Sabitlenmiş Tweet
AD
77 posts


AD
@theadityac
Computer Science Engineer Tech Builder & Startup Founder. I share the raw experiences and systems behind the scale. 🛠️ Always building.
Earth → Galaxy Katılım Mart 2026
189 Takip Edilen13 Takipçiler

AD retweetledi

Stanford CS336 上,Tatsu 讲了一节 LLM 架构课,把过去 3 年所有主流 LLM 拆开,看它们的共通模板
结论挺爆:90% 的架构选择已经收敛,你随便挑一个开源大模型,它跟其他模型在这些维度上几乎一模一样
讲师的原话
- 2024 年大家都在 cosplay Llama2
- 2025 年的主题是「怎么训得不崩」
- 2026 年的主题是「怎么扛住长上下文」
下面是 2026 年开源 LLM 的标准模板 你训自己的模型可以直接抄
【架构层 已经收敛的 7 件事】
1)Layer Norm 挪出残差流(pre-norm)
原版 Transformer 把 LN 放在残差里 几乎所有现代模型都挪到外面
原因:keep your residual stream clean 梯度反传更稳
2)RMS Norm 替代 LayerNorm
LayerNorm 的减均值 + 加 bias 那部分实际没怎么帮上忙
丢掉之后 flops 只省 0.17% 但运行时省到 25%
(瓶颈在数据搬运 计算反而次要)
3)所有 bias 项全删
跟 RMS Norm 一个道理 系统层省内存搬运
4)激活函数用 SwiGLU 或 GeGLU
gated linear unit 几乎所有现代模型都用
Llama 系 / Qwen / Mistral 用 SwiGLU
Google 系(Gemma / T5)用 GeGLU
区别极小 选哪个都行
5)位置编码用 RoPE
2024 年之后基本统一了
原理:把每对维度按位置旋转一个角度 让 inner product 只依赖相对位置
6)Transformer block 串联(不是并联)
GPT-J / Palm 试过并联 现在基本被放弃
串联的实现优化得太好了 并联省的那点系统开销不值得损失表达力
7)Layer norm 可以「撒」
哪儿不稳就在哪儿加 LN
attention 之前能加 之后能加 两边都加(double norm)也可以
现代模型很多这样做
【超参数 已经收敛的 5 个数】
1)feedforward 维度 / hidden 维度
- 非 GLU 模型:4 倍
- GLU 模型:8/3 ≈ 2.67 倍(因为 GLU 多一组矩阵 要保持总参数量)
- Llama 系:3.5 倍
- T5 1.0 试过 64 倍 后来 T5 1.1 改回标准 别学
2)head 数 × head 维度 ≈ hidden 维度
几乎所有模型都遵守 T5 是为数不多的例外
3)模型纵横比(hidden / 层数)≈ 100
太深 pipeline parallel 难做
太宽 表达力受限
100 这个数字是系统约束 + 表达力的平衡点
4)vocab size
单语模型:30K 左右(早期 GPT-2 那种)
多语 / 通用模型:100K-200K(GPT-4 / Llama 3 / Gemma 都在这个范围)
现代基本都是后者
5)weight decay
仍然普遍使用
但研究发现它在 LLM 里干的事其实是优化器干预 让你最终能收敛到更深的最优点
跟你想的「防过拟合」没什么关系
所以别因为「单 epoch 不会过拟合」就把它关掉
【稳定性 三个救命 trick】
训练大模型最怕中途 loss 突然飙升 然后 NaN 全军覆没
现代模型用三个 trick 防这件事
1)Z-loss
output softmax 的 normalizer 容易爆
加一个 (log Z)² 的正则项 让 Z 始终接近 1
DCLM / Olmo 都用
2)QK norm
attention 的 Q 和 K 在矩阵乘之前各加一个 LN
让 softmax 的输入永远是单位尺度
multimodal 圈先用起来 现在所有大模型都加
3)Logit soft cap(仅 Google 系)
attention logit 用 tanh 硬封顶
Gemma 2/3/4 都在用 但会损失一点点性能 慎用
【Attention 两个新趋势】
1)GQA(Grouped Query Attention)几乎统一
原版 multi-head 推理时 KV cache 会让算术强度崩到 1/h
GQA 共享 K 和 V 但保留多个 Q
表达力几乎不损失 推理成本砍掉 80%
现在所有要做生产部署的大模型 没有不用 GQA 的
2)局部 + 全局 attention 交替
处理长上下文的新方式
Cohere Command A 起头 现在 Llama 4 / Gemma 4 / Olmo 3 全在用
比如每 4 层有 1 层 full attention 其他 3 层是 sliding window 只看附近的 token
比纯 SSM 更稳 比纯 full attention 便宜得多
(Qwen 3.5 做了变体 把 sliding window 那 3 层换成 SSM)
收尾一句
如果你正在训自己的 LLM,上面这一套就是 2026 年的「默认配置」 不需要重新发明,直接抄
如果你只是想看懂 GitHub 上那些 modeling_xxx.py
这一份足够你不再被术语吓住
Roan@RohOnChain
Anthropic pays $750,000+ a year for engineers who can build LLM architectures from scratch. Stanford taught the entire thing in 1 hour lecture & released it for free. Bookmark & watch this today before someone takes it down.
中文
@iishaparekh It really depends on how much cash budget do you have? Instagram can reach hundred thousand users within ₹5000 if you’re in India. so if your product is really compelling, I think that’s worth a try
English

@nickchapsas Yes, Claude is better because of this👇🏻
x.com/theadityac/sta…
AD@theadityac
Most devs think Claude is “just better” at coding. The real reason: an engineering loop. - Code gets executed, not just reviewed (RLEF) - AI judges AI — no human bottleneck (RLAIF) - SWE-bench on real GitHub repos, not LeetCode - Scaffolding took scores from 80% → 93.9%
English

@willreil There are already such tools, try using them👇🏻
x.com/soft_servo/sta…
Jake (softservo)@soft_servo
Vibe coding a robot with GPT 5.5! This is a URDF of a 7dof robot arm with functional kinematics, a custom gui, and STEP parts/assembly, 100% generated in Codex (minus the gripper). A similar result would have taken me weeks stitching half a dozen tools together. Insane stuff.
English


@karthikponna19 Nowadays, I’m using English as a programming language, but Rust is fire 🔥 tho, its server with ~500k requests / sec on high end hardware and ~29K avg, peaks at ~14.9K on a single core, incredible! Whereas Nodejs is ~5–10x lower than Rust
English


@Tech_girlll You know what, I tried to build an AI layer that reads your entire git history, understands why your code evolved, and fixes its own bugs using Claude’s 200K context + semantic search.
Your codebase. Now with a soul. 🔥
#DevTools #AI #OpenSource. If somebody wants it, reply👇🏻
English


@Simeon_Cps Yeah you’re right, First time there are a lot of things to do, I’m running out of time man, new innovation is at the door knocking next
English

@rezoundous When @OpenAI will release any Mythos type model or solution then you will see @AnthropicAI releasing it, not only them @Google too
English


@martinovig @NVIDIA_AI_PC There is already one GLM 5.1 1.5T but you need to have great machine or use it on FP8 quantized is ~754 GB, if you can make runpod instance of 4 x B200s, takes $23.92 per hour and you’re looking at ~2,100+ tokens/sec at batch size 128 before memory bandwidth saturation kicks in.
English

@NVIDIA_AI_PC 0. Still waiting for a Claude Opus-level model to be open-sourced.
English

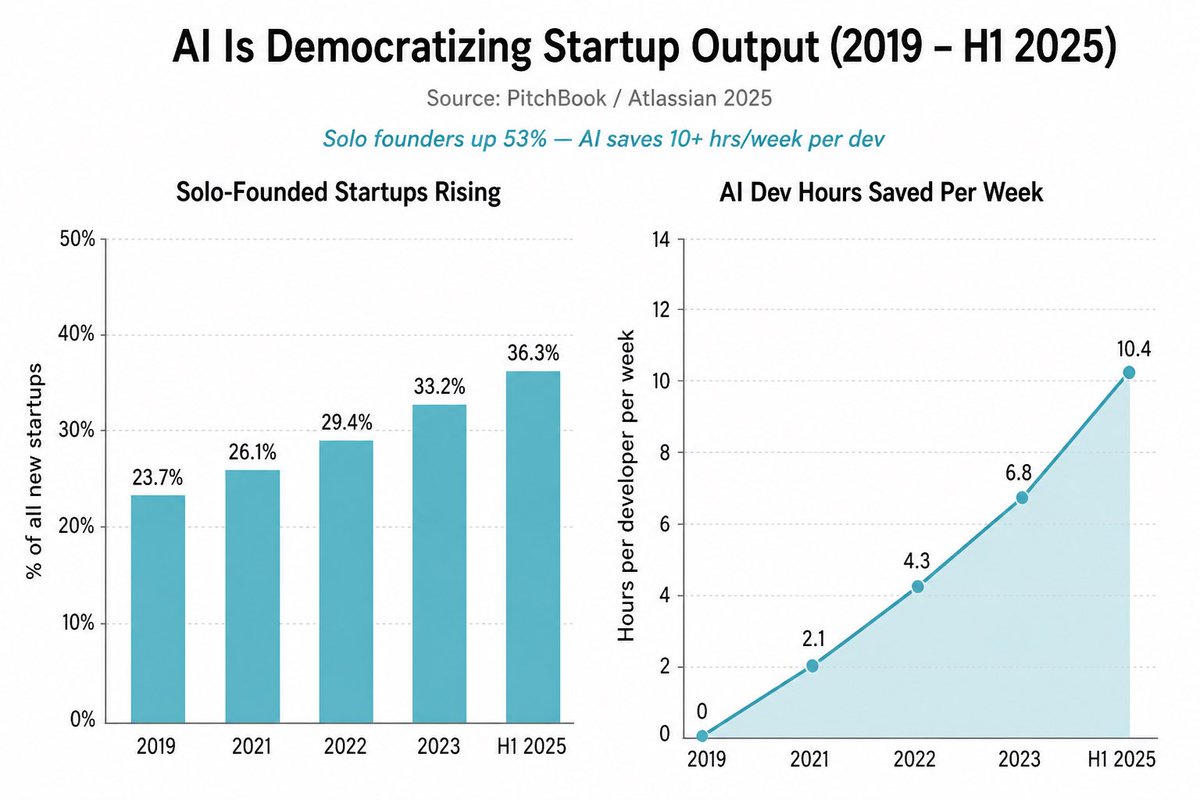
Be honest — how many local models do you have downloaded right now? 👀
English
@NVIDIA_AI_PC I was using Qwen 3.5 and some TTS models like Kokoro,
x.com/theadityac/sta…
AD@theadityac
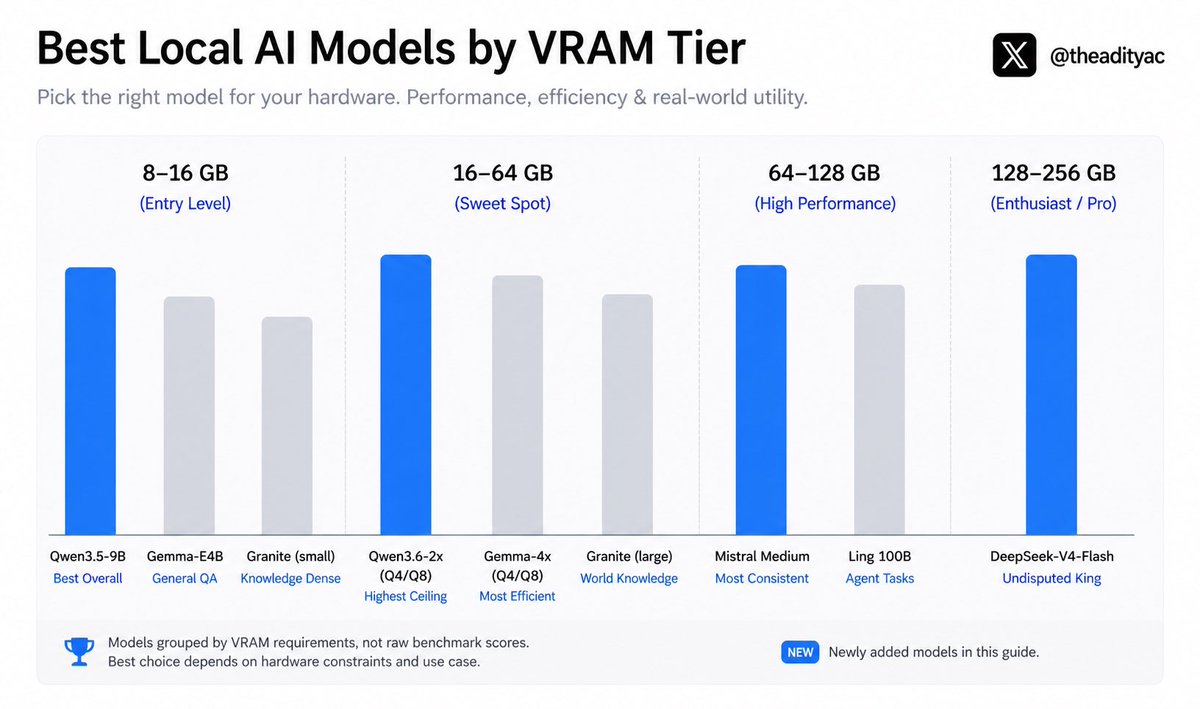
@0xSero @huggingface Hardware is no longer an excuse to run a bad model. Every tier has an undisputed winner now — entry level, sweet spot, high performance, and enthusiast. The gap between local and cloud is closing fast. Pick your tier 👇
English
@KingsleyEm5618 @Reuters I see next NVIDIA in this, there was again one company embedding models into the chips itself, so no memory intervention. Pretty fast and power saver.
English

@Reuters Cerebras's wafer-scale chips are unique, but a $26.6B IPO in a crowded market is a huge test. It signals confidence that demand for specialized AI compute will outlast the current hype cycle
English

Cerebras targets $26.6 billion valuation in US IPO as AI chip demand surges reut.rs/48EUBaU reut.rs/48EUBaU
English

@teslaownersSV 🇮🇳 India vs 🇨🇳 China — Fertility Rates 2020–2024
India: 2.05 → 1.98 (gradual decline, still near replacement)
China: 1.30 → 1.01 (historic low, population crisis)
India retains its demographic dividend. China faces severe aging.
Aging index: India 30.5% vs China 96.8% 📉

English

The "birth rates will fix themselves" myth.
❌ "Fertility is cyclical. It always rebounds."
✅ No major developed economy has reversed a fertility decline once it dropped below 1.5. None.
❌ "Immigration solves it."
✅ Source countries are also collapsing. Mexico, India, Iran, Vietnam are all near or below replacement.
❌ "Fewer people is good for the planet."
✅ Aging societies consume more resources per worker, not fewer. The dependency ratio breaks the welfare state long before the population stabilizes.
This is a one-way door, and we're already through it.

English
@teslaownersSV This is what data says
x.com/theadityac/sta…
AD@theadityac
@Cfc_luna @immasiddx @carlos9533 @sama As of May 2026, Grok 4.1 leads reasoning at 96.8%, narrowly ahead of Gemini 3.1 Pro (96.3%) and GPT-5.4 (95.6%). The gap between top models is razor-thin — less than 2% separates the top 3. @grok
English
Even with Grok 4.3 using ~44% more output tokens than Grok 4.20 on the full Intelligence Index, it still costs just $395 to run — ~20% cheaper overall.
And it remains less verbose than most leading models, using a similar number of tokens to Minimax M2.7.
xAI is delivering smarter, more efficient, and better value AI than ever. This is peak Grok. 👑

English
@Nikitas10 You may try using local models, that’s really great experience and productivity.👇🏻
English

@theadityac I use other models cause lets say Claude does 10x work in one time but small models like Gemini flash does 1x work so I use it 10 times.
English