Evan Owen retweetledi
Evan Owen
1.7K posts

Evan Owen
@ulmentflam
Co-Founder & CTO of QWERKY AI. My opinions are my own.
Katılım Ağustos 2009
765 Takip Edilen164 Takipçiler

Evan Owen retweetledi

Evan Owen retweetledi

Apple Research just published something really interesting about post-training of coding models.
You don't need a better teacher. You don't need a verifier. You don't need RL.
A model can just… train on its own outputs. And get dramatically better.
Simple Self-Distillation (SSD): sample solutions from your model, don't filter them for correctness at all, fine-tune on the raw outputs. That's it.
Qwen3-30B-Instruct: 42.4% → 55.3% pass@1 on LiveCodeBench. +30% relative. On hard problems specifically, pass@5 goes from 31.1% → 54.1%.
Works across Qwen and Llama, at 4B, 8B, and 30B. One sample per prompt is enough. No execution environment. No reward model. No labels.
SSD sidesteps this by reshaping distributions in a context-dependent way — suppressing distractors at locks while keeping diversity alive at forks. The capability was already in the model. Fixed decoding just couldn't access it.
The implication: a lot of coding models are underperforming their own weights. Post-training on self-generated data isn't just a cheap trick — it's recovering latent capacity that greedy decoding leaves on the table.
paper: arxiv.org/abs/2604.01193
code: github.com/apple/ml-ssd

English
Evan Owen retweetledi

I implemented @GoogleResearch's TurboQuant as a CUDA-native compression engine on Blackwell B200.
5x KV cache compression on Qwen 2.5-1.5B, near-loseless attention scores, generating live from compressed memory.
5 custom cuTile CUDA kernels ft:
- fused attention (with QJL corrections)
- online softmax
-on-chip cache decompression
- pipelined TMA loads
Try it out: devtechjr.github.io/turboquant_cut…
s/o @blelbach and the cuTile team at @nvidia for lending me Blackwell GPU access :)
cc @sundeep @GavinSherry
English
Evan Owen retweetledi

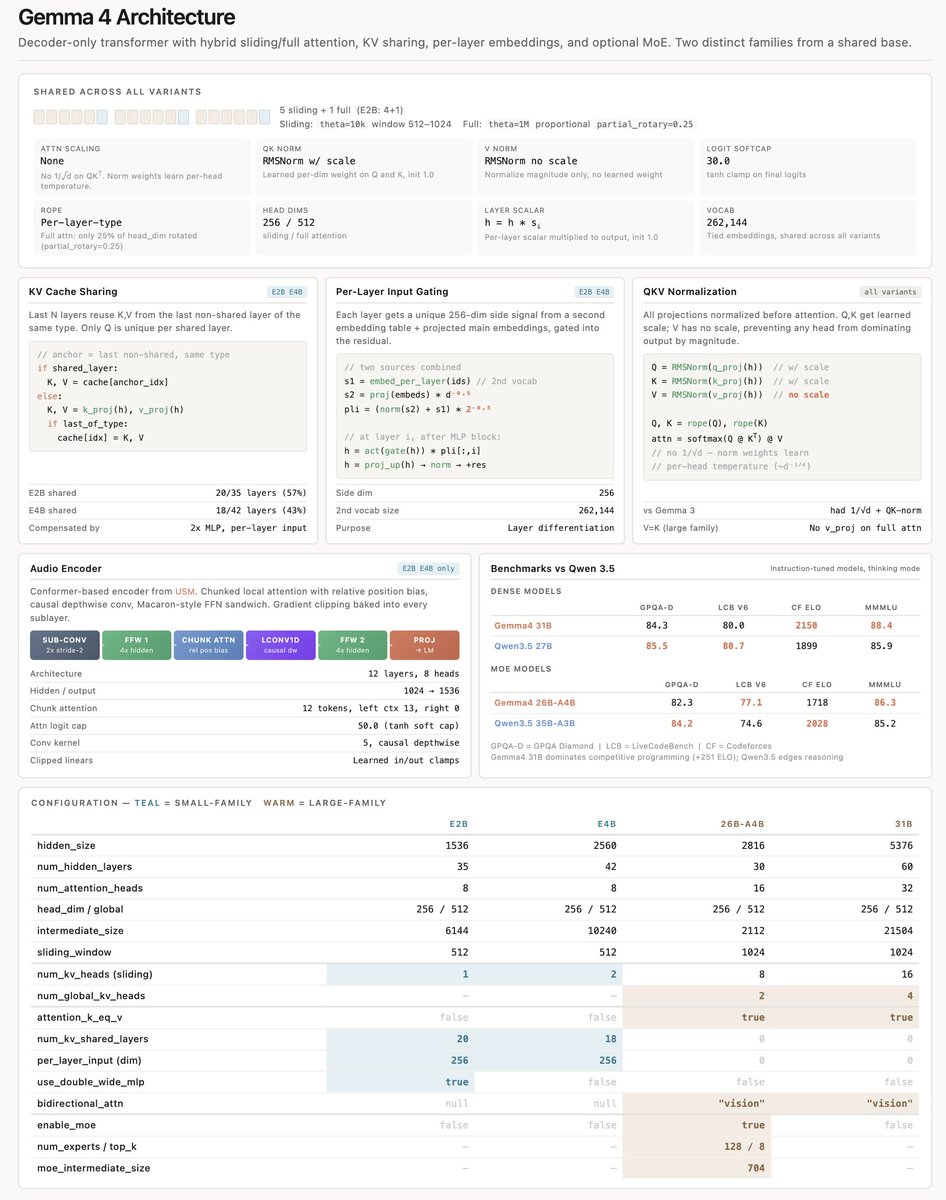
google gemma 4 architecture is very interesting and every model has some subtle differences, here is a recap:
> per layer embedding only on the small variant
> no attention scale (usually you divide qk^T by sqrt(d), they don't)
> they do QK norm + V norm as well
> they share K and V for the large variant
> they do quite aggressive KV cache sharing on the small variant
> sliding window (512 and 1024) is bigger than gpt-oss 128 and they don't use sinks!
> softcapping
> rope only on part of the dimensions + different rope theta for the local/global layer
Omar Sanseviero@osanseviero
Gemma 4 is here! 🧠 31B and 26B A4B for models with impressive intelligence per parameter 🤏E2B and E4B for mobile and IoT 🤗Apache 2.0 🤖Base and IT checkpoints available Available in AI Studio, Hugging Face, Ollama, Android, and your favorite OS tools 🚀Download it today!
English
Evan Owen retweetledi
new linear attention kernel!
github.com/InclusionAI/cu…

Ant Ling@AntLingAGI
🚀 Linear Attention is unlocking million-token context windows by dropping computational complexity from O(N^2) to O(N), but software is increasingly bottlenecking the hardware. Meet cuLA (CUDA Linear Attention): hand-written kernels using CuTe DSL & CUTLASS C++ to extract maximum performance on NVIDIA GPUs. A drop-in replacement for FLA designed to push hardware to its absolute limits.
English
Evan Owen retweetledi

Evan Owen retweetledi

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
Evan Owen retweetledi

Google Deep Mind's impressive fully-open Gemma 4 is live day-zero on Modular Cloud. Modular provides the fastest performance on NVIDIA Blackwell and AMD MI355X, thanks to MAX and Mojo🔥. The team took this impressive new model to production inference in days.🚀
English
Evan Owen retweetledi

Gemma 4 is live on Modular Cloud, day zero, with the fastest performance on both NVIDIA and AMD. Our MAX inference framework delivers 15% higher throughput vs. vLLM on B200, and we’re the only inference provider to ship @googlegemma 4 on a framework we built ourselves.
Two multimodal models live now: Gemma 4 31B (dense, 256K context) and 26B A4B (MoE, only 4B params active per pass). Both SOTA on Modular Cloud: modular.com/blog/day-zero-…
Modular Cloud runs on MAX, our inference framework that unifies GPU kernels, graph compilation, and high-performance serving in a single hardware-agnostic stack. New weights to SOTA deployment in days, on two hardware platforms: modular.com/request-demo?u…
GIF
English
Evan Owen retweetledi

Meet Gemma 4: our new family of open models you can run on your own hardware.
Built for advanced reasoning and agentic workflows, we’re releasing them under an Apache 2.0 license. Here’s what’s new 🧵
GIF
English
Evan Owen retweetledi

cool work on speeding up Muon!
Jack Zhang@jcz42
We made Muon run up to 2x faster for free! Introducing Gram Newton-Schulz: a mathematically equivalent but computationally faster Newton-Schulz algorithm for polar decomposition. Gram Newton-Schulz rewrites Newton-Schulz such that instead of iterating on the expensive rectangular X matrix, we iterate on the small, square, symmetric XX^T Gram matrix to reduce FLOPs. This allows us to make more use of fast symmetric GEMM kernels on Hopper and Blackwell, halving the FLOPs of each of those GEMMs. Gram Newton-Schulz is a drop-in replacement of Newton-Schulz for your Muon use case: we see validation perplexity preserved within 0.01, and share our (long!) journey stabilizing this algorithm and ensuring that training quality is preserved above all else. This was a super fun project with @noahamsel, @berlinchen, and @tri_dao that spanned theory, numerical analysis, and ML systems! Blog and codebase linked below 🧵
English
Evan Owen retweetledi

1/ Standard MoE has a massive statistical flaw: routing is independent per layer. For a deep network, the number of expert paths (N^L) dwarfs the number of pre-training tokens. Most expert combinations never receive a learning signal. 🧵

English
Evan Owen retweetledi

Evan Owen retweetledi

wow @garrytan just exposed Anthropic as total frauds
Claude Code was ONLY 512K LOC ☹️
Gary is shipping 37K LOCs PER DAY
so Gary could recreate all of Claude Code in ONLY 13 days!
a supposedly $380 billion is big trouble
English
Evan Owen retweetledi
Evan Owen retweetledi
Pipelining AI kernels is required to get full perf/utilization out of modern chips. However, no one has been able to crack "full control over the hardware" without "having to micromanage it".
Let's crack this open: kernel authors deserve a powerful scheduler they can control. 💪
Modular@Modular
FA4 on Blackwell: 14 ops, 5 hardware units, 28 dependency edges. One wrong sync = a race condition sanitizers won't catch. We built a constraint solver that derives the pipeline schedule automatically, in Mojo 🔥 Part 1 of our series is out → modular.com/blog/software-…
English
Evan Owen retweetledi

It's my favorite kind of work: linear algebra insight + fast kernels.
When playing w Muon a while ago, we were thinking why not speed it up by operating on the small square matrix X X^T instead of the large rectangular matrix X. Jack, Noah, and Berlin spent many months understanding eigenvalues/vectors of the intermediate matrices in Muon, and finally came up with a simple and elegant algo to make this work.
Jack Zhang@jcz42
We made Muon run up to 2x faster for free! Introducing Gram Newton-Schulz: a mathematically equivalent but computationally faster Newton-Schulz algorithm for polar decomposition. Gram Newton-Schulz rewrites Newton-Schulz such that instead of iterating on the expensive rectangular X matrix, we iterate on the small, square, symmetric XX^T Gram matrix to reduce FLOPs. This allows us to make more use of fast symmetric GEMM kernels on Hopper and Blackwell, halving the FLOPs of each of those GEMMs. Gram Newton-Schulz is a drop-in replacement of Newton-Schulz for your Muon use case: we see validation perplexity preserved within 0.01, and share our (long!) journey stabilizing this algorithm and ensuring that training quality is preserved above all else. This was a super fun project with @noahamsel, @berlinchen, and @tri_dao that spanned theory, numerical analysis, and ML systems! Blog and codebase linked below 🧵
English
Evan Owen retweetledi

Thanks to @AI21Labs for tracking down a silent uint32 overflow in vLLM's Mamba-1 CUDA kernel and contributing the fix.
Root cause: `uint32_t` stride × cache_index overflows silently at scale. Fix merged in #35275. The debugging story is worth a read.
🔗 ai21.com/blog/vllm-cuda…
English
Evan Owen retweetledi

We need to publicly clarify serious issues in Google’s ICLR 2026 paper TurboQuant.
TurboQuant misrepresents RaBitQ in three ways:
1. Avoids acknowledging key methodological similarity (JL transform)
2. Calls our theory “suboptimal” with no evidence
3. Reports results under unfair experimental settings
We have expressed our concerns to the authors before their submission, but they chose not to fix them in their paper submission. The paper was accepted at ICLR 2026 and heavily promoted by Google (tens of millions of views). At that scale, uncorrected claims quickly become “consensus.”
Facts:
1. RaBitQ already proves asymptotic optimality (FOCS’17 bound)
2. TurboQuant uses the same random rotation step but misses stating the connection
3. Their experiments used single-core CPU for RaBitQ vs A100 GPU for TurboQuant
None of these is properly disclosed.
We’ve filed a formal complaint and posted on OpenReview (openreview.net/forum?id=tO3AS…).
We’ll release a detailed technical report on arXiv.
Our goal is simple: keep the academic record accurate.
Would appreciate people taking a look and sharing.
English