Sabitlenmiş Tweet
tsuki
1.7K posts


tsuki
@tensorcore
Hiroyuki Ootomo. High-precision GEMM emulation on Tensor Cores. Work at #76B900. Cooking @cp_async. Hai-to-Yoka: https://t.co/jAdudlZfnb
Tokyo, Japan Katılım Kasım 2017
461 Takip Edilen3.3K Takipçiler
tsuki retweetledi


@tensorcore goals > ethics, or how niccolo machiavelli said:
the ends jusrify the means
English
I just got a review request for the same paper again, but from a different journal this time... What is wrong with the authors' ethics?
tsuki@tensorcore
thinking about the appropriate action to take when reviewing a paper that contains clear instances of plagiarism… Is it more appropriate to require a detailed explanation from the authors, or simply to recommend rejection?
English
tsuki retweetledi

テックブログ公開 Day5です
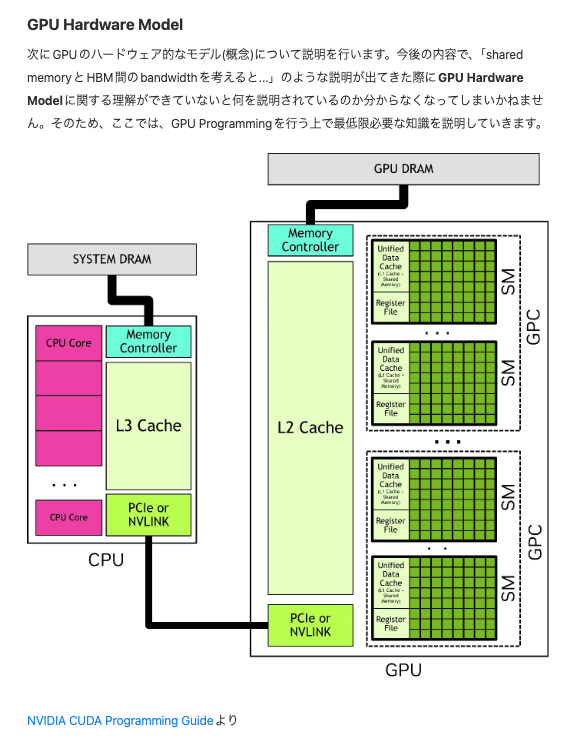
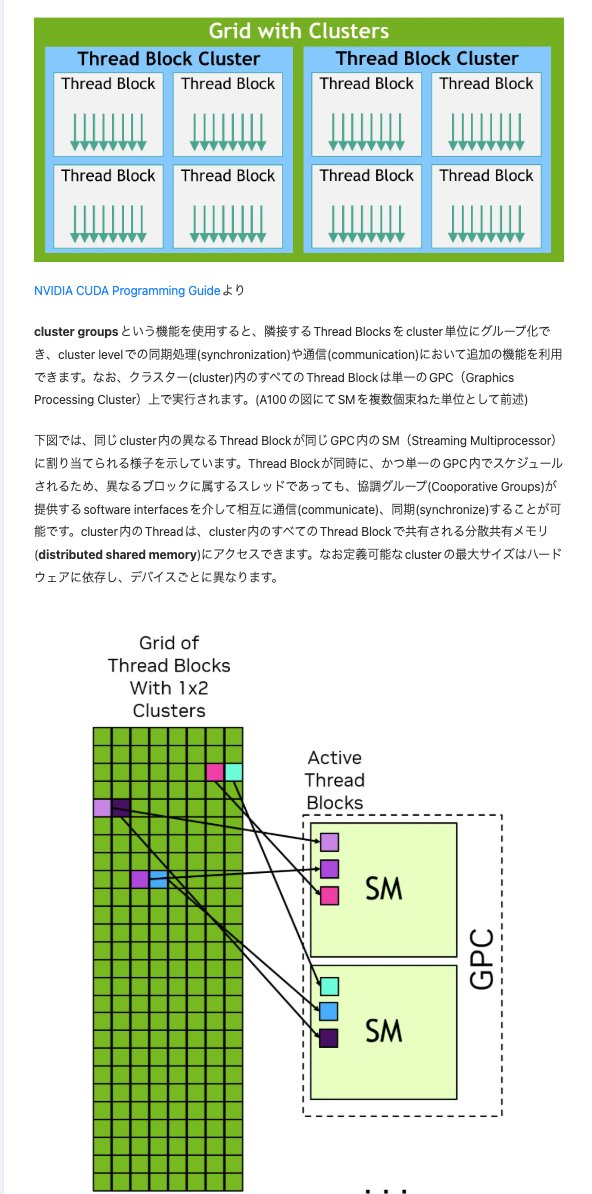
FlashAttentionや昨今のHardware Awareな高速化手法を理解したり、提案したりする上で必須となるCUDA Programmingに関して、基礎から解説していくブログシリーズの第一弾です。3万字超えのブログですが、かなり分かりやすく書いていますのでぜひご覧ください。
CUDA Programming Guide Part 1|Kazuki Fujii zenn.dev/kaz20/articles…
Kazuki Fujii@kazukifujii
テックブログ公開 Day4です。 RLVR(強化学習)時代において欠かすことのできないweight syncの機能についてvLLMがどのようにこれを実現しているのかやさしく解説を行いました。 RLVR時代におけるInference Framework: Weight Syncing編|Kazuki Fujii zenn.dev/kaz20/articles…
日本語
tsuki retweetledi

Don't miss our upcoming Supercomputing Spotlights webinar! Laura Grigori will be speaking about "Randomized mixed precision algorithms for large scale linear algebra problems" on June 10, 2pm UTC!
More details + registration link here: siag-sc.org/randomized-mix…
English


tsuki retweetledi

Finally, huge thanks to the incredible team: @jcz42, Arjun, Driss, @tensorcore, @yoonrkim, and @tri_dao!
PDF: arxiv.org/abs/2605.19269
Code: github.com/HanGuo97/coda-…
English
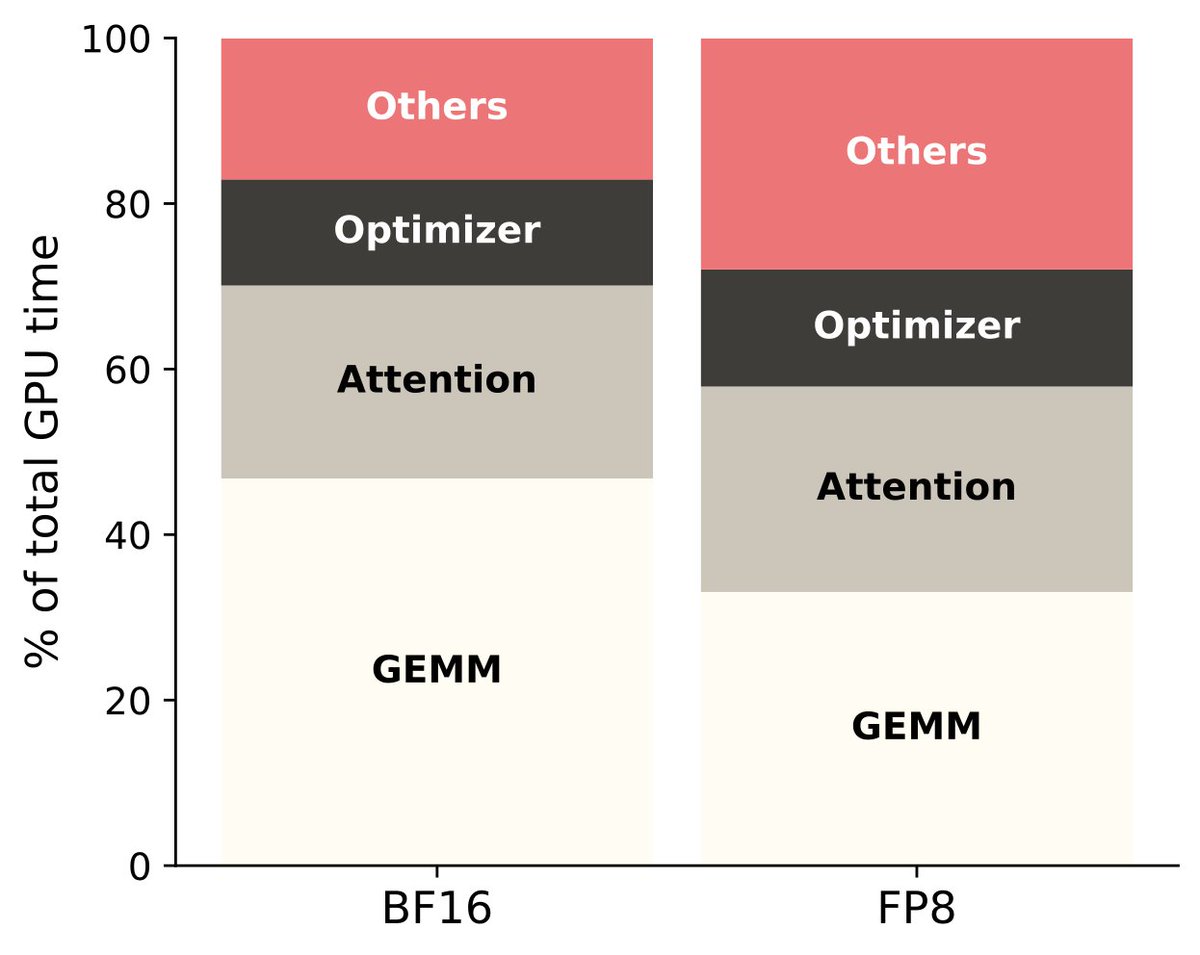
LLM training is dominated by compute-heavy ops like MatMuls and attention.
But it also has many memory-heavy ops: norms, activations, residuals, reductions. These mostly move tensors around.
As FP8/NVFP4 make FLOPs cheaper, data movement gets harder to ignore.
Fig: ~1B LLaMA-3 training
English







