Zhiyuan1i
46 posts







why is triton’s kernel launch cpu overhead so freaking high? the actual kernel takes 10x less execution time than to launch it and i can’t use cuda graphs because the shapes are dynamic.

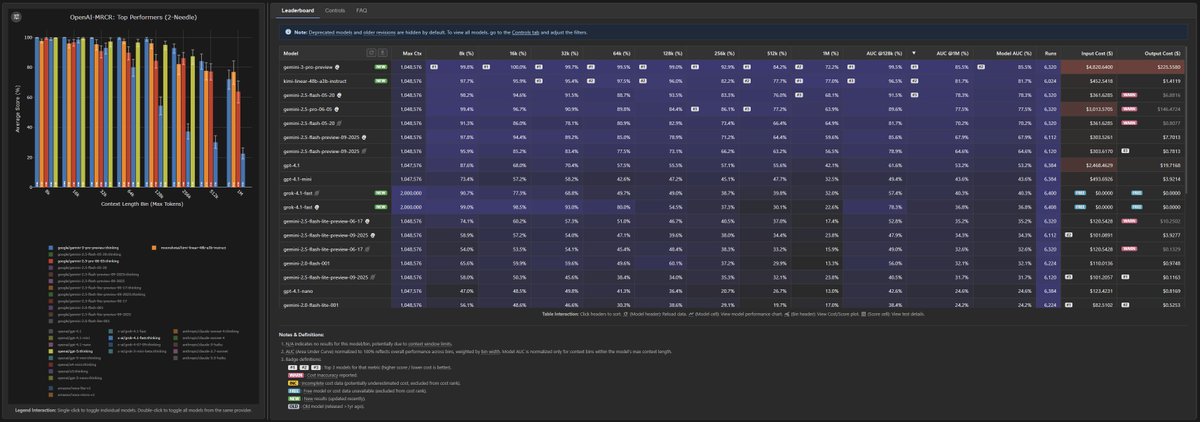
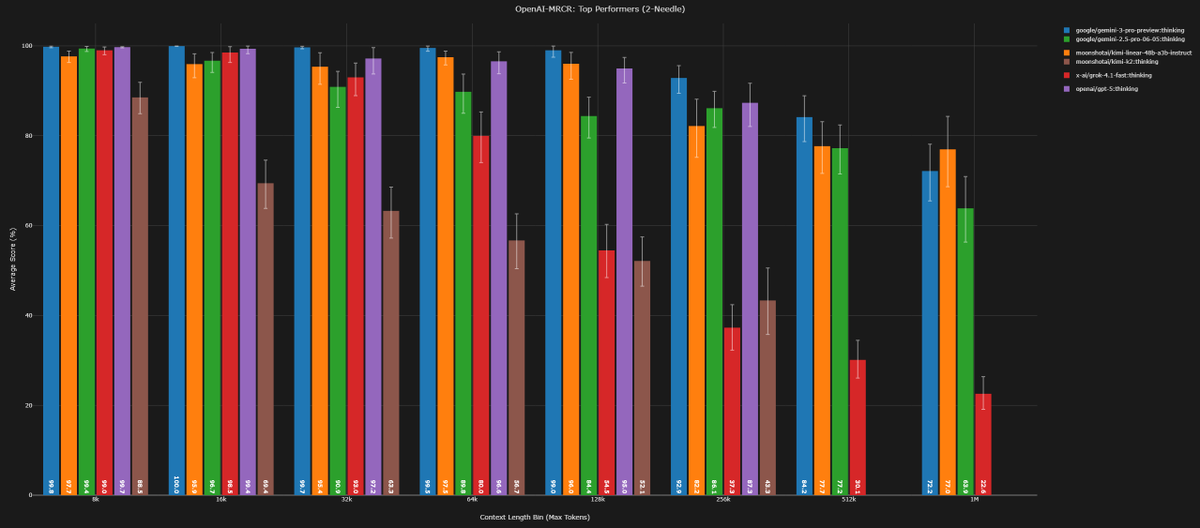
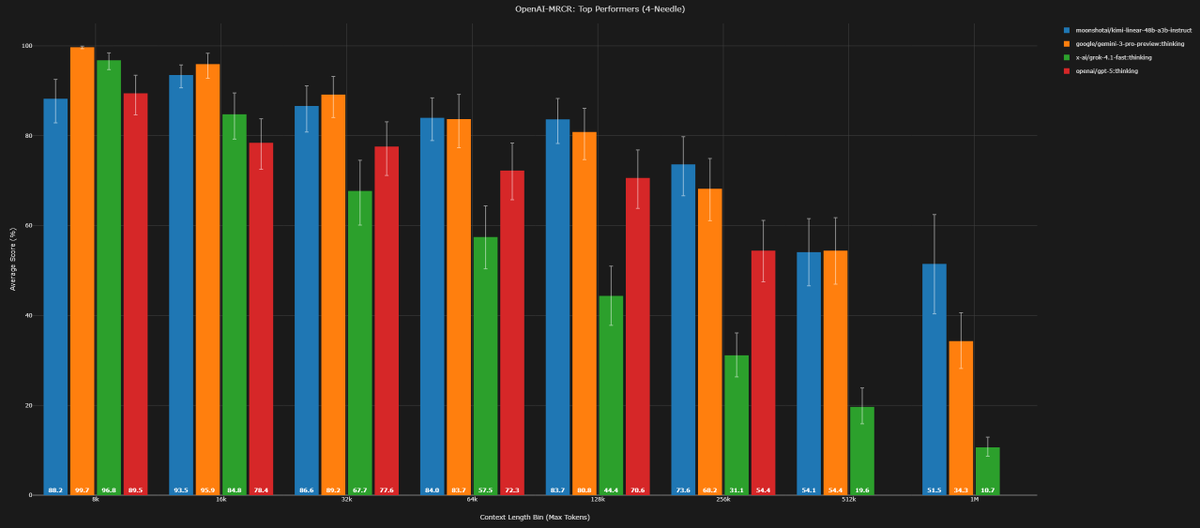
Kimi K2 Thinking used the highest number of tokens ever across the evals in Artificial Analysis Intelligence Index

🚀 Hello, Kimi K2 Thinking! The Open-Source Thinking Agent Model is here. 🔹 SOTA on HLE (44.9%) and BrowseComp (60.2%) 🔹 Executes up to 200 – 300 sequential tool calls without human interference 🔹 Excels in reasoning, agentic search, and coding 🔹 256K context window Built as a thinking agent, K2 Thinking marks our latest efforts in test-time scaling — scaling both thinking tokens and tool-calling turns. K2 Thinking is now live on kimi.com in chat mode, with full agentic mode coming soon. It is also accessible via API. 🔌 API is live: platform.moonshot.ai 🔗 Tech blog: moonshotai.github.io/Kimi-K2/thinki… 🔗 Weights & code: huggingface.co/moonshotai

Hybrid models like Qwen3-Next, Nemotron Nano 2 and Granite 4.0 are now fully supported in vLLM! Check out our latest blog from the vLLM team at IBM to learn how the vLLM community has elevated hybrid models from experimental hacks in V0 to first-class citizens in V1. 🔗 hubs.la/Q03RWWDD0 #vLLM #PyTorch #OpenSourceAI #HybridModels



@xeophon Your “LLM delivery”has arrived! Please remember to leave a five-star review. 🐱miao ~~~


You see: - a new arch that is better and faster than full attention verified with Kimi-style solidness. I see: - Starting with inferior performance even on short contexts. Nothing works and nobody knows why. - Tweaking every possible hyper-parameter to grasp what is wrong. - Trying to find the efficient chunkwise parallelizable form to squeeze juice out of the GPU - RoPE or NoPE, a question haunting for nights. - Fighting buggy implementation that causes one of the long-context benchmarks drops ~20 pts. - RL diverging. Aligning training-inference numerics. - Dedicated efforts to make sure comparisons are solid and fair. - Going back-and-forth in a pool of adversarial gate-keeping tests, and finally it survives. Great teamwork!

@Kimi_Moonshot I cannot run Kimi Linear on A100 on Pytorch 2.9 + Cuda 13.0. Crashing in fla.kda.gate + triton.

Kimi Linear Tech Report is dropped! 🚀 huggingface.co/moonshotai/Kim… Kimi Linear: A novel architecture that outperforms full attention with faster speeds and better performance—ready to serve as a drop-in replacement for full attention, featuring our open-sourced KDA kernels! Kimi Linear offers up to a 75% reduction in KV cache usage and up to 6x decoding throughput at a 1M context length. Key highlights: 🔹 Kimi Delta Attention: A hardware-efficient linear attention mechanism that refines the gated delta rule. 🔹 Kimi Linear Architecture: The first hybrid linear architecture to surpass pure full attention quality across the board. 🔹 Empirical Validation: Scaled, fair comparisons + open-sourced KDA kernels, vLLM integration, and checkpoints. The future of agentic-oriented attention is here! 💡
Kimi Linear Tech Report is dropped! 🚀 huggingface.co/moonshotai/Kim… Kimi Linear: A novel architecture that outperforms full attention with faster speeds and better performance—ready to serve as a drop-in replacement for full attention, featuring our open-sourced KDA kernels! Kimi Linear offers up to a 75% reduction in KV cache usage and up to 6x decoding throughput at a 1M context length. Key highlights: 🔹 Kimi Delta Attention: A hardware-efficient linear attention mechanism that refines the gated delta rule. 🔹 Kimi Linear Architecture: The first hybrid linear architecture to surpass pure full attention quality across the board. 🔹 Empirical Validation: Scaled, fair comparisons + open-sourced KDA kernels, vLLM integration, and checkpoints. The future of agentic-oriented attention is here! 💡