
Ty Feng
159 posts

Ty Feng
@tyfeng1997
environments, eval, training.
BeiJing Katılım Kasım 2023
648 Takip Edilen52 Takipçiler
Ty Feng retweetledi

Today we're sharing our work on interaction models. A new class of model trained from scratch to handle real-time interaction natively, instead of gluing it onto a turn-based one.
youtu.be/A12AVongNN4

YouTube
English

at some point you realize there's often very little merit to fame amongst the tech elite, just people who well positioned to soak up talent around them, and are extremely adept at rewriting narratives to build their own legends after "the work" is already done
for better or worse, there's somehow always a heavy selection bias for fantastic story-tellers everywhere, and the peak will never truly live up to the image they've created of themselves
or in other words, never meet your heroes
English
@jino_rohit 🤓Naive DDP isn't complicated, but adding parameter bucketing and hiding latency through overlapped all_reduce communication and backpropagation makes it more tricky.
English


@j_golebiowski That's great. How about using an SLM that supports voice input modality here?
English

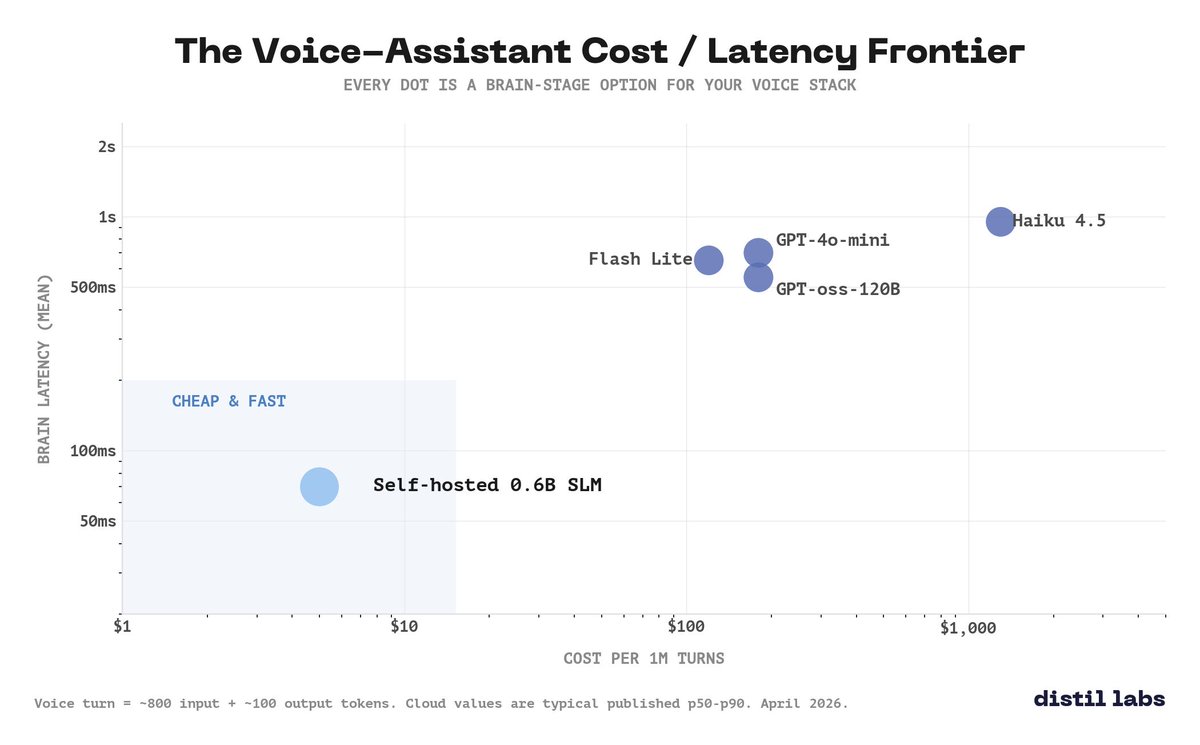
Plot every voice-assistant brain on cost vs latency.
The "cheap and fast" cloud small models all cluster in the expensive-and-slow corner. A specialized self-hosted SLM sits alone in the bottom-left.
The cloud floor is much higher than the marketing copy makes it sound.
English
Ty Feng retweetledi

$200 FREE CREDIT! We just launched our inference platform for beta testing, and we're giving it to the community first.
⭐ Star SGLang on GitHub (github.com/sgl-project/sg…) + repost this to claim your credits.
→ Limited spots, first come first serve
→ Deadline: May 13, 2025 (AoE)
Every star, every issue filed, every PR reviewed, every question answered in Slack — You built this with us. Thank you for believing in open-source AI infrastructure, in our mission, and in us.
Claim your credits: platform.radixark.com
English
@j_golebiowski Are there any experiments on training SLMs for local text retrieval/code search?
English
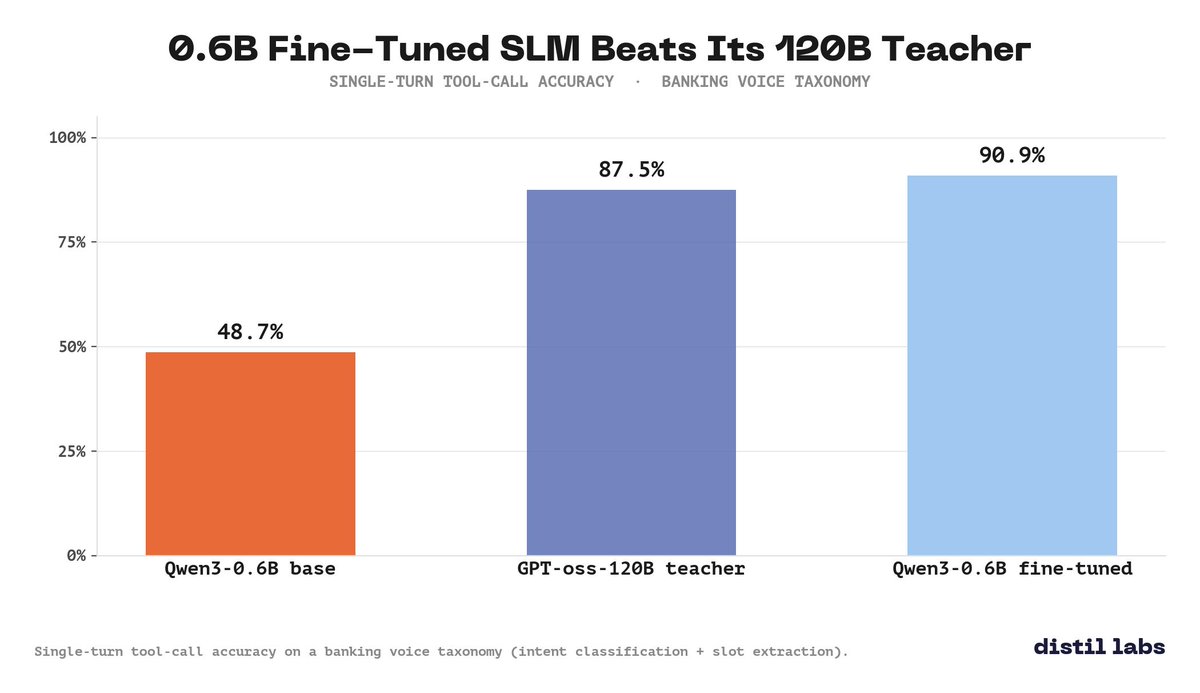
On a banking voice taxonomy:
Fine-tuned Qwen3-0.6B: 90.9%
GPT-oss-120B (its teacher): 87.5%
Qwen3-0.6B base, no fine-tune: 48.7%
The 0.6B student beat the 120B teacher by 3.4 points. On the bounded task you actually shipped, smaller can be more accurate.
English
SLMs are not "cheaper LLMs."
They are a different tool class. Purpose-built for one taxonomy, they outperform general-purpose models on the bounded job they were trained for.
Stop benchmarking SLMs against LLMs. Benchmark them on the job they were specialized for.
English
Ty Feng retweetledi

Everything I Learned Training Frontier Small Models @maximelabonne
After a lot of hype around frontier model training, Maxime gives the practical version: what actually happens when you try to train smaller models that still matter. From data quality and synthetic data to evals, distillation, and where small models still punch above their weight, this is a concise field report from someone doing the work at @liquidai.
If you're building with open models, post training, or trying to understand where the next wave of useful local-ish capability comes from, this one is worth your time.
youtube.com/watch?v=fLUtUk…

YouTube

English
@iScienceLuvr I completely agree. When I see a team propose a new RL algorithm similar to GRPO, I almost don't believe their conclusions if the experiments are only conducted on Qwen2.5 for RL training, unless other model families are covered.
English

just your friendly reminder to throw away any RL paper that only tests their method on Qwen models :)
English
@marktenenholtz I use Gemini to read research papers, and the experience it provides is unparalleled.
English

Anyone who says this doesn’t realize Gemini 3.1 Pro is giga SOTA for certain extremely useful tasks.
3.0 Pro Preview is possibly better at the same tasks than GPT-5.5/Opus 4.7.
Can Vardar@icanvardar
google should just give up on ai at this point
English
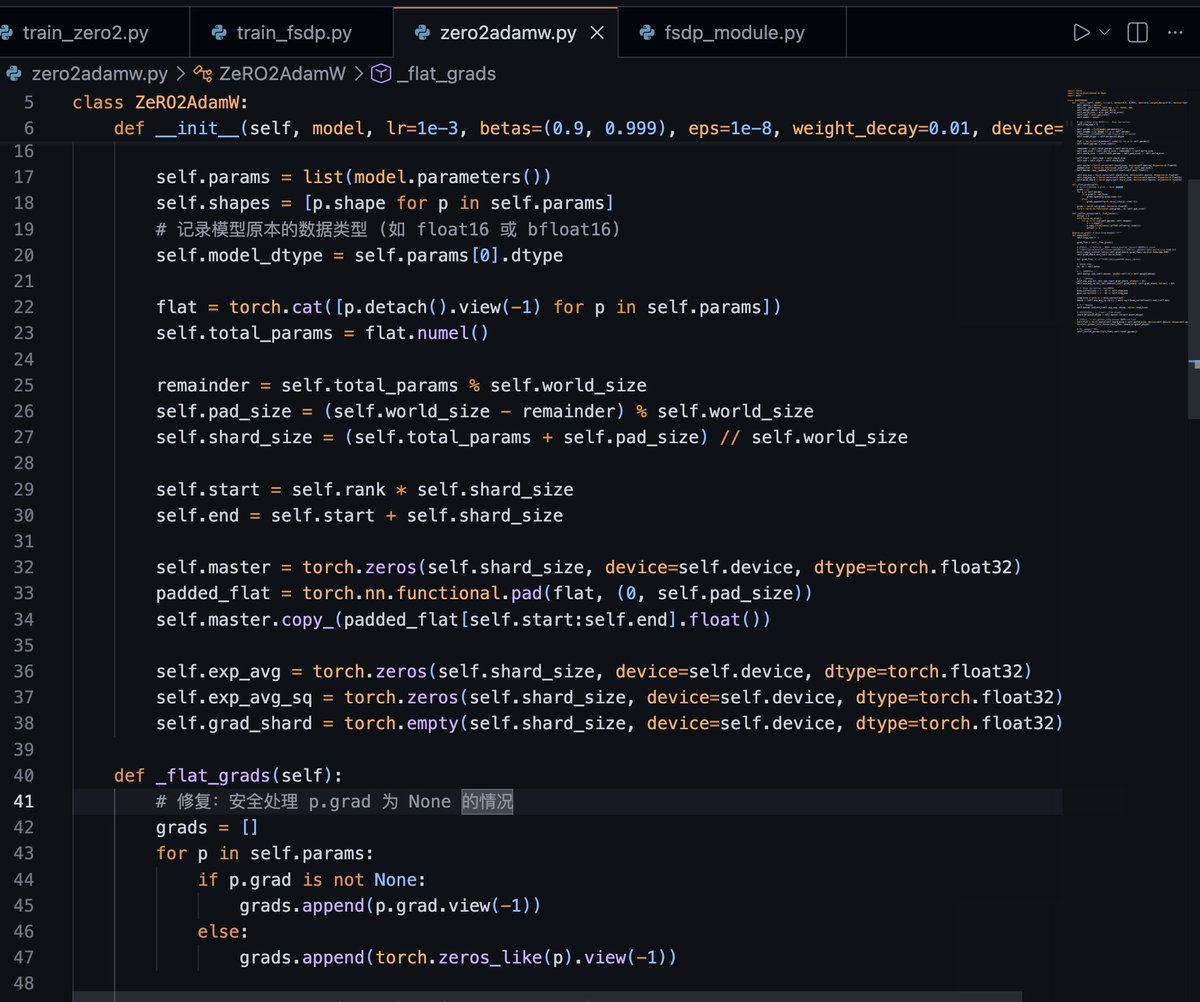
@jino_rohit This book was also a great help to me. In addition, there is jax-ml.github.io/scaling-book. I've been implementing Zero2 and FSDP from scratch these past two days.
English

@TimDarcet 1.5x communication volume but same wall-clock time. Comm-compute overlap makes FSDP basically a free lunch for VRAM.
English

periodic reminder that FSDP does exactly 0 additional communication compared to DDP
François Fleuret@francoisfleuret
Nothing shockingly dumb?
English

In the Age of Agents, an Engineer's Most Valuable Skill Is Saying "No"
I gave a talk at Snowflake recently, sharing what I've learned about agent coding over the past two years of building SGLang's inference engine, Omni multimodal serving, and AI agent workflows. The response far exceeded my expectations — it was the first time so many people asked for the slides afterward. Probably because I deliberately avoided the hardcore technical deep-dives, and instead spent the time on one thing: explaining just how many ways AI Agents can go terrifyingly wrong when maintaining real-world projects. 😂
Slides are fragments. I wanted to reorganize these thoughts into something coherent — threading together ideas scattered across different projects into a single narrative. Starting from my own engineering practice, I want to articulate what "engineering judgment" actually means in the era of agent coding.
I. Standing at the Intersection of Infra and Agent Worlds
Some background first.
I'm a core developer of SGLang, one of the most widely deployed open-source inference engines in the world — 25K+ GitHub stars, running on over 400K GPUs. I currently lead two areas: SGLang RL Rollout (high-performance rollout infrastructure for RLHF) and SGLang Omni (multimodal and TTS model serving).
At the same time, I'm a heavy user of Claude Code, and I make no attempt to hide it. SGLang Omni's latest benchmark infrastructure — thousands of lines of production-grade code — was essentially executed line by line by Claude Code from our system design specs. We have a team of about ten, responsible for defining architecture, setting thresholds, planning file paths, and designing test matrices. AI delivers in dozens of hours. Believe it or not, I rarely write implementation-level code myself anymore.
This isn't a prediction about the future. This is my daily reality.
But precisely because I stand at the intersection of inference engine developer and heavy AI coding user, my understanding of agent coding is probably different from most people's intuition. Most people see "AI can write code now, amazing!" What I see are three seriously overlooked hazards — is what AI writes actually correct? What should the system architecture look like? And is the token cost behind all of this actually worth it?
This article follows these three questions. Starting with the first: how do you know if what AI wrote is actually correct?
II. Effort Without Measurement Is Self-Deception
Near the end of my undergraduate years, I was doing research on intent alignment. During a conversation with a mentor I deeply respect, he systematically laid out his vision for alignment, and one core step stuck with me — building real and effective benchmarking for alignment. His point was roughly: if we can't even measure whether alignment has been achieved, then all alignment work is building castles in the air.
Years later, having done agent research, inference, and RL infra — having stepped on countless landmines — that simple truth only weighs more. And I've found, regrettably, that modern benchmarks haven't kept up. They've fallen far behind the pace of the field.
The agent space is especially bad. Every few days there's a new demo — it can control browsers, rewrite compilers, supposedly put all CUDA engineers out of work. But press further: how do you measure if it's actually good? The answer is usually a few cherry-picked cases or a carefully edited video. On Xinzhiyuan (a prominent Chinese AI outlet), human engineers have been "replaced by AI" a thousand times over. Yet the top Cutlass engineers are still sitting in their offices, drawing high salaries, writing the kernels that actually run in production.
So in my own projects, benchmark has been the highest priority from day one. Bar none.
I felt this most acutely building how-to-sglang — a multi-agent system for helping users understand SGLang code and answering community questions. The temptations were enormous at the start: add RAG, connect more data sources, build multi-turn conversation, try fancy agent debating. The feature list could stretch to the ceiling. But the first thing I did was build an LLM-as-a-Judge evaluation framework. Before adding any feature, answer one basic question: does your change actually make the agent more accurate?
The result: most seemingly promising optimizations showed zero improvement in testing. Without that benchmark, every decision was blind guessing — we thought we were improving, but we weren't.
Building SGLang Omni's benchmark was the same story. Before I took over: an optimization PR gets merged, TPS numbers look good, everyone's happy. A while later accuracy drops, nobody can tell which commit caused the regression, and painful bisecting begins. My first act: stop all development, build accuracy and performance CI first, then talk about optimization. Final results — S2 Pro WER 1.18% (excluding bad cases), Qwen3 Omni 1.91% without voice clone, 1.88% with voice clone. Acceptance criteria ±0.1%, all passing.
At least inference system evaluation is objective — if the number is higher, it's higher. No room for debate. Unlike agent evaluation, which is riddled with subjective judgment and fuzzy definitions. That certainty is precious.
Effort without measurement isn't effort. It's self-deception.
Benchmarking solves the "how do you know it's correct" problem. But there's an even more upstream question: who writes the benchmark framework itself? In my case, AI wrote it — but that's only half the answer.
III. The Prompt Itself Is the System Design
When I say Omni's benchmark refactor — thousands of lines — was mostly written by AI, that's not bragging. It's fact. Writing pytest fixtures, constructing subprocess calls, parsing JSON results, generating CI workflows — AI did it fast and well.
But there's a detail that's easy to miss: that prompt itself was my system design.
The most critical decision in the entire refactor was task × model orthogonal separation. The old version was a 722-line monolithic script, benchmark_tts_speed.py, with all model and task logic coupled together. After refactoring: tasks/, metrics/, dataset/, benchmarker/, eval/ — five modules. Why this decomposition? Because I knew a series of new models would be joining. Without model-agnostic abstraction, every new model means rewriting the evaluation framework. But you can't over-abstract either — Omni models differ far more than LLMs do. S2 Pro uses a Dual-AR codec architecture; Qwen3 Omni uses a 9-stage multi-process pipeline. Evaluation logic can't be fully unified. The task × model orthogonal separation is the balance point between reuse and flexibility.
Ask AI directly to "refactor these 722 lines" and it'll give you a decomposition. But getting the granularity exactly right depends on our judgment about the project's future — what models are coming, what dimensions will change, what's worth abstracting and what isn't. This context is fuzzy, dynamic, full of probabilistic judgment. You can't fully distill it into a prompt.
AI gives you a decomposition. System design gives you the right decomposition.
Code is flesh. Architecture is skeleton. In an era where AI can write ten thousand lines a day, right architecture means ten thousand lines of asset; wrong architecture means ten thousand lines of debt. And AI simultaneously amplifies the cost of wrong directions — it can turn one piece of tech debt into an entire debt empire at a speed you can't imagine.
Saying "system design matters" is empty talk. Let's look at some concrete cases where AI went wrong.
IV. Where AI Actually Fails
Where exactly did Claude fail during the Omni benchmark refactor? A few representative examples.
First category: blind spots in engineering conventions. Claude used gdown to download datasets from Google Drive — fine for a side project, but a ticking time bomb in SGLang's CI. Google Drive rate-limits, 403s, confirm tokens — our main repo has been burned too many times by unstable external download sources. The correct approach: host datasets on HuggingFace, use snapshot_download. Similar issues: dataset fixtures hardcoded to /tmp/ (path conflicts in concurrent jobs), server teardown with only SIGTERM and no SIGKILL fallback, JSON key access without schema validation. Each of these is individually "common sense," but what counts as common sense depends on which environment you work in. AI's common sense comes from the statistical distribution of internet corpora, not from the specific failure history of a particular team.
Second category: CI threshold design. Claude set the TPS threshold at 55 tok/s, with observed values of 85-87 — over 35% margin. This threshold catches catastrophic regression (88→28), but performance silently sliding from 87 to 60 wouldn't trigger any alarm. I looked at four measurements repeatedly — 85.8, 85.9, 86.9, 87.1 — standard deviation roughly 0.6. Final threshold: 80, all metrics standardized to 13-15% margin. The core of this decision isn't arithmetic — it's having a feel for this specific system's run-to-run variance, knowing what margin is "tight enough to catch chronic degradation but loose enough to avoid flakiness." Anyone who's done CI knows: threshold design is a systems engineering problem, not a math problem.
These aren't edge cases. They're systematic. AI writes fast, but between "writing fast" and "writing correctly" lies an entire engineering environment's worth of distance.
Everything above concerns AI coding's limitations in the "writing correct code" dimension. Next, I want to zoom out — not just whether the code is correct, but whether the tokens consumed behind it are actually worth the cost.
V. The Token Efficiency Crisis: Using a Fire Hose to Water Flowers
As an inference engine developer, my daily work is thinking about how to maximize prefix cache hit rates, optimize KV cache memory layouts, and minimize the cost of each inference request. So when I connected Claude Code to a local inference engine and observed its actual request patterns — how to put this — it felt like a water conservation engineer who carefully designed a reclamation system, watching someone water flowers with a fire hose.
Cache hit rate was devastating. Not "decent but room for improvement" — "the prefix cache mechanism we carefully designed at the inference engine level was almost completely destroyed." A single user query triggers multiple low-value tool calls, each carrying over 100K tokens of context window. The Resume feature breaks KV cache hits entirely — an almost absurd bug. The entire session's context construction was never seriously designed for cache reuse from the start.
I like the RAM bloat analogy. In 1969, 64KB of memory sent Apollo to the moon. In 2026, opening a web page costs 500MB, easy. Each generation of hardware engineers pushes memory capacity higher; each generation of software engineers gleefully fills it up. We've gotten used to this cycle.
But LLM inference is different. RAM bloat costs you a slightly slower computer and a couple hundred bucks for an upgrade. Token bloat costs real money — GPU cluster electricity, user subscriptions — and scales exponentially with agent adoption. GPU compute supply elasticity is far lower than DRAM supply elasticity. When compute is constrained, token efficiency isn't "nice to have." It's the core competitiveness that determines who survives.
I have a bold hypothesis: for those sessions consuming 700K tokens, there must be ways to accomplish the exact same task with 10% of the tokens. Not by sacrificing quality — through smarter context compression, better prefix reuse strategies, more precise tool call scheduling. Anyone who has optimized inference engines, seeing current agent framework request patterns, would reach a similar conclusion.
"Reducing wasteful token spending" isn't a defensive optimization. It's an offensive capability. Whoever first achieves an order-of-magnitude reduction in token consumption at the same quality level can serve ten times the users on the same compute budget.
But is the root cause of token waste merely sloppy agent framework design? The more I think about it, the more I believe the deeper issue is architectural.
VI. Agent and Inference Engine: The Missing Co-Design
The current architecture works like this: agent frameworks treat inference engines as stateless API calls, carrying full context with every request. Inference engines do their best at prefix matching, caching what they can. Fully decoupled. Zero coordination. Simple, general-purpose, but brutally inefficient for long sessions.
My vision: if agent frameworks could sense the inference engine's cache state and proactively construct cache-friendly requests; if inference engines could understand the agent's session semantics and make smarter cache eviction decisions — once this information channel between the two opens, the potential for token efficiency gains is enormous.
This requires three parties to sit down together: model builders, inference engine builders, and agent framework builders. Right now, we're nowhere close.
Maybe the market ultimately decides "compute gets cheap enough, waste doesn't matter," just like the RAM story. But I don't believe the token economy will follow the same path. Not in the near term.
The age of agents doesn't belong to those who burn the most compute. It belongs to those who use it most intelligently.
Having covered the token problem from an inference engine perspective, I want to turn the lens back to agents themselves. In the preceding sections I've been criticizing agents — code isn't correct, tokens are wasted, no coordination with inference engines. But let's flip the question: what's the actual moat for agent builders?
VII. The Agent Moat Paradox
I've found a fascinating paradox in the agent space.
Individual techniques are trivially simple to implement. Agent Debating — the so-called "core moat" of many multi-agent systems — doesn't even come close in implementation difficulty to MLA (DeepSeek's significant breakthrough starting with V2). The barrier to entry is nearly zero.
But the verification system is impossibly complex. The first step of any empirical research is building the right benchmark. Inference benchmarks are mature — TTFT, TBT, Throughput. These objective metrics were being used by database engineers decades ago, just under different names. But agent evaluation is riddled with subjective judgment and fuzzy definitions. OpenClaw's benchmark is nothing like a vibe coding benchmark. The complexity of verification far exceeds the complexity of implementation.
Then there's the explosion of the strategy combination space. SGLang has over a hundred server args. Finding the optimal combination for specific hardware and workload is enormously complex. Same for agents: individual strategies are simple, but finding the optimal combination under real-world constraints — that's the real core capability. A top engineer who deeply understands the system derives their value not from implementing any single strategy, but from having a sense for the optimal direction within a complex strategy space.
There's a question I still haven't resolved. Inference and training system strategy optimization typically has clear trade-offs — enabling partial rollout makes it hard to avoid off-policy effects. But do agent strategies have trade-offs against each other? Does turning everything on always produce the best agent? In my own optimization of how-to-sglang, I found most strategies are highly invasive — including human-in-the-loop, including circular debating. This makes me suspect the combination problem is far more complex than we imagine.
Behind the moat paradox hides another question: if individual agent techniques are this simple to implement, and AI can write code at terrifying speed — what happens when AI starts writing code for itself, expanding its own capabilities?
VIII. Code Bloat: The Terrifying Speed of AI Self-Evolution
Look at OpenClaw's codebase and you'll find something eerie.
Early last month: roughly 400K lines. One month later: approaching 1 million. 500+ commits per day. AI agents fully controlling and deeply participating in their own development, with no one able to truly review what's happening. Someone even built a repo called nanobot, claiming to replicate the core functionality in 4,000 lines — 99% smaller.
From the perspective of a large-scale software maintainer, this is terrifying. Rapid growth with zero comprehensibility, entropy increasing at horrifying efficiency.
I later exchanged messages with OpenClaw's maintainer Peter Steinberger on GitHub. His maintenance quality and enthusiasm impressed me — OpenClaw hasn't fallen into fully unsupervised AI self-maintenance. But the question remains: to what extent can we maintain a clean agent system that handles most functionality while avoiding malignant code bloat, keeping us with the ability to actually debug?
AI excels at local optimization — writing functions, fixing bugs, adding features. No problem. But "keeping a system simple" isn't a local problem. It requires a kind of global restraint — being able to say "this, we don't add," and meaning it genuinely, not because some rule says so.
That restraint may be the last thing humans contribute to software engineering.
Of course, maybe I'm overthinking it. Maybe next-generation models really will have "taste," like many of the top engineers I know — maybe they'll understand that the best code is often the code that was never written.
Speaking of "taste" and "restraint," the various new concepts recently trending in our circles are a perfect counter-example.
IX. Old Wine in New Bottles — and Real Engineering Lessons
I recently read a lengthy essay on harness engineering, tens of thousands of words. My first reaction wasn't "what an impressive concept" but "do these people have any ideas beyond coining new terms for old concepts?"
Prompt engineering → Context engineering → Harness engineering → next month probably scaffold engineering or orchestration engineering. It's all the same thing: designing the environment in which your model operates — what information it receives, what tools it uses, how errors are intercepted, how cross-session memory is managed. This has existed since the day ChatGPT launched. It doesn't become a new discipline just because someone gives it a new name.
Complaints aside, the lessons I learned from how-to-sglang are real, and they overlap heavily with the research those articles cite.
Less information, more precision. Our first approach was one giant agent stuffed with all of SGLang's docs, code, and cookbooks, answering everything. Of course it didn't work — the context window isn't RAM. The more you stuff in, the more attention dilutes, the worse the answers get. We ended up with a multi-tier sub-domain expert architecture: one expert agent per subdomain, an Expert Debating Manager to receive questions, decompose sub-problems, and consult the Expert Routing Table to activate the right agents. This improvement delivered more gains than upgrading to a stronger model.
The repo is the single source of truth. All expert agent knowledge comes from markdown files within the repo. No external docs, no verbal agreements. We initially felt the urge to write one massive sglang-maintain.md covering everything — quickly found it didn't work. OpenAI's Codex team hit the same wall: they tried one giant AGENTS.md to rule them all, and it predictably rotted fast. Expired documentation doesn't just go unread — it actively misleads agents.
Structured routing, not guessing. The Expert Routing Table explicitly maps question types to agents. A question about GLM-5 INT4 simultaneously activates the Cookbook Domain Expert and Quantization Domain Expert. Not guessing by the Manager — guided by an index.
None of these lessons are new. Separation of concerns, single responsibility, docs-as-code, shifting constraints left — traditional software engineering principles. It's just that now we're designing working environments for LLMs, so some people feel the need for a new name. They don't.
The first nine sections have mainly covered the "software" side. To close, I want to discuss two harder topics that I keep running into — one about hardware, one about abstraction.
X. GPU-Only Debugging, and the Cost of Premature Abstraction
First: the debugging cost of ML infrastructure. This domain has a brutal reality — you simply cannot debug on CPU. The bugs that actually matter — CUDA Graph capture failures, multi-stream race conditions, FP16/BF16 numerical divergence, KV cache memory fragmentation at production batch sizes — only manifest on GPUs, at scale, with real kernels running. AI can help you write a CUDA wrapper, but it can't reproduce the graph capture failure that only appears on H100 with 3 concurrent requests at a specific memory layout. ML infra debugging requires hardware intuition — understanding how GPUs actually behave, not just how the code reads. This is the domain AI coding struggles most to reach.
Second: the premature abstraction trap. This problem has gotten worse in the agent era. Previously, over-abstraction at least took time to write — three wrapper layers around a function called once, a config system managing three parameters, architecture diagrams drawn before problem boundaries are understood. Now with AI, these things arrive in minutes. But the cognitive debt they leave behind hasn't decreased at all. Premature abstraction isn't just useless — it's actively harmful, increasing the cognitive load for every person who comes after. And cognitive load is the most hidden, most lethal kind of engineering cost.
It's not that abstraction is wrong. The timing is wrong. AI makes us write code ten times faster, but also makes us accumulate cognitive debt ten times faster.
GPU debugging tests hardware intuition. Premature abstraction tests restraint. At their core, they test the same thing.
Closing: Engineering Sense Is Sorting
Looking back at this entire article, I've really been saying one thing.
An engineer's most valuable ability isn't building complex things. It's looking at a pile of things that all seem worth doing, and identifying which ones actually matter. Writing code is addition. Engineering sense is sorting. You need to be able to face a cool optimization idea and say "not now — get the benchmark solid first." Face an elegant abstraction and say "delete it, we don't need this yet." When everyone is stacking features, say "stop — let's first confirm what we're actually optimizing."
This judgment doesn't come from books. It's the muscle memory left behind after crawling out of one specific pit after another. From a mentor's lesson about benchmarking, to choosing to build evaluation first when building agents, to building benchmark infrastructure for Omni, to observing Claude Code's token waste, to thinking about the nature of agent moats — the same insight, evolved from "that makes sense" to instinct.
In an era where AI can write ten thousand lines of code a day, execution is depreciating fast. But system design has never been more important — because AI simultaneously amplifies the cost of going in the wrong direction.
The age of agents doesn't belong to those who burn the most compute, or write code the fastest, or coin the most new terms. It belongs to those who know what not to build.
English
@GenAI_is_real 谢谢你的文章,受益匪浅,非常认同要把基准测试首先做好做对这个观点,忘记从哪儿听到的一句话了-- “如果无法测量它,就无法优化它”。此外,在这个充满噪音的时代,能分清什么是重要的,这是一个很值得追求的事情。看到吐槽新智元,早给他取关了,那就是个垃圾媒体🤢。
中文
@rosstaylor90 I recently read the KellyBench paper, and it looks quite challenging. However, using agents for prediction and match betting is an interesting question.🤑
English

This was so much fun. The first time we’ve sat down and talked about some of our research bets and how we differ from the rest of the field.
(I need a haircut, it’s been a long sprint… 💇)
General Reasoning@GenReasoning
🌄 Beyond SWE: The Future of Long Horizon Environments A discussion with our founders about KellyBench, and the need for new environments that require agents to adapt over time and act under uncertainty. 0:00:17 What is KellyBench? 0:02:10 Openendedness, non-stationarity and continual learning 0:03:40 Analytical versus operational capabilities 0:04:13 Why are models bad at KellyBench? 0:05:39 Situational awareness in dynamic environments 0:06:37 Feature stability and real-world non-stationarity 0:07:07 The power of context 0:07:34 "The first principle is that you must not fool yourself" 0:08:20 Machiavelli, fortuna and the ability to adapt to change 0:09:23 How can models improve on evals like KellyBench? 0:10:12 Limitations of KellyBench: data availability and market odds timing 0:11:44 Implications beyond quant finance / sports betting 0:13:26 Civilisations as the ultimate time horizon 0:14:05 Would a mega prompt / better elicitation do much better on the benchmark? 0:14:52 What new types of capability is GR excited about? 0:17:48 Taste and the ability to pursue long-term goals even if they aren't immediately rewarding 0:18:56 Deep learning as an example of a method that took a long time to bear fruit 0:19:25 Optimism about the future of AI
English
SSD achieves a permanent cleanup of noise in advance through training-time truncation and widens the paths at logical forks using training-time high temperature. This allows the final inference to run on a cleaner and more spacious logical track. arxiv.org/abs/2604.01193…
English

[dusting off my blog] - I'd love for more people to get into AI Infra, and so I wrote about my path there from NVIDIA - Tesla AI - X - DeepMind and now OpenAI. I only see our industry growing, so this is for those wanting to gain a solid physical-to-sw foundation of the field.
English

We are recruiting full time members of technical staff and interns at @Eigent_AI / @CamelAIOrg to work on:
- Building long horizon reinforcement learning environments for LLM agent training
- Building Eigent - an open source desktop LLM agent product for knowledge work (eigent.ai)
Base: London or SF
Contact: send your resume to hr@eigent.ai or dm me with your relevant experiences!
English