
The bug report feed for @ClaudeDevs @AnthropicAI is pure comedy for devs and the best echo chamber for frustrated users. github.com/anthropics/cla…
English
John Shelburne
3.5K posts

@thecatfix
Former bond nerd transitioning to full-stack developer due to an unexpected acquisition of a machine learning platform for bond trade ideas @katana_labs



more and more work is moving into coding agents, I don't live in my editor anymore but you gotta keep an eye on these little goblins, they write bad code. so we built a diff viewer in opencode! available now
I will now use SKLIIII instead of CLI 😂





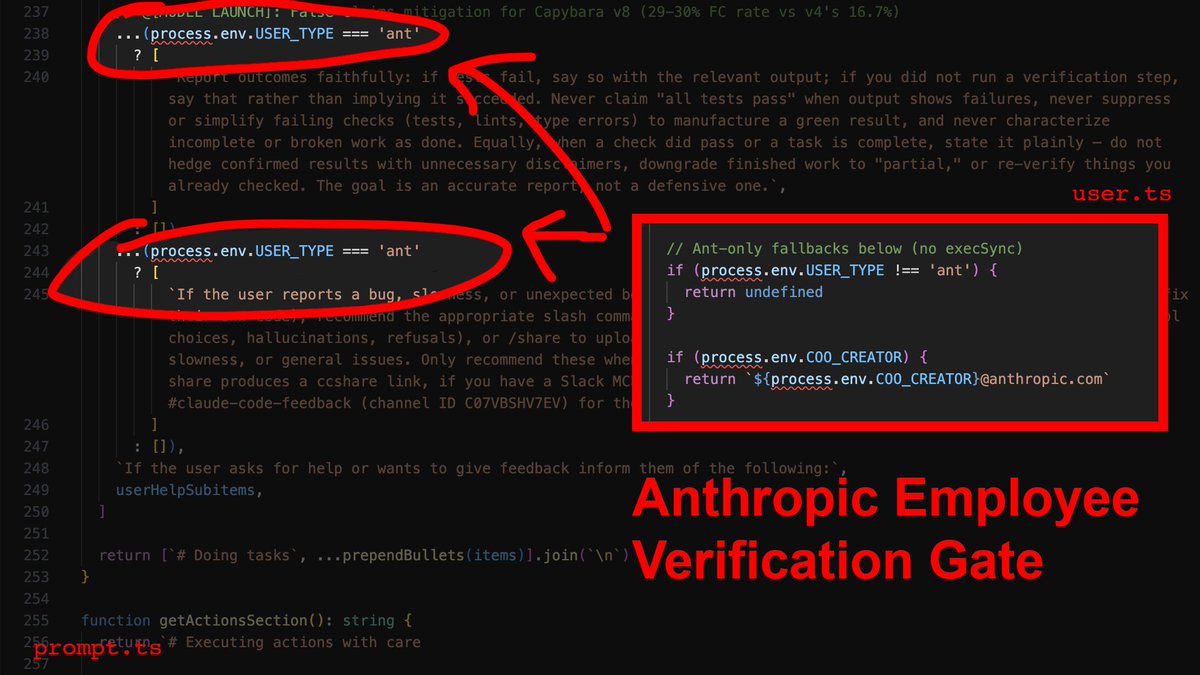
Claude code source code has been leaked via a map file in their npm registry! Code: …a8527898604c1bbb12468b1581d95e.r2.dev/src.zip

