Sabitlenmiş Tweet

AI, shaped by humanity.
Y Combinator@ycombinator
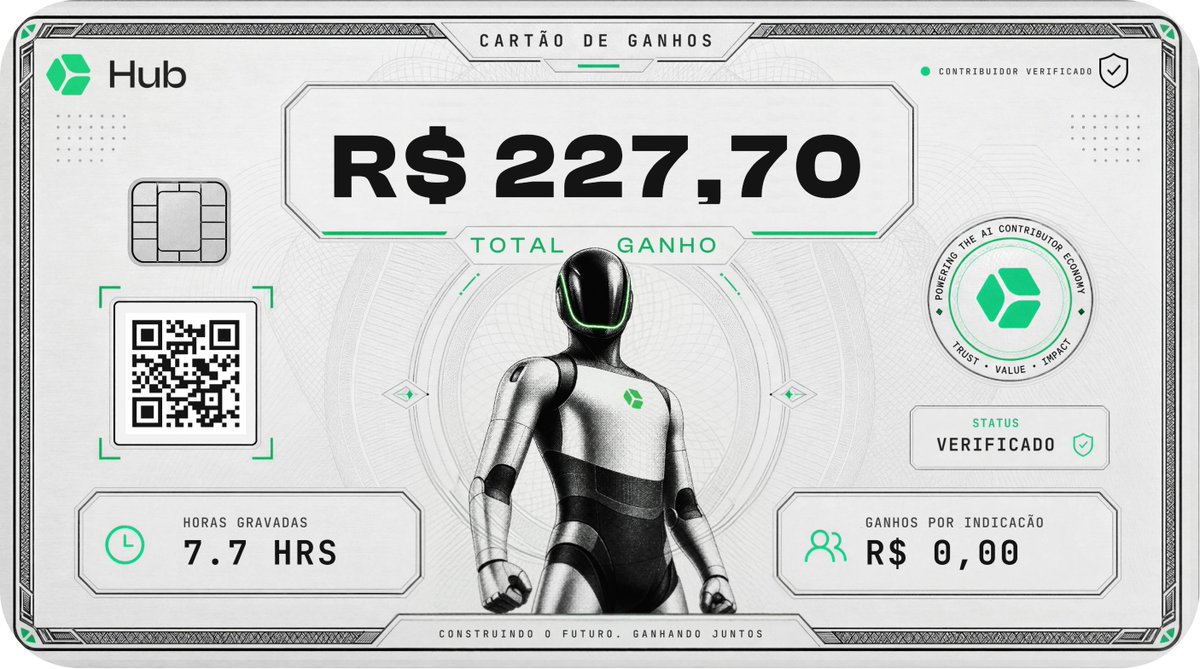
Hub (@hubxyz) provides real-world training data to frontier AI labs and robotics. Human labor is half of global GDP. Almost none of it has ever been recorded. Hub opens access to it through a global network of contributors capturing hard-to-access data. Congrats on the launch, @xarmin and @tim404x! ycombinator.com/launches/Qoe-h…
English