Sabitlenmiş Tweet

UAE will recover at a speed that will shock the whole world.
Do not underestimate the creativity, financial/diplomatic power, and sheer will of MBZ, Al Maktoum, and their government.
They have faith, so I do. #UNITED 🇦🇪
English
Armin - Hub.xyz
12.4K posts

@xarmin
@hubxyz co founder @gensynai @doublezero seed @nolimithodl @q42_co @superscrypt LP

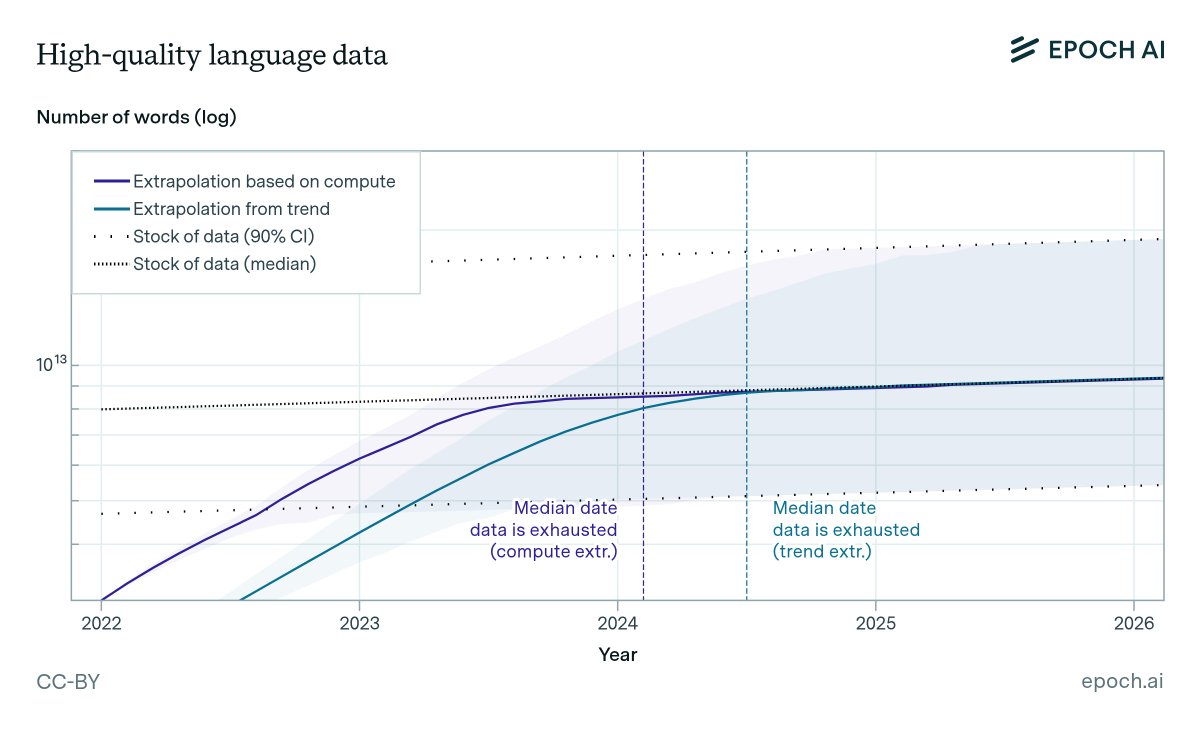

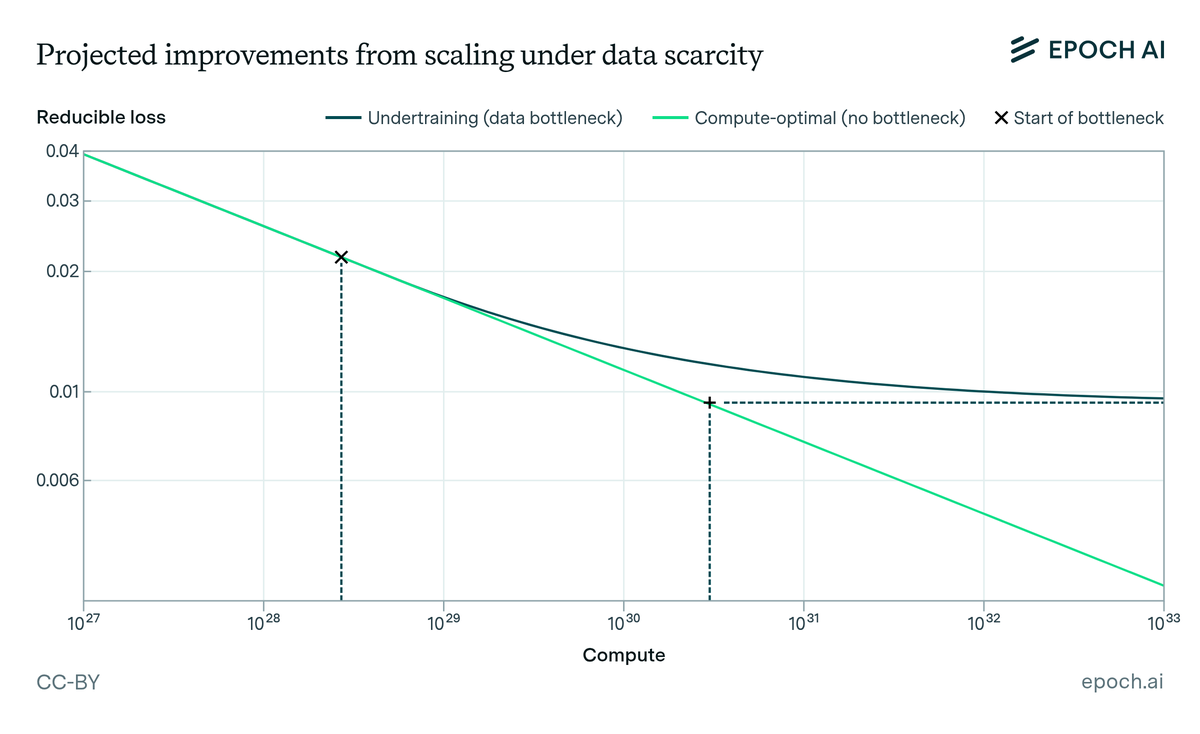
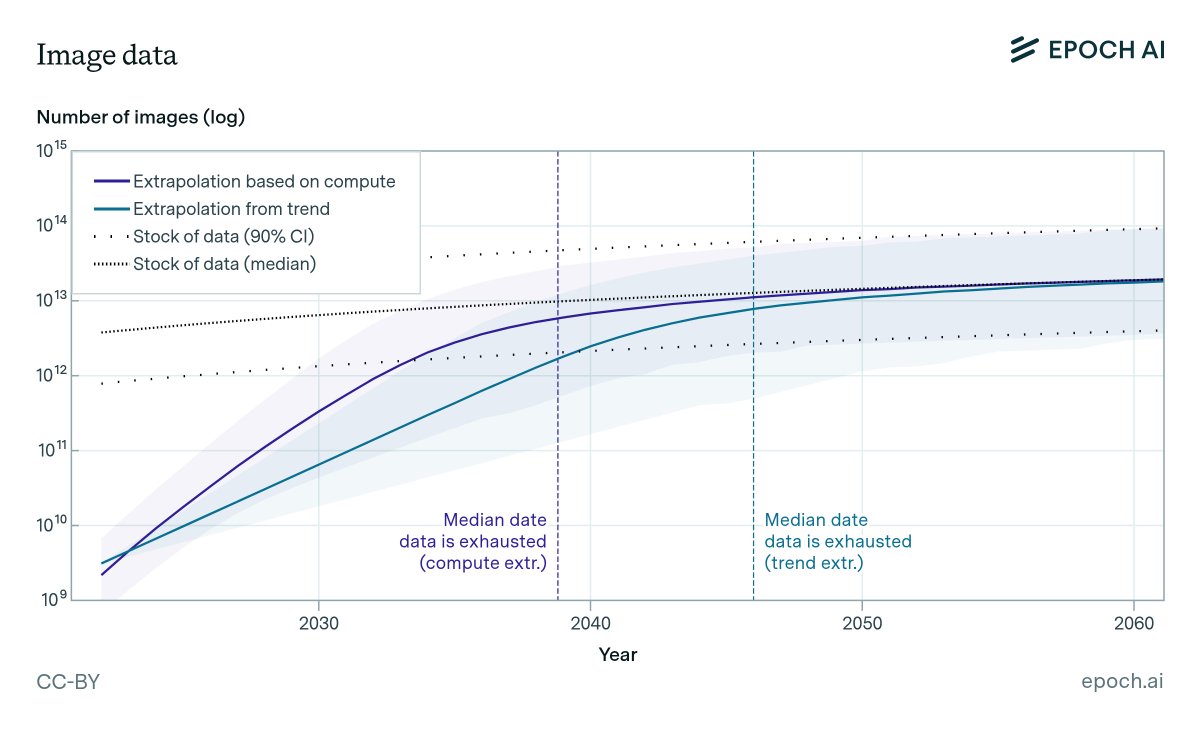
Are we running out of data to train language models? State-of-the-art LLMs use datasets with tens of trillions of words, and use 2-3x more per year. Our new ICML paper estimates when we might exhaust all text data on the internet. 1/12





If Dubai doesn’t vibe with you, no one’s forcing you to yap about it! And if you secretly hate Dubai that much, maybe skip the fake news fanfiction next time? Simple as that. Chill, habibi. 😏




Anthropic CEO Dario Amodei: AI Progress isn’t magic, it’s just compute, data, and training. "All the cleverness, all the techniques, all of the “we need a new method,” doesn’t matter very much. There are only a few things that matter, and I listed seven of them. One is how much raw compute you have. Two is the quantity of data you have. Three is the quality and distribution of the data, meaning it needs to be broad. Four is how long you train for. Five is an objective function that can scale to the moon. Pre-training is one. Another is an RL-style objective: you have a goal and you go reach it. That includes more objective rewards (like math and coding), and more subjective rewards (like RL from human feedback, or higher-order versions of that). Six and seven are about normalization/conditioning: keeping numerical stability so the huge blob of compute flows cleanly instead of blowing up or getting weird." --- From 'Dwarkesh Patel' YT Channel (link in comment)






