Tihomir Mateev retweetledi

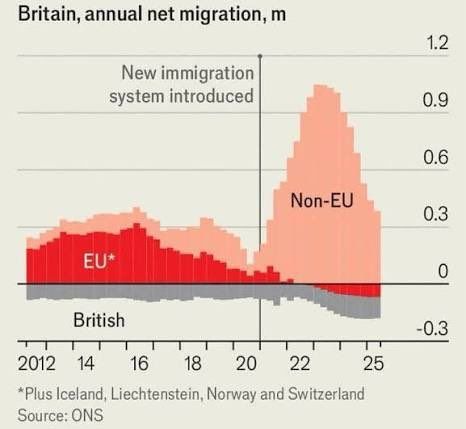
From the outside, there are indeed funny aspects to Brexit. The fact that migration went heaps up is certainly the funniest bit.
English
Tihomir Mateev
2.9K posts


@tishun
Sr. software engineer @ Redis, tech enthusiast, views are my own






Anthropic's Mythos has been accessed by a small group of unauthorized users, raising questions about control of the AI model bloomberg.com/news/articles/…



Huawei camera AI now recommends poses before you click the shutter button






The Obsidian team is growing from three engineers to four engineers. Competitive SF salary. Fully remote, live anywhere. Apply below.

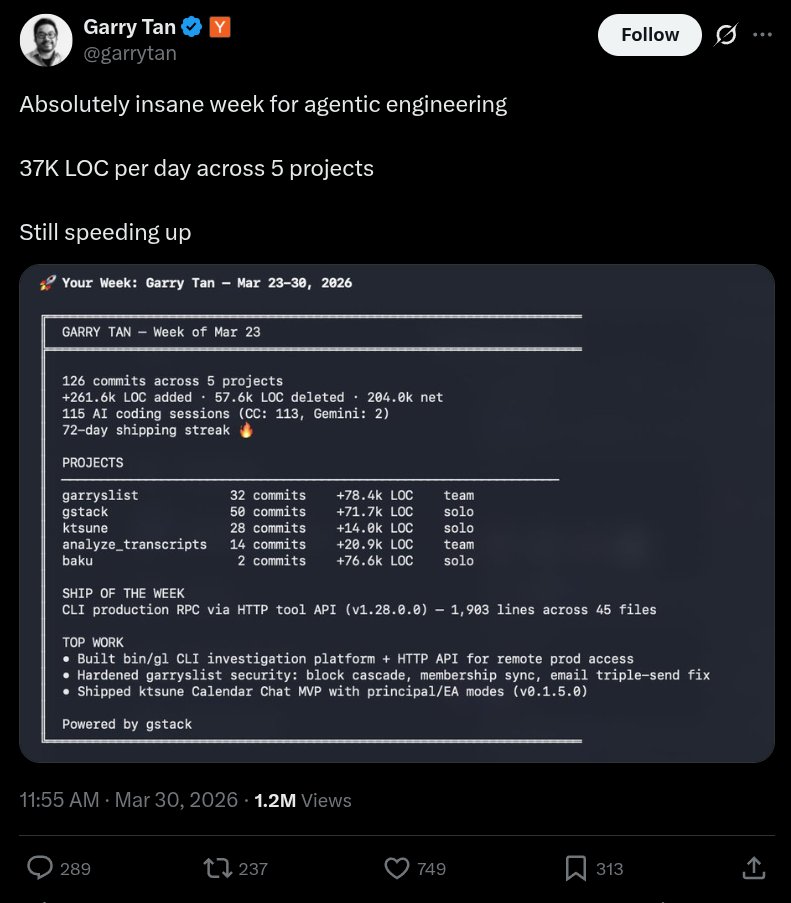
Absolutely insane week for agentic engineering 37K LOC per day across 5 projects Still speeding up