeding against Bitcoin, TAO has spent the last 18 months holding the same range. ✅
That tells me one thing:
The market isn't abandoning TAO.
It's waiting.
People often think an asset isn't moving because something is wrong with the project.
Sometimes the opposite is true.
You can have improving fundamentals, growing adoption, better tokenomics, and still go nowhere...
...because the macro environment isn't ready.
In my view, that's where we are today.
I don't think TAO breaks out until Bitcoin finishes its cycle and liquidity returns to higher-risk assets.
Could I be wrong?
Of course.
But major crypto bull phases have often started after a capitulation event:
→ Mt. Gox
→ 2018 miner capitulation
→ China mining ban
→ FTX
Whether the next trigger is macro, regulation, or something nobody expects yet...
...I believe we're getting closer.
And when capital rotates back into altcoins, I'd rather own the one that spent 18 months holding its BTC value than one that's been bleeding against Bitcoin the entire time.
Relative strength matters.
$TAO #Bittensor
English

















