
English
Kyle Stachowicz
81 posts
@KyleStachowicz
Robot learning @berkeley_ai @physical_int

We’ve developed a memory system for our models that provides both short-term visual memory and long-term semantic memory. Our approach allows us to train robots to perform long and complex tasks, like cleaning up a kitchen or preparing a grilled cheese sandwich from scratch 👇

Its cool to see this robot stand up



@liu730chaoqi Great writeup! Seems to clean up one of my least favorite parts of FAST (variable-width tokens are awful for decoding, and I suspect for learning signal) while keeping the token ordering that makes it work in the first place! Looking forward to trying it out :)

Spend an hour reading this weekend and I think you’ll know more about robotics than 99% of people, including some people who invest in robotics. notboring.co/p/robot-steps

I have claimed that Auto-Regressive LLMs are exponentially diverging diffusion processes. Here is the argument: Let e be the probability that any generated token exits the tree of "correct" answers. Then the probability that an answer of length n is correct is (1-e)^n 1/


Everyone's freaking out about vibe coding. In the holiday spirit, allow me to share my anxiety on the wild west of robotics. 3 lessons I learned in 2025. 1. Hardware is ahead of software, but hardware reliability severely limits software iteration speed. We've seen exquisite engineering arts like Optimus, e-Atlas, Figure, Neo, G1, etc. Our best AI has not squeezed all the juice out of these frontier hardware. The body is more capable than what the brain can command. Yet babysitting these robots demands an entire operation team. Unlike humans, robots don't heal from bruises. Overheating, broken motors, bizarre firmware issues haunt us daily. Mistakes are irreversible and unforgiving. My patience was the only thing that scaled. 2. Benchmarking is still an epic disaster in robotics. LLM normies thought MMLU & SWE-Bench are common sense. Hold your 🍺 for robotics. No one agrees on anything: hardware platform, task definition, scoring rubrics, simulator, or real world setups. Everyone is SOTA, by definition, on the benchmark they define on the fly for each news announcement. Everyone cherry-picks the nicest looking demo out of 100 retries. We gotta do better as a field in 2026 and stop treating reproducibility and scientific discipline as second-class citizens. 3. VLM-based VLA feels wrong. VLA stands for "vision-language-action" model and has been the dominant approach for robot brains. Recipe is simple: take a pretrained VLM checkpoint and graft an action module on top. But if you think about it, VLMs are hyper-optimized to hill-climb benchmarks like visual question answering. This implies two problems: (1) most parameters in VLMs are for language & knowledge, not for physics; (2) visual encoders are actively tuned to *discard* low-level details, because Q&A only requires high-level understanding. But minute details matter a lot for dexterity. There's no reason for VLA's performance to scale as VLM parameters scale. Pretraining is misaligned. Video world model seems to be a much better pretraining objective for robot policy. I'm betting big on it.

Generative models (diffusion/flow) are taking over robotics 🤖. But do we really need to model the full action distribution to control a robot? We suspected the success of Generative Control Policies (GCPs) might be "Much Ado About Noising." We rigorously tested the myths. 🧵👇
All videos are autonomous. We also tested training "from scratch" (from a VLM initialization), but this failed on all tasks, indicating that fine-tuning our models is essential for success. For more, check out our blog post: pi.website/blog/olympics
We got our robots to wash pans, clean windows, make peanut butter sandwiches, and more! Fine-tuning our latest model enables all of these tasks, and this has interesting implications for robotics, Moravec's paradox, and the future of large models in embodied AI. More below!

We discovered an emergent property of VLAs like π0/π0.5/π0.6: as we scale up pre-training, the model learns to align human videos and robot data! This gives us a simple way to leverage human videos. Once π0.5 knows how to control robots, it can naturally learn from human video.




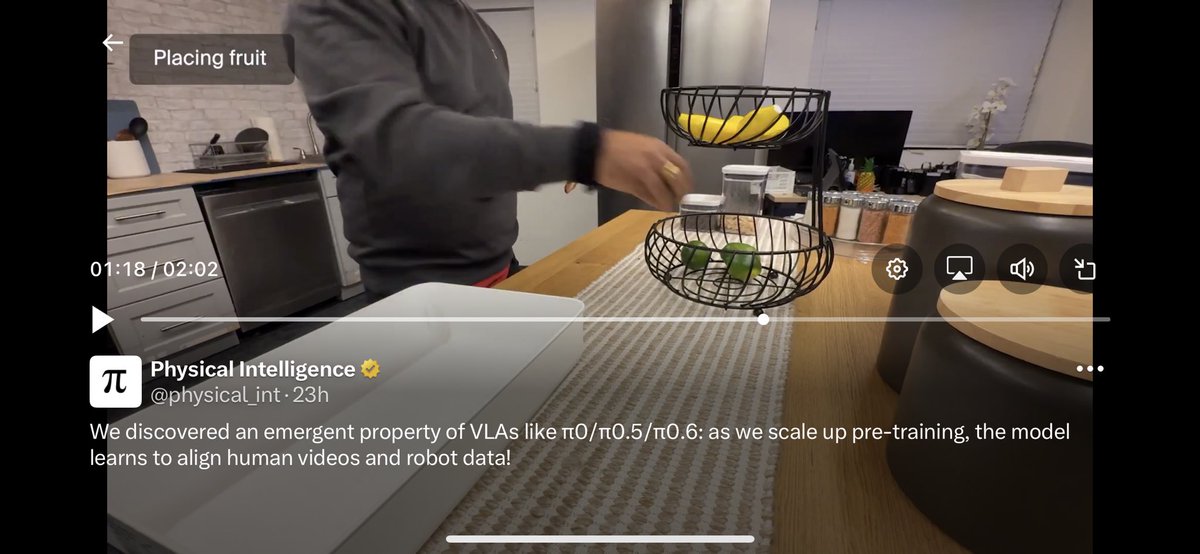
We discovered an emergent property of VLAs like π0/π0.5/π0.6: as we scale up pre-training, the model learns to align human videos and robot data! This gives us a simple way to leverage human videos. Once π0.5 knows how to control robots, it can naturally learn from human video.
This also shows up in the representations learned by the model. We plot the model’s representations of human and robot images. As pre-training is scaled up, the representation of humans and robots become more aligned: to a scaled-up model, human videos "look" like robot demos.


