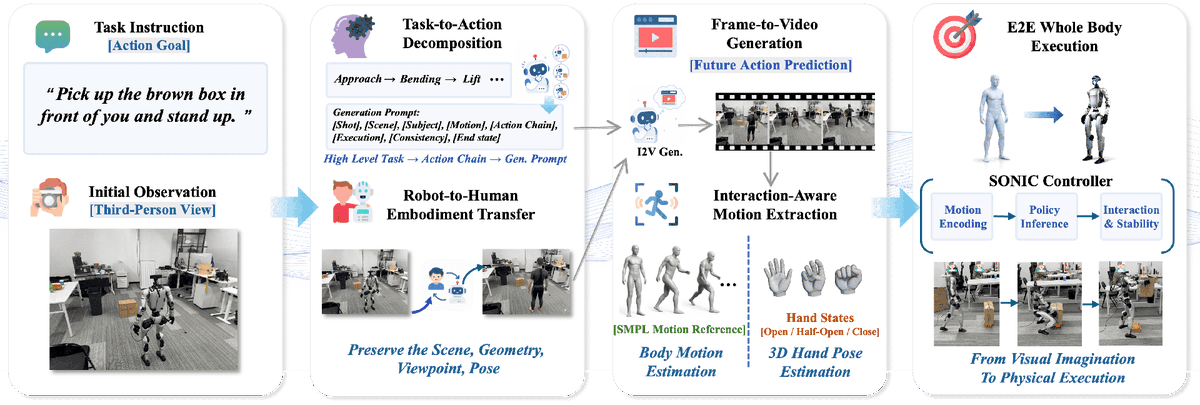
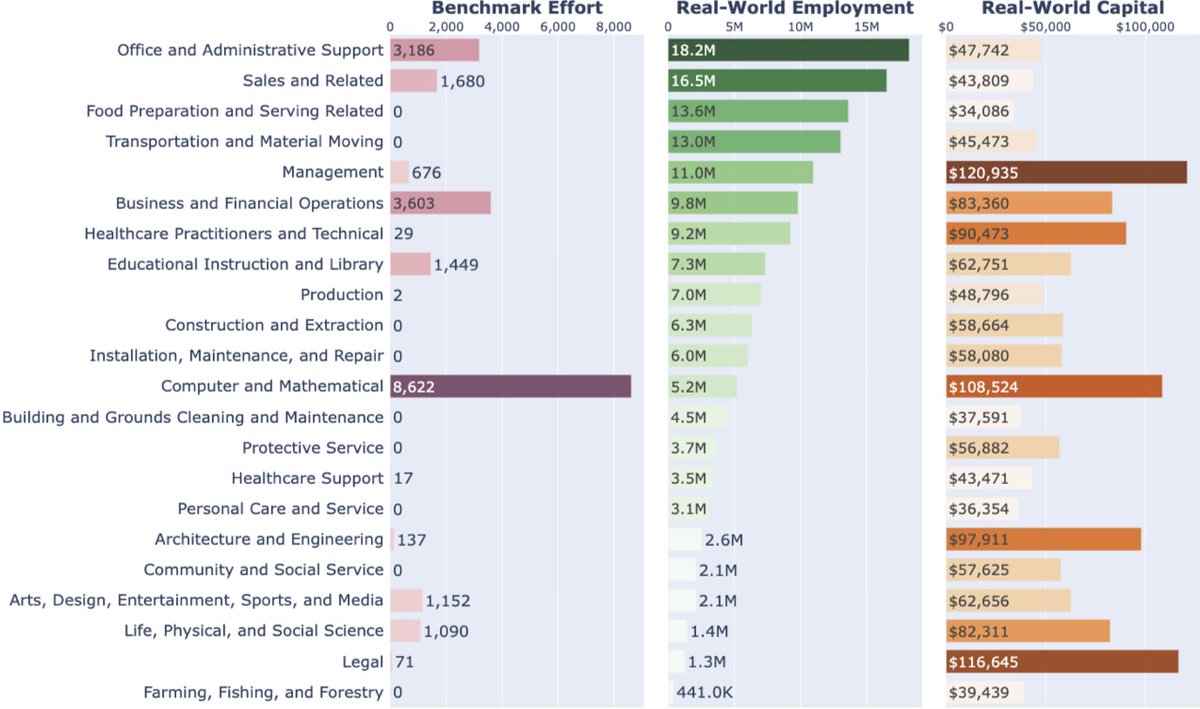
Sabitlenmiş Tweet

What if agents leverage recent LMM capabilties for general computer control, instead of using target-specific APIs?
In our recent research, Cradle, we explore foundation agents acing diverse computer tasks, and demo their capabilities by playing RDR2.
arxiv.org/abs/2403.03186

English