Timothy O'Hear retweetledi

I built a fully automatic mansplainer. I'm sure this will not get me into any trouble at all...
Watch here: youtu.be/xHi8PUIVyoo

YouTube

English
Timothy O'Hear
2.4K posts


@timohear
Enthralled by machine learning / artificial intelligence, robot•me CTO, software engineer, Dai the robot co-creator, president of impactIA foundation, Genève



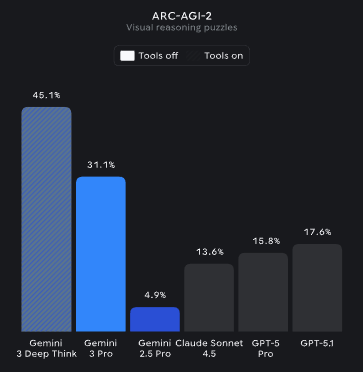
Gemini 3 models from @Google @GoogleDeepMind have made a significant 2X SOTA jump on ARC-AGI-2 (Semi-Private Eval) Gemini 3 Pro: 31.11%, $0.81/task Gemini 3 Deep Think (Preview): 45.14%, $77.16/task














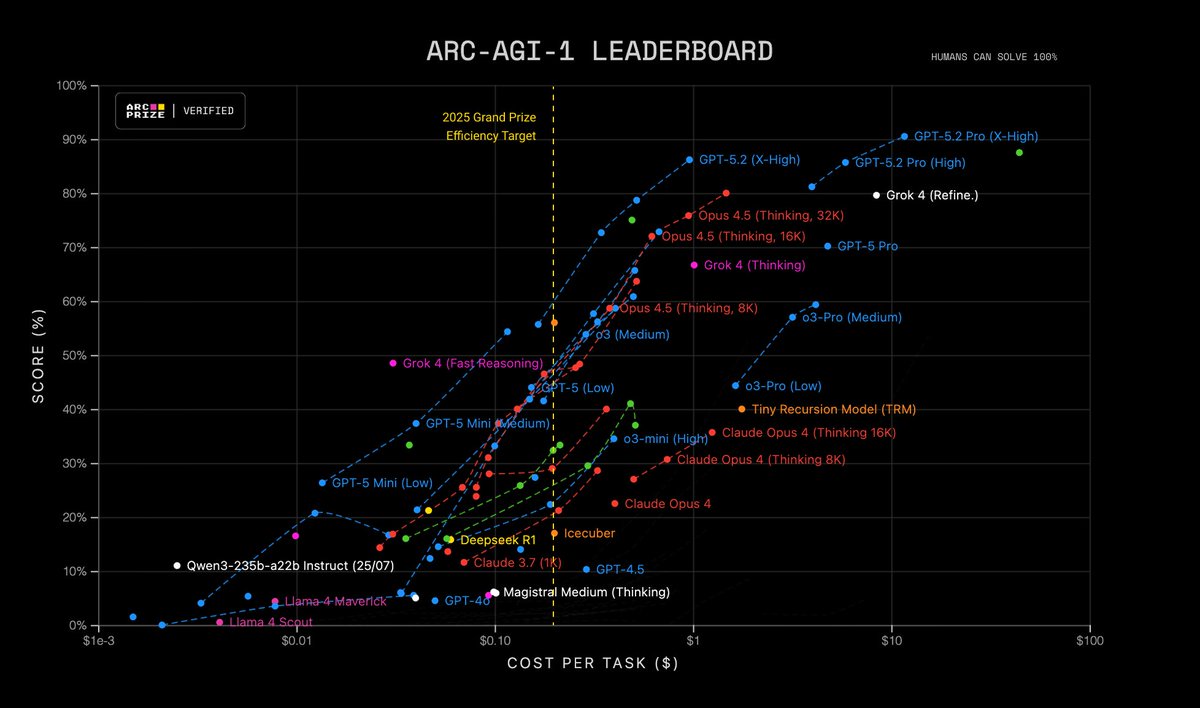
New SOTA on ARC-AGI - V1: 79.6%, $8.42/task - V2: 29.4%, $30.40/task Custom submissions by @jeremyberman and @_eric_pang_ are now the best known solutions to ARC-AGI Both: * Are open source * Use Grok 4 * Implement program-synthesis outer loops with test-time adaptation




LLM adoption rose to 45.9% among US workers as of June/July 2025, according to a Stanford/World Bank survey. Inference demand will continue to surge, not just from more users and more usage per user, but as newer, more advanced GenAI models require far more inference compute. Source: The Labor Market Effects of Generative Artificial Intelligence, Stanford University, World Bank



