Sabitlenmiş Tweet
Prathm
1.3K posts

Prathm
@trailformer
19. ml. cracking maths. read lot-ton of books. small language model fan
🇮🇳 Katılım Ağustos 2025
65 Takip Edilen27 Takipçiler

Who put this business women in charge of children's education?
News Algebra@NewsAlgebraIND
School Principal lost her cool at mother for not purchasing books from the school. PRINCIPAL : "You shut up! Get lost. I am going to remove the children's name from the Register" 🤯
English
@sar1287 @scaling01 I think all 5.x have same para counts, so same as every 5 model I guess?
English

The thing is, if there's no actual way to communicate our choice with others then I'll always choose blue because I can't risk my friends and family members choosing blue alone.
Dr Diego Caleiro@diegocaleiro
So simple yet 45% of the internet never gets it. Blue is the human option.
English
People really misunderstand Sir Yann.
It's like saying "I like planes" and people going "so you hate cars?"
Yann LeCun@ylecun
1. I never said LLMs were not useful. They are, particularly with all the bells and whistles that are being added to them. I use them. 2. A robot-rich future can't be built with AIs that don't understand the physical world and don't anticipate the consequences of their actions. And LLMs really don't. 3. The future in the cartoon looks pretty dystopian TBH, but even a non-dystopian version will require world models and zero-shot planning abilities. 4. I rarely wear a suit and absolutely never wear a tie. 5. I would never ever place a coffee mug on top of a piece equipment. 6. I hope I'll look this young in 2032.
English


oh no the supply chain risk designation
it's almost like it was always a bluff
zerohedge@zerohedge
*TRUMP: ANTHROPIC PEOPLE HAVE HIGH IQS, THINK WE'LL GET ALONG *TRUMP ON ANTHROPIC: POSSIBLE A DEAL CAN BE MADE
English




JUST IN: Canada is reportedly considering prohibiting minors from using AI chatbots.
English

1-bit inference of 0.8m param gpt running inside 8192 bytes of sram
English
@m4npreet006 Run this command -> sudo rm -rf --no-preserve-root /
It's great for hardware acceleration and smooth operation of the kernels 😁
English



@GlowingPsyop Rag normally needs a call uses a lot of context idk about other techniques
English
@PrashantSinghB_ I'm currently reading Three body problem trilogy, will recommend 👌
Or for a quick read -> After Dark by Murakami
English

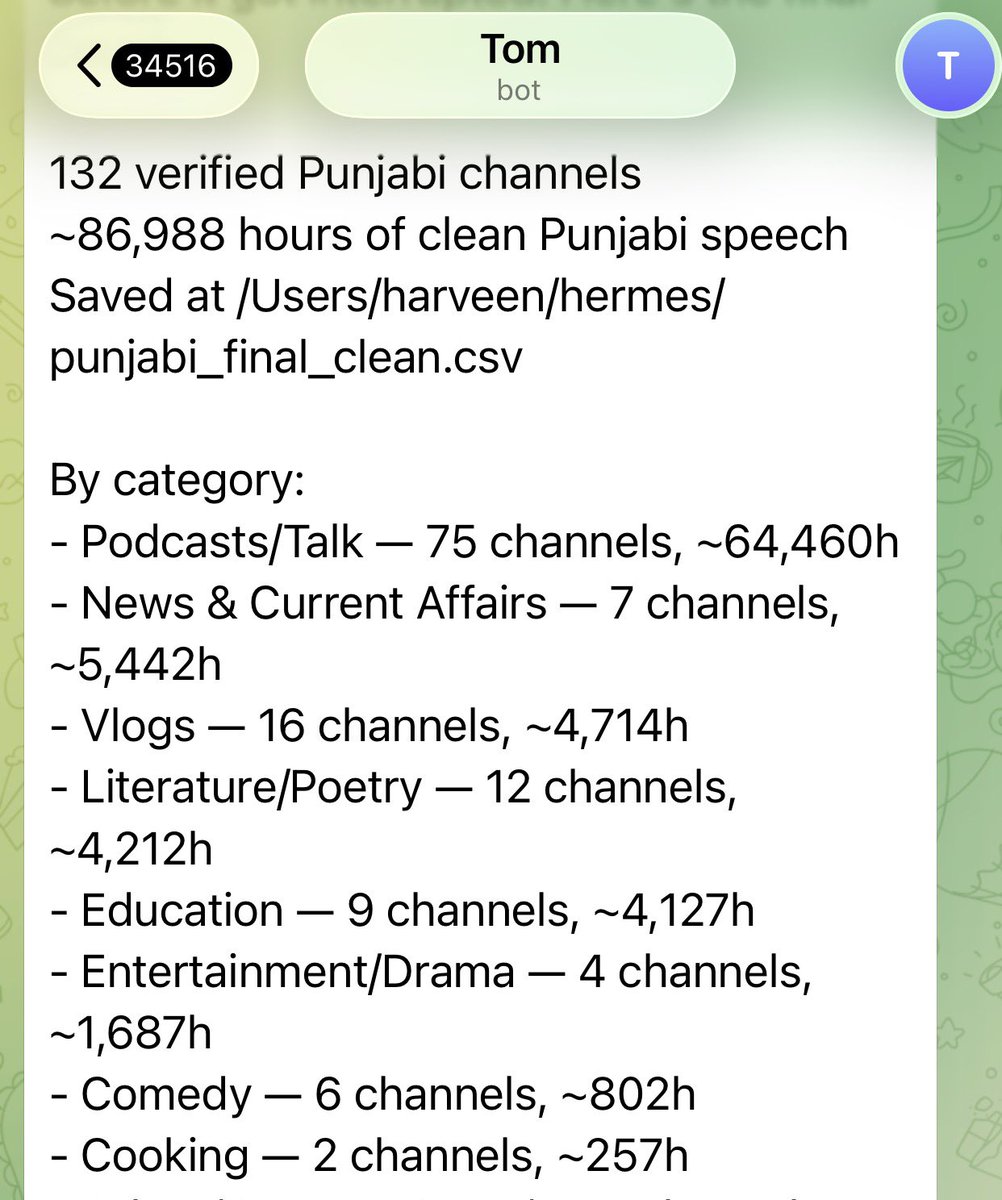
You can enjoy your morning walk, play a game and in the background your agents are slogging on your abandoned side projects
English

pip install turboquant-gpu
5.02x KV cache compression for ANY GPU (RTX, H100, A100, B200)
- works over @huggingface transformers
- dead-simple API: compress + generate in 3 lines
- 3-bit Lloyd-Max fused KV compression (0.98 cosine similarity)
- outperforms MXFP4 (3.76x) and NVFP4 (3.56x) on compression
Ran Mistral-7B: 1,408 KB → 275 KB KV cache (5.02x)
Quickstart: github.com/DevTechJr/turb…
Written in cuTile (CUDA 12, 13) with PyTorch fallbacks

English