
vume
56 posts

@bob_hw_store @sudoingX I have been interested in these too. Where are you sourcing? 32gb versions on AliExpress all seem to be closer to $1,000 USD.
English

@ShoneeOnionRing @UncannySp1der Strongly disagree
Disagree
Partly disagree
Neutral
Partly agree
Agree
Strongly agree
English

@UncannySp1der What kind of fucking scale has 7 as the highest value?
English

Apparently Marvel thinks Professor X is smarter than the mutant who's whole power is knowledge, he's also the only 7 intelligence I can find on marvel.com outside of actual gods




English

it’s insane that it’s basically impossible to buy a new windows mini pc, not refurbished and not used, for under $100. the mac mini neo is going to wipe windows away from earth
English
@distributedkv gwern-mandated zyns oneshotting a generation of nootropicmaxxers one by one
English



@PrimeiroFront A casa é dos pais, quem manda é eles! Vc só vai decidir alguma coisa quando pagar um boleto ou ter seu próprio canto. Seja os pais bons ou não,isso não tira o poder deles de mandar e a autoridade sobre o lar. Quer direitos, vai ter seu canto. Povo fraco e encostado kkk
Português
@pixningopain A gente ta tipo o Goku no comeco do arco boo, estamos mortos mas em 2027 vamos voltar super sayajin 3.
Português

A timeline pegando fogo e nem um fiozinho de paiN Gaming envolvida.
Resta aceitar nosso papel como meros NPCs no cenário a partir de agora, personagens secundários totais, daqueles que só fazem número.
De Luffy a Usopp.
De Naruto a Kiba.
De Goku a Kuririn.
Não sobrou nada, o famoso BRUTAL.
Português


@txhno @LottoLabs 32gb vram is plenty for that. Subagents are also super pricey (oauth still always obv win but it's not gonna be that price forever)
English

@LottoLabs even with Hermes if you dont have a big enough context window and are unable to spin up subagents you're not nearly sota. it also doesn't help that most of my potential automations require it to be able code. i do agree the tool use on the model has been pretty great for its size
English
dont get me wrong, im a huge open weights advocate. but the way people romanticize open models like theyre plug and play replacements for frontier models just isnt reality. were just not there yet. youre not running opus on a macbook on a flight and its not gonna cost any less
Lotto@LottoLabs
How Apple mfrs think this goes >be me >drop $1600 on two RTX 3090s used off eBay >"48GB VRAM, I'm basically a datacenter now" >they arrive in anti-static bags that look like they've been through a war >plug them into my motherboard and it sounds like a jet engine taking off >neighbors probably think I'm mining crypto again >install llama.cpp, download qwen3.6-27b quantized >"Q4_K_M, only 16GB, totally fits" >start LM Studio on port 1234 >type "hello" into the chat box >GPU fans spin up to 100% instantly >wait 8 seconds for a response >>"Hello! How can I assist you today?" >I've seen faster responses from my grandma reading a text aloud >try Q8_0 quantization because "quality matters" >OOM error, obviously >spend three hours tweaking n_gpu_layers and n_ctx like it's some kind of dark art >finally get it running at 4 tokens per second >ask it to write me a poem about my GPUs >>"Two cards of silicon and light / They hum through the endless night" >"bro this is actually fire" >show it to someone on Discord >”why are you running LLMs locally when you could just use an API for free" >explain that the joy isn't in the output, it's in watching 94% VRAM usage and knowing nobody else has access to my model >they don't understand >close Discord, open LM Studio again >"let's try a longer context window" >crash
English

How Apple mfrs think this goes
>be me
>drop $1600 on two RTX 3090s used off eBay
>"48GB VRAM, I'm basically a datacenter now"
>they arrive in anti-static bags that look like they've been through a war
>plug them into my motherboard and it sounds like a jet engine taking off
>neighbors probably think I'm mining crypto again
>install llama.cpp, download qwen3.6-27b quantized
>"Q4_K_M, only 16GB, totally fits"
>start LM Studio on port 1234
>type "hello" into the chat box
>GPU fans spin up to 100% instantly
>wait 8 seconds for a response
>>"Hello! How can I assist you today?"
>I've seen faster responses from my grandma reading a text aloud
>try Q8_0 quantization because "quality matters"
>OOM error, obviously
>spend three hours tweaking n_gpu_layers and n_ctx like it's some kind of dark art
>finally get it running at 4 tokens per second
>ask it to write me a poem about my GPUs
>>"Two cards of silicon and light / They hum through the endless night"
>"bro this is actually fire"
>show it to someone on Discord
>”why are you running LLMs locally when you could just use an API for free"
>explain that the joy isn't in the output, it's in watching 94% VRAM usage and knowing nobody else has access to my model
>they don't understand
>close Discord, open LM Studio again
>"let's try a longer context window"
>crash
English
@VictorTaelin lower is better but the wider the bar the better 😵💫 (but holy hell i love the colors!!!)
English

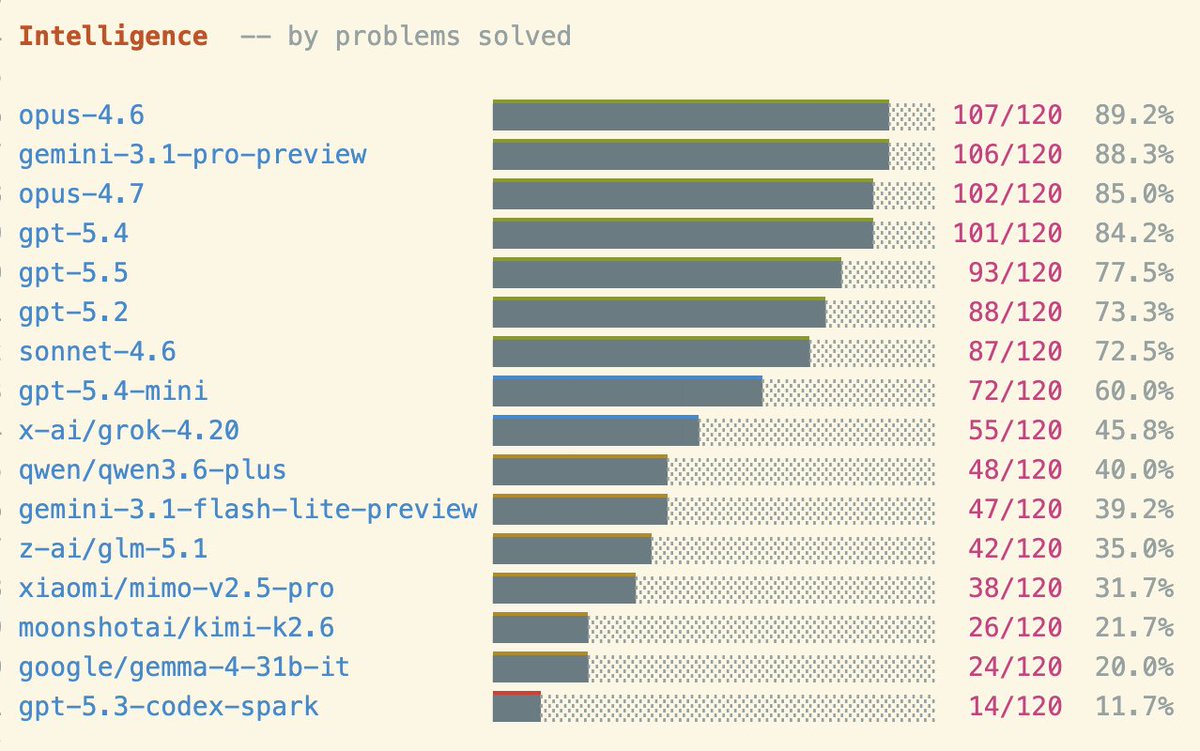
Introducing LamBench . . .
You asked me to make a benchmark, so I made it. It is a simple, old style Q&A consisting of 120 fresh λ-calculus programming questions. Some are easy, like "implement add for λ-encoded nats". Some are harder, like "derive a generic fold for arbitrary λ-encodings".
It measures:
- intelligence (% tasks completed)
- elegance (BLC-length of solutions)
- speed (completion time)
Basically what I care about, other than long context.
I made it today because I was excited about GPT 5.5.
It didn't do too well ):
(My first-day impression is that I can't tell the difference between GPT 5.5 and GPT 5.4. I would be lying if I said otherwise. I'd not be able to distinguish in a blind test. I need more time. It is much faster though.)
This is a new, simple bench, so expect be bugs.
Specially on OpenRouter models. I'll retest soon.
Also, it was born saturated. V2 will be harder...
↓ Link and more charts below ↓
English
@VictorTaelin Do they want to allocate that much compute to… anything other than improving their models?
English

Português

Estamos falando do único bilionário da história que assistia NBA pelo Streameast fechando anúncios pra não atrapalhar

NBA LEGENDADA 🇧🇷@NBALegendada
O LEBRON NÃO DÁ CARA KKKKKKKKKK #NBA #basketball #basquete #nbabrasil
Português
@jufxfgbvcfgv @Adianu4 @BrooklynGuyNBA o de amanha passa no meu tambem, o que nao vai passar eh o de domingo. mas tb acho que no league pass brasileiro tem mais jogo do que o dos EUA
Português

@vachasss @Adianu4 @BrooklynGuyNBA Ue, pra mim aparece, mas eu tbm tenho a paramount, talvez seja por isso que nunca reparei, que loucura.

Português




@yacineMTB it’s the year of no desktop. Phone and voice typing only. Linux homelab tho
English

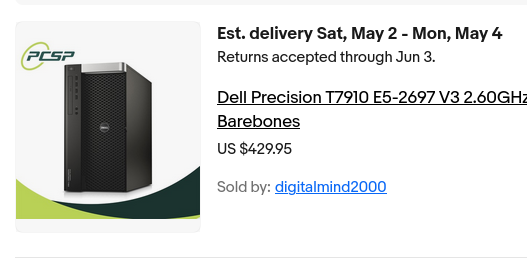
@akhsurgin I got 10% cashback on amazon so it ended up being much cheaper, prime visa + young adult cash back, also no time to tinker rn classes lowk kicking my ass
English

@vachasss It was just an example screenshot, you can get it faster with newegg, bestbuy, microcenter, etc.
English
You don't need a $5,000 PC to run Qwen3.6-27B.
2x RTX 5060 TI 16 GB GPUs cost <$1,000 and they give you the same 32 GB of VRAM as a 5090.
In LMstudio, 27B will run at 20+ tokens/second with 200k of context, 35B MoE will run at 110+ tokens/second.

English