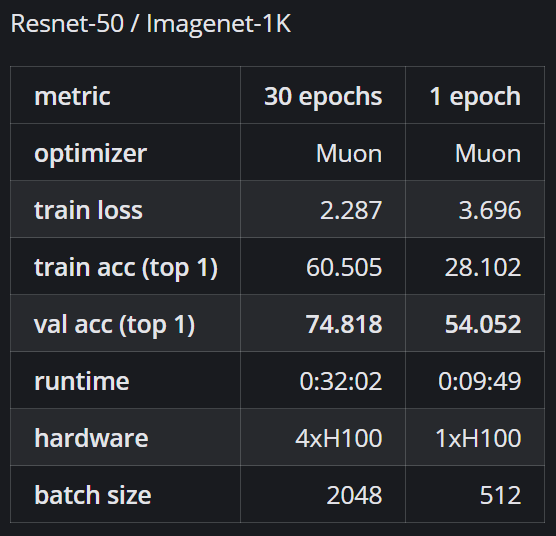
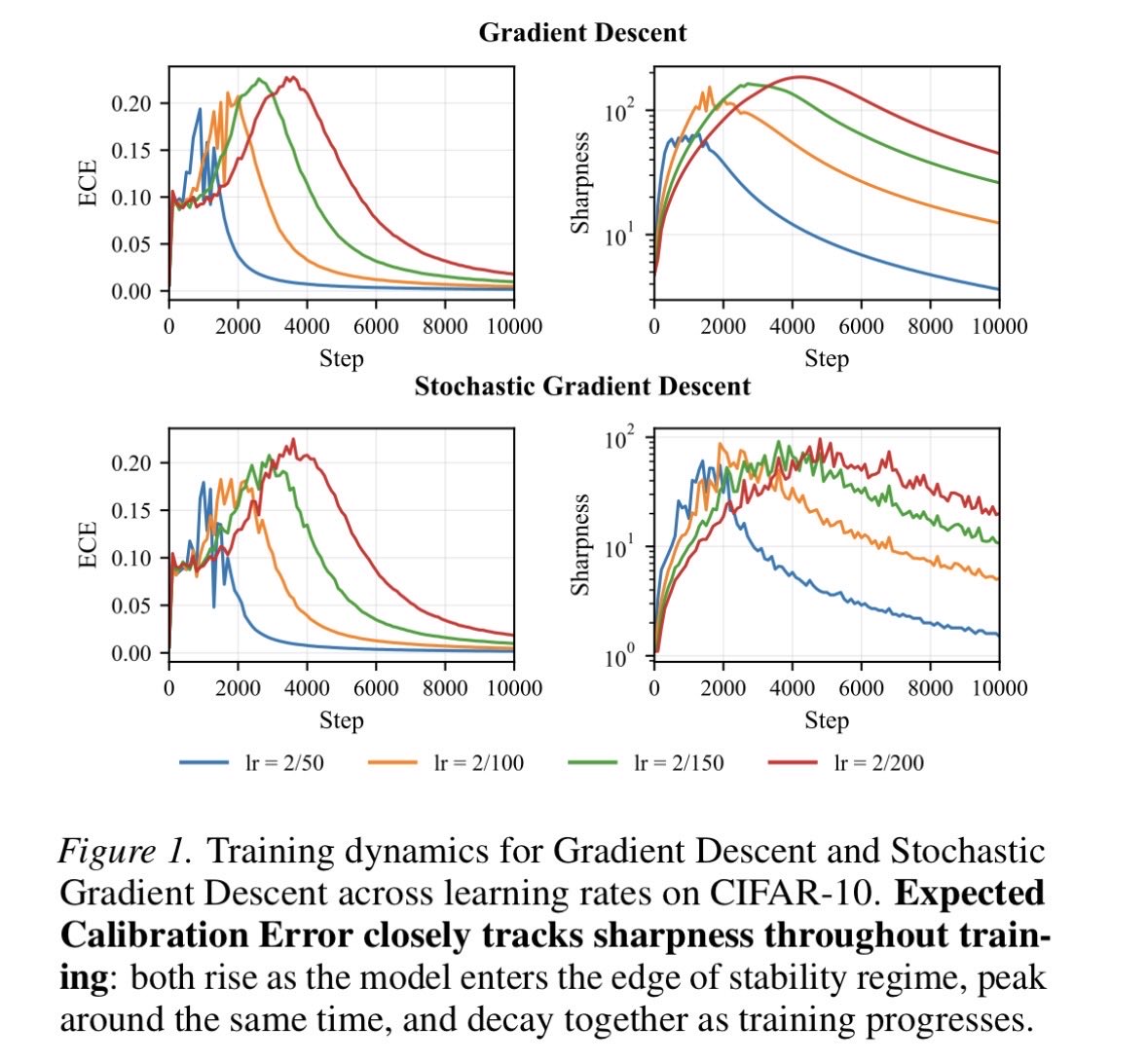
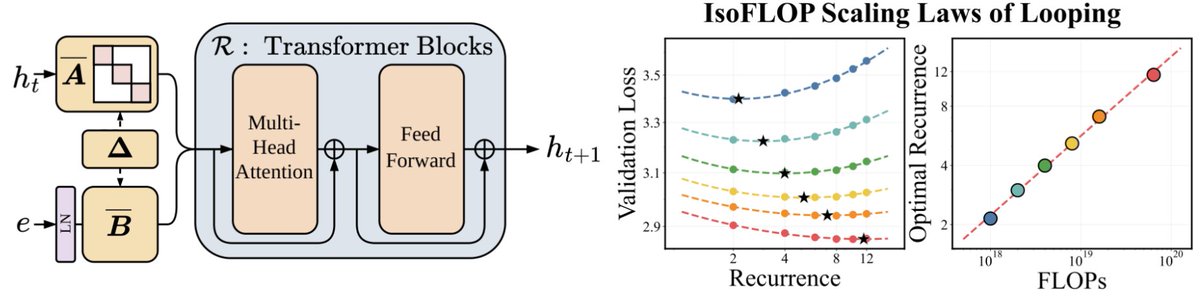
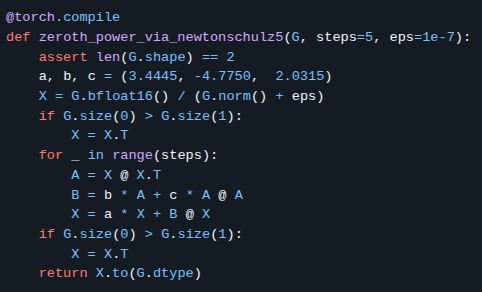
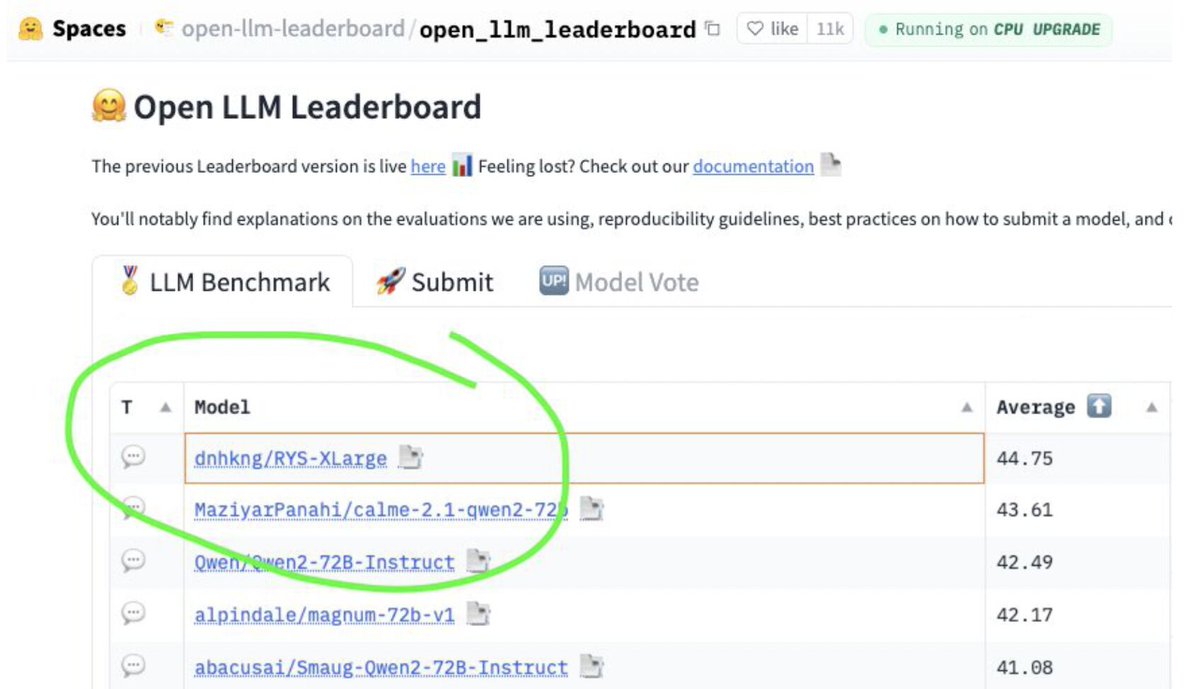
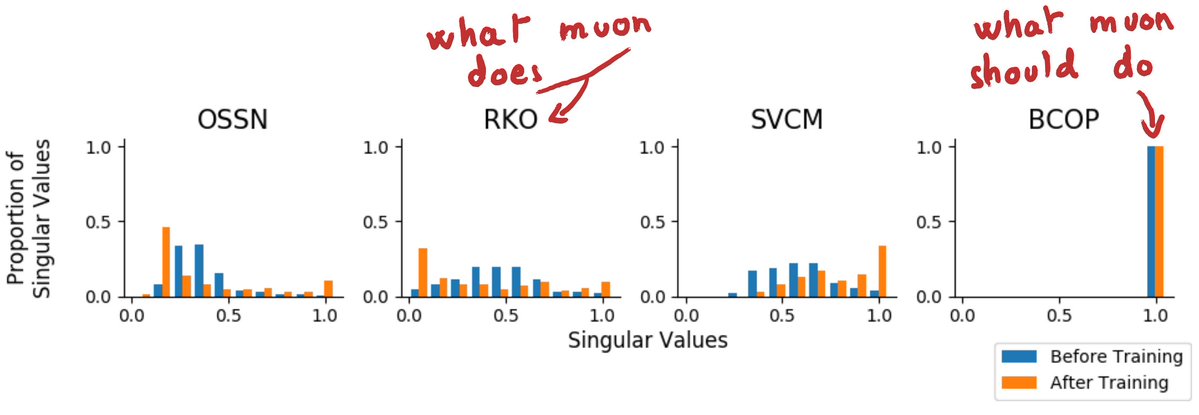
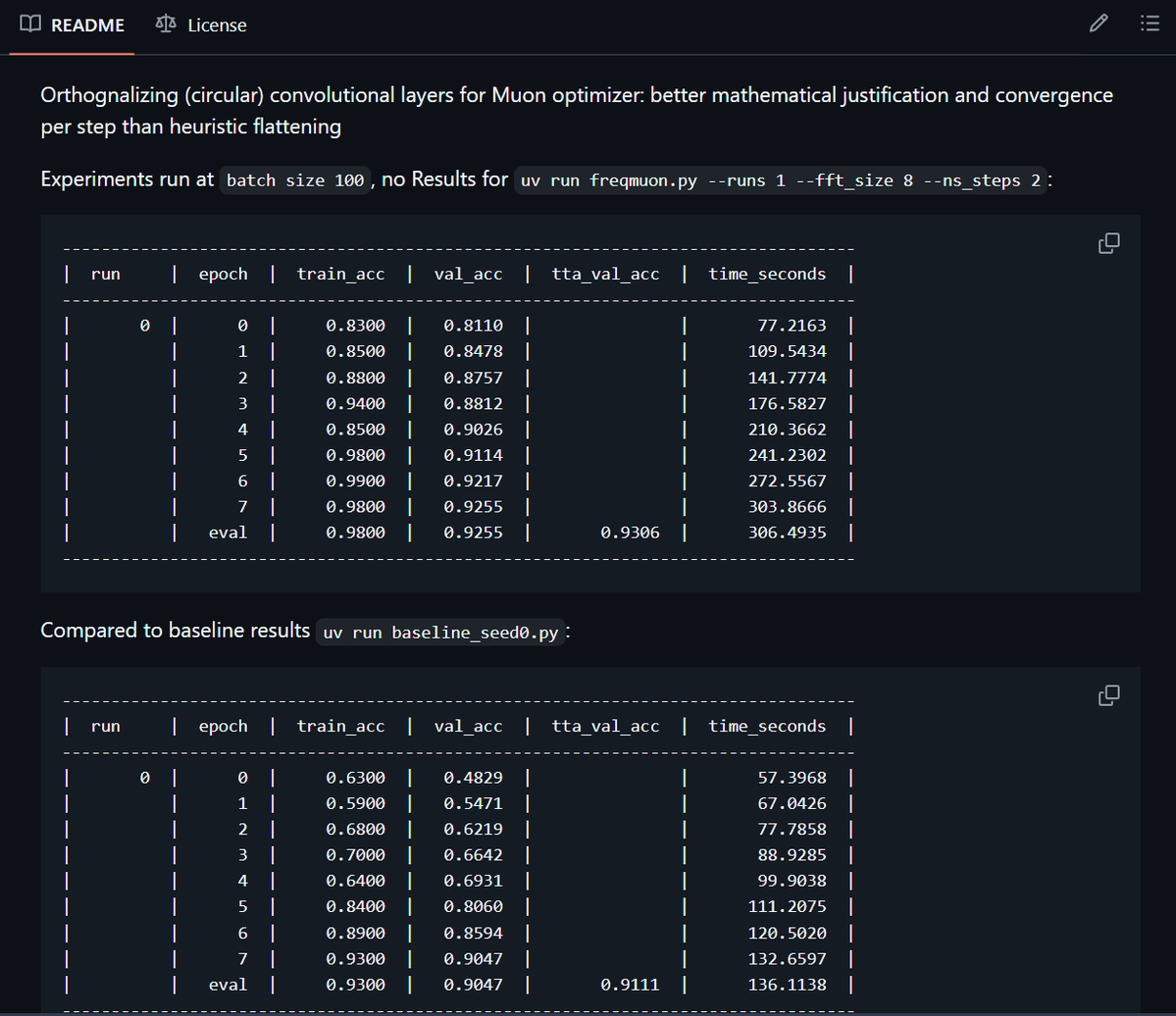
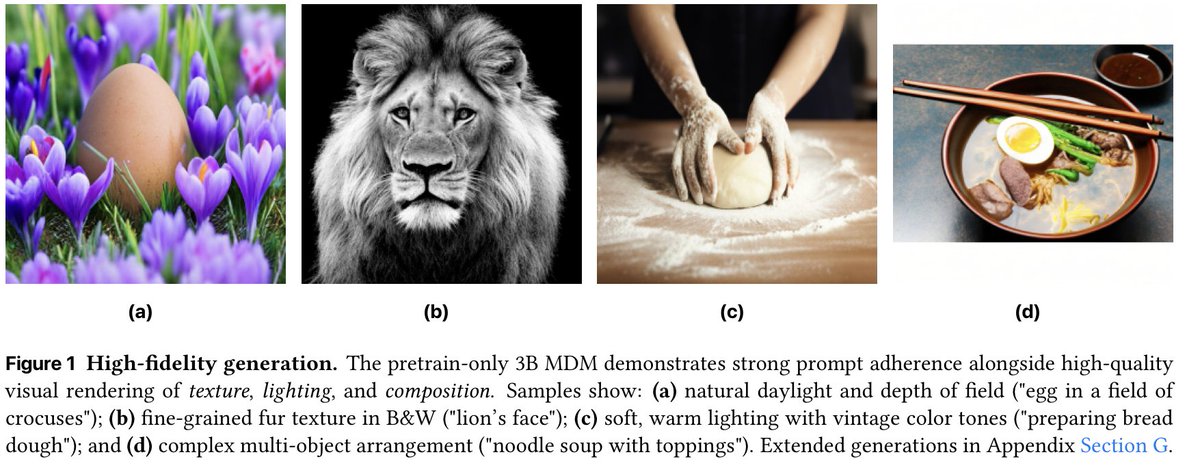
Sabitlenmiş Tweet

Wrote my first blog post, turns out exploring adaptive orthogonalization methods is pretty fun.
massena-t.github.io/blog/2026/02/1…
TLDR: Using an adaptive Newton-Schulz scheme allows a theoretically principled way to choose between SGD-esque or Muon-esque weight updates.
English