Sabitlenmiş Tweet

I am looking for new AI/ML research internship opportunities. Below is my personal homepage🙂: jiaxuanzou0714.github.io
English
Jiaxuan Zou
156 posts
@SmartPig_Joe
Undergrad@XJTU, Research Intern@Gaolin School of Artificial Intelligence, RUC



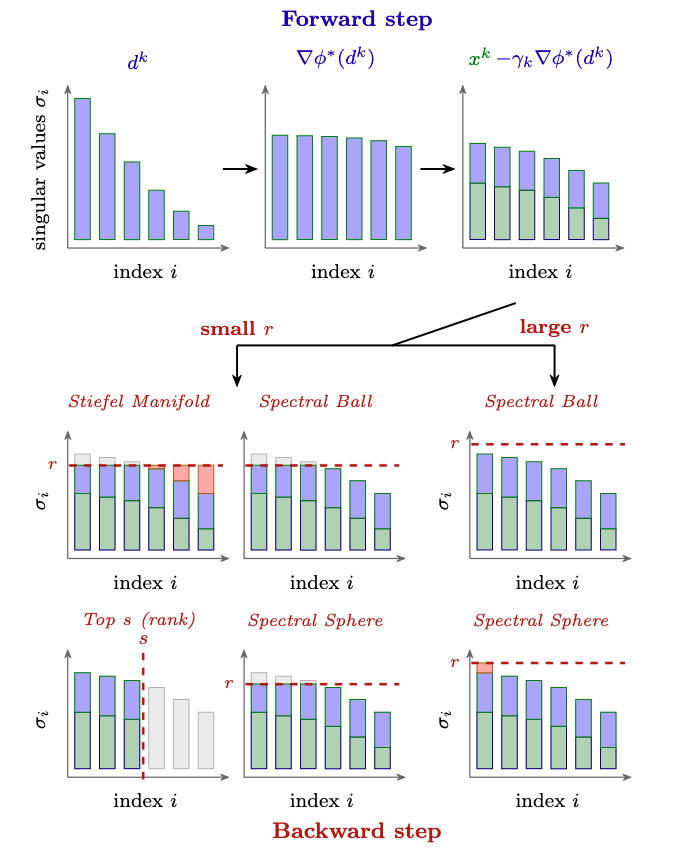
blogpost: Can row-normalization really replace Muon? nil9.net/posts/rownorm_…



blogpost: Can row-normalization really replace Muon? nil9.net/posts/rownorm_…
1/n Please stop by👋. This is not just another ICML 2026 optimizer paper. We have rich intuition to share on why simple preconditioners like orthogonalization and row-normalization specifically benefit NNs optimization. Quick overview below 🧵

Yesterday, I was giving an intro talk to our dept's new PhD students. Technical things aside, my number 1 suggestion has remained the same over the years: Treat your PhD like a job. - Avoid 1.5h lunch and three tea breaks. - Avoid gossiping and loitering at work. - Lab at 9 am and leave at 6 pm. Being productive till 11 pm in the lab is a lie people till themselves when their day starts at 1 PM. Everything worth doing can be done with high intensity focus during work hours. And having fun in life is the secret to being productive in a marathon.





Modded-NanoGPT optimization result #11: @nilinabra has achieved a new record of 3225 steps (-25) via a novel technique dubbed Contra-Muon, in which top SVD components are somewhat suppressed. This result builds on #9.

This is a very meaningful benchmark, but there is one caveat worth keeping in mind. In speedrun settings, there is now a clear trend toward using different optimizers and hyperparameters for different modules. I have to admit that this can bring real gains. But when comparing optimizers, we should not give hyperparameters unlimited freedom. For example, if I first run a strong optimizer, then reverse-engineer an SGD hyper parameter schedule that tunes every neuron at every step to match it, SGD may appear to “simulate” Adam, Muon, or almost any optimizer . But that would not tell us much about SGD. It only means the optimizer has been hidden inside the hyperparameter schedule. To me, the value of a good optimizer is the opposite: it should adapt internally, require fewer hand-tuned knobs, and transfer robustly across model scales. This kind of invariance across model scales is exactly what makes hyperparameter scaling laws meaningful. If we over-optimize the recipe for one particular scale, we may win that benchmark while losing the cross-scale structure we actually want to understand
This result matches my earlier intuition (x.com/CV_novel_plume…): once optimizer-state budget is not constrained and the objective is step count, outer-loop tricks become natural candidates. Interesting that the gain is real, but still fairly small. I would have expected this direction to have more headroom. Maybe the gains would become more visible if the baseline required more iterations, giving these outer-loop dynamics more room to compound.

