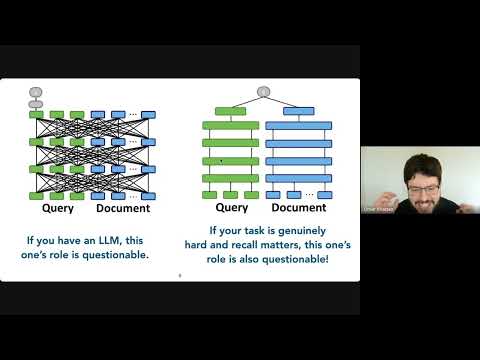
@CJHandmer This seems needlessly alarmist when Australia spends roughly half the US on healthcare per capita and robotics in aged care will be transformative.
English
John Trengrove
234 posts

@trengrj
Applied Research @weaviate_io

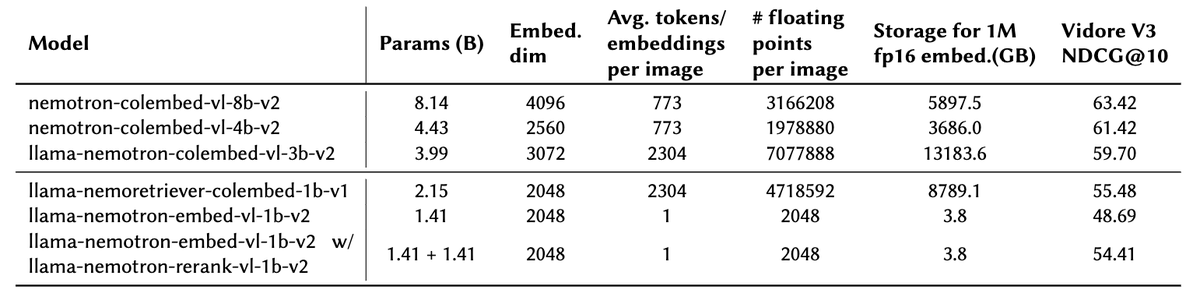

We need to publicly clarify serious issues in Google’s ICLR 2026 paper TurboQuant. TurboQuant misrepresents RaBitQ in three ways: 1. Avoids acknowledging key methodological similarity (JL transform) 2. Calls our theory “suboptimal” with no evidence 3. Reports results under unfair experimental settings We have expressed our concerns to the authors before their submission, but they chose not to fix them in their paper submission. The paper was accepted at ICLR 2026 and heavily promoted by Google (tens of millions of views). At that scale, uncorrected claims quickly become “consensus.” Facts: 1. RaBitQ already proves asymptotic optimality (FOCS’17 bound) 2. TurboQuant uses the same random rotation step but misses stating the connection 3. Their experiments used single-core CPU for RaBitQ vs A100 GPU for TurboQuant None of these is properly disclosed. We’ve filed a formal complaint and posted on OpenReview (openreview.net/forum?id=tO3AS…). We’ll release a detailed technical report on arXiv. Our goal is simple: keep the academic record accurate. Would appreciate people taking a look and sharing.

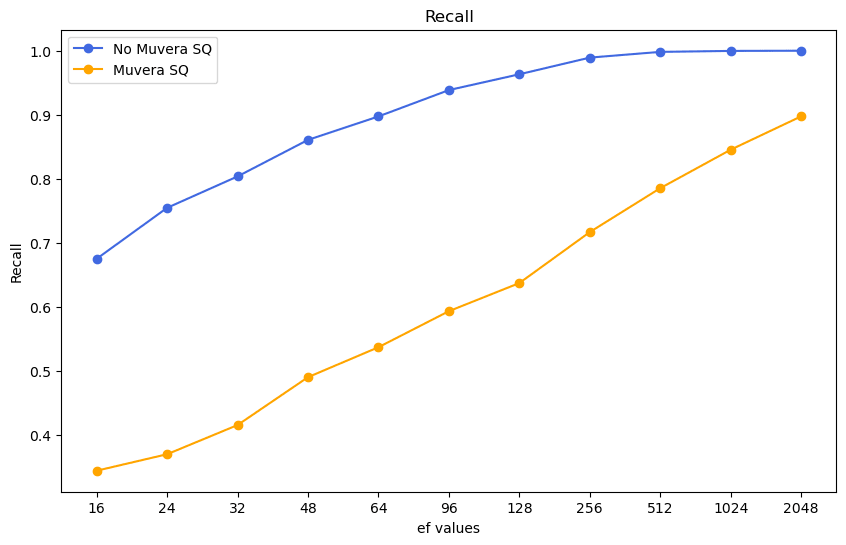
Multi-vector embeddings (ColBERT, ColPali) are budget killers. But MUVERA can cut your memory footprint by 70%. Multi-vector models offer incredible retrieval but suffer from massive memory overhead and slow indexing. MUVERA (Multi-Vector Retrieval via Fixed Dimensional Encodings) compresses these into single, fixed-dimensional vectors. How it works: MUVERA condenses a sequence of vectors (e.g., 100x96d) into one vector via: 1️⃣ Space Partitioning: Groups vectors into buckets using SimHash or k-means clustering. 2️⃣ Dimensionality Reduction: Applies random linear projection to compress each sub-vector while preserving dot products. 3️⃣ Repetitions: Repeats the process multiple times and concatenates results to improve accuracy. 4️⃣ Final Projection: Optional final compression (not used in Weaviate's implementation). The impact (LoTTE benchmark): - Memory: 12GB → <1GB. - Indexing: 20+ mins → 3-6 mins. - HNSW Graph: 99% smaller. There’s a trade-off: You trade a slight dip in raw recall for massive efficiency gains. However, by tuning the HNSW `ef` parameter (e.g., `ef=512`), you can recover 80-90%+ recall while keeping costs low. When should you use MUVERA? → Large-scale production RAG → Systems where memory/infrastructure costs are the direct bottleneck → Use cases requiring fast indexing MUVERA in @weaviate_io 1.31+ takes just a couple of lines of code. You can tune three parameters (k_sim, d_proj, r_reps) to balance memory usage and retrieval accuracy for your specific use case. Read the full technical deep-dive here: weaviate.io/blog/muvera?ut…
Stop storing embeddings. A laptop can now index 60 million text chunks using 6GB, not 200GB. LEANN, a new open-source project flips how vector search works. 𝗧𝗵𝗶𝘀 𝗶𝗻𝗱𝗲𝘅 𝗱𝗼𝗲𝘀 𝗻𝗼𝘁 𝘀𝘁𝗼𝗿𝗲 𝗲𝗺𝗯𝗲𝗱𝗱𝗶𝗻𝗴𝘀 Instead of saving every vector, it stores a compact graph. Embeddings get recomputed only when a query actually needs them. • Graph-based selective recomputation • High-degree node pruning to keep recall stable • No accuracy drop versus FAISS-style indexes 𝗧𝗵𝗲 𝘀𝘁𝗼𝗿𝗮𝗴𝗲 𝗴𝗮𝗶𝗻𝘀 𝗮𝗿𝗲 𝗺𝗮𝘀𝘀𝗶𝘃𝗲 Email archives shrink from gigabytes to megabytes. Browser history fits in single-digit MBs. A 60M-document corpus fits on a laptop SSD. 𝗜𝘁 𝗿𝘂𝗻𝘀 𝗲𝗻𝘁𝗶𝗿𝗲𝗹𝘆 𝗹𝗼𝗰𝗮𝗹 No cloud calls. No telemetry. Everything stays on-device with zero ongoing cost. 𝗜𝘁 𝘂𝗻𝗹𝗼𝗰𝗸𝘀 𝗹𝗼𝗰𝗮𝗹 𝗥𝗔𝗚 𝗮𝘁 𝗻𝗲𝘄 𝘀𝗰𝗮𝗹𝗲 You can semantically search files, emails, chats, codebases, and live MCP sources. All from one local index, without changing your workflow.


me: no but RAG can be done with plain old exact matching grep, it's totally fine @mixedbreadai: rebrand search as grep me: alright, then I guess I am doing grep now







New in Weaviate 1.32+: 8-bit Rotational Quantization! Compress your vectors by 4x while simultaneously improving speed AND quality - yes, it's actually better than uncompressed vectors. But how does it work? Random rotations make every vector perfectly suited for quantization by smoothing entries and redistributing similarity information across all dimensions. This universal approach can handle any dataset without training. Results speak for themselves: ✨ 4x memory reduction ✨ 15-50% faster throughput ✨ Near-perfect recall maintained Check out the full technical deep-dive: weaviate.io/blog/8-bit-rot…