Sabitlenmiş Tweet
Marcin Kliks
3.6K posts


Marcin Kliks
@vi4m
AI & Software Principal Engineer at @allegrotech. CEO at Somiflow Biotech Software. Always testing the latest tech and integrating it into my professional work
Poznan, Greater Poland Katılım Temmuz 2009
711 Takip Edilen716 Takipçiler


I’ve just met some engineers doing incredible things with AI.
The landscape of programming is changing so rapidly.
My prediction:
AI won’t replace engineers. But in 60 days engineering will look completely different.
English
@KinasRemek Wybierz opcję:
- batteries included - kilkadziesiąt gotowych connectorow (imsg, calendar, mail) napisanych przez Petera - praktyczność
- elastyczność - Kernel Pi który nie obsługuje MCP ale ma filozofię generowania kodu który rozszerza go o nowe skille.
- efekt sieciowy
Polski

Na czym polega fenomen OpenClaw 🦞? Możecie to wyjaśnić?
- ludzie chodzą z szczypcami na głowie
- stoiska na ekspozycji GTC z motywami OpenClaw
- slajdy z symbolem 🦞- wiele firm chce mieć ten motyw na swoich materiałach
- keynote GTC - całkiem duża część wypowiedzi Jensena Huanga poruszało temat 🦞
- dzisiaj NVIDIA przekazuje GB300 Andrejowi Karpathy a tam informacja o 🦞
- kiedy wymieniane jest gdziekolwiek nazwisko twórcy 🦞 - pojawiają się wielkie brawa, owacje
By była jasność. Bardzo się cieszę, że tak wygląda kariera twórcy, jest uznawany, ceniony, a jego rozwiązanie jest adaptowane nawet na poziom segmentu konsumenckiego i enterprise. To jest super. Zastanawiam się jednak co spowodowało, że tak prosta koncepcja, możliwa do złożenia za pomocą kilku skryptów i dobrego frameworku agentowego wystrzeliła tak do góry? Tym bardziej, że jest łatwa do skopiowania, istnieje już kilkadziesiąt podobnych rozwiązań (niektóre teoretycznie bardziej zaawansowane, efektywniejsze).
Pomysły? Myśli?
Polski
Marcin Kliks retweetledi
Dzisiaj prezentuję kolejną publikację, w której miałem zaszczyt współpracować z Adamem Trybusem oraz Bartkiem Bartnickim. Tym razem opisujemy sposób podnoszenia jakości reasoningu modelu Bielik-R 🇵🇱 (model wytrenowany w celach R&D choć wersje beta reasoningu są dostępne w modelu 11B od wersji 2.6).
Dziękuję za współpracę, pomysły, benchmarki i wspólne intelektualne wyzwania.
arXiv:2603.10640 (cs)

Polski
Marcin Kliks retweetledi
Bielik- Minitron-7B - projekt, który miałem wielki zaszczyt prowadzić jako lider techniczny z ramienia Bielika 🇵🇱 przy współpracy z @nvidia 👍💪🙏🎉 oraz niesamowitymi chłopakami z naszego zespołu (o tym za chwilę).
Ogłoszenie piszę przebywając w San Jose, CA 🇺🇸 To tutaj właśnie powstają przełomowe dla AI produkty. Symboliczne.
Po pierwsze zespół najważniejszy dlatego - brawo Paweł Kiszczak, który świetnie zadziałał jako wsparcie techniczne (zresztą Pawła konfiguracja modelu okazała się w naszych testach najlepszą) oraz lider biznesowy. Przepięknie prowadzony projekt. Świetne wsparcie. Ogrom zaangażowania. Jesteś gość - pełen szacunek. Wspólnie robiliśmy etap R&D, pruningu oraz destylacji.
Prace wykonaliśmy z super teamem Nvidia. Ekspresowo. Przygotowanie modeli, danych, destylacja - konfiguracja Leptona DGX, skryptów (nie obyło się bez custom kodowania). Szczególne podziękowania chcę złożyć na ręce Sergio Perez z Nvidia za wsparcie i pomoc techniczną - merytoryka potoku pruningu i destylacji oraz Nvidia Leption DGX Cloud.
Co zrobiliśmy? Przeprowadziliśmy pruning modelu Bielik-11B-v3.0 oraz destylację do modelu 7B przy minimalnej stracie jakości tnąc blisko 30% parametrów. Całość procesu opisaliśmy w publikacji. Jest to ponownie unikatowy eksperyment w Polsce (po pierwszym polskim modelu reasoningowym) podczas którego pokazaliśmy jak utrzymać jakość w kontekście j.polskiego (+innych europejskich). Jesteśmy gotowi by robić takie eksperymenty na większych modelach - mamy wypracowany standard, doświadczenia.
Dziękuję bardzo Krzyśkowi Ociepie - trening instrukcyjny oraz alignment, Krzyśkowi Wróblowi - benchmarki, Adrianowi Gwoździejowi - piękne dane, oraz Łukaszowi Flisowi (Cyfronet) - udostępnienie zasobów Helios do treningu instrukcyjnego, alignmentu oraz RL. Podziękowania dla Sebastiana Kondrackiego za motywację 👍💪 Dzięki team za świetną współpracę w projekcie. To jest złoty team, który nie tylko posiada wiedzę ale jest zaangażowany, pomocny.
Praca to głównie R&D. Model zyskał prędkość. Ma mniejsze wymagania sprzętowe. Natomiast to co istotne to zdobycie wiedzy i budowa potoku do tworzenia prunowanych modeli. Metoda wykorzystywana również przez Mistrala.
Proces szczegółowo opisaliśmy w publikacji: arXiv:2603.11881
Brawo zespół! Podziękowania dla #Nvidia.
Polski


Marcin Kliks retweetledi
Jeszcze tylko 2 godziny i zaczynamy GTC - jakieś akcenty bielikowe będą 💪🙏🇵🇱
Polski
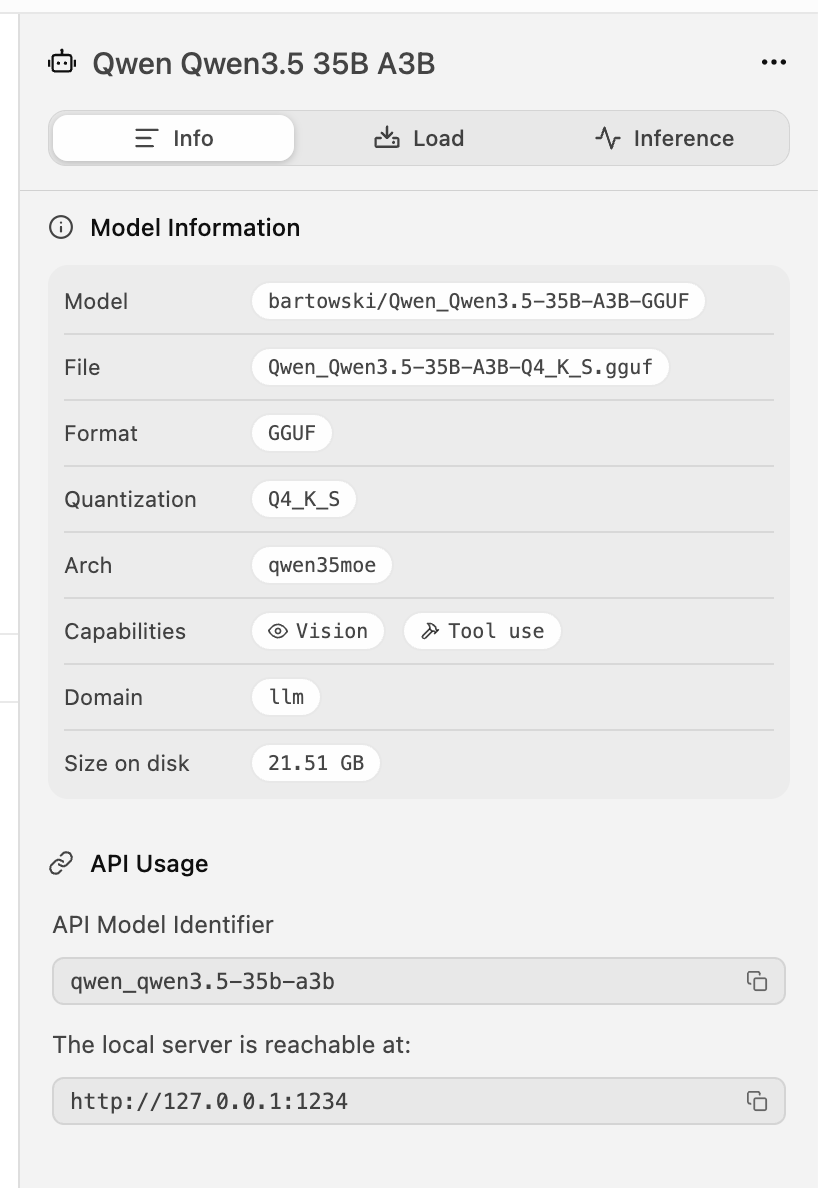
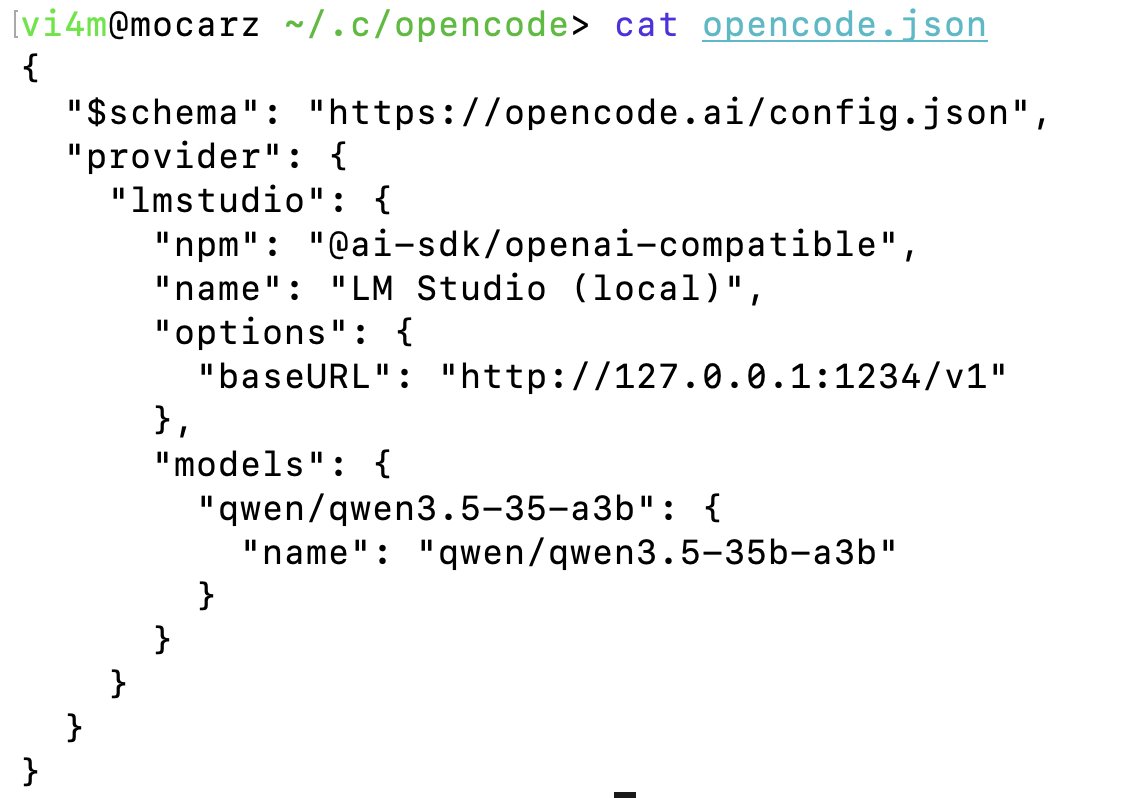
I tried various setups for LLM coding on the plane (100% offline) and this setup is the best:
* OpenCode
*Qwen3.5 - quant from Bartowski Qwen_Owen3.5-35B-A3B-Q4_K_S.gguf
* One shotted a few games with no problems on M4 Pro 48GB
* even turned on low-power mode to not juice entire battery
English
Marcin Kliks retweetledi

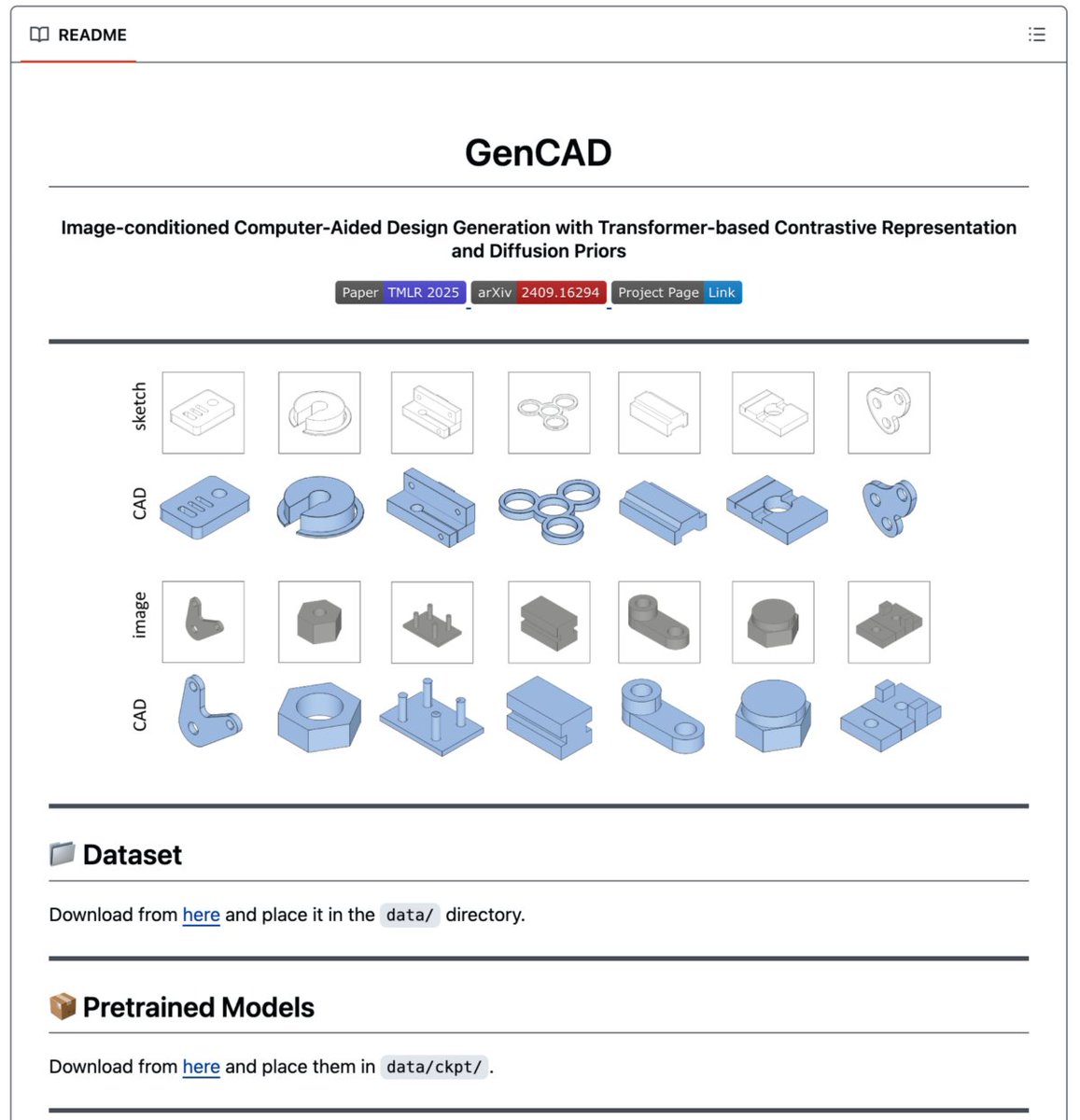
🚨BREAKING: MIT just dropped an AI model that converts photos into fully editable CAD programs and it quietly kills the $150/hour CAD modeling industry.
It's called GenCAD.
You give it an image. It gives you the complete parametric command sequence lines, arcs, extrusions ready for manufacturing.
Not meshes. Not point clouds. Actual editable CAD.
- Autoregressive transformers + diffusion models for image-to-CAD translation
- Outperforms every existing method on unconditional and conditional CAD generation
- Retrieves matching designs from 7K+ CAD databases using just a photo
- Trained on 840K+ images
- Generates multiple valid designs from a single input
The team also built CAD-Coder on top of this -- a vision-language model that writes CadQuery Python code from images with 100% valid syntax rate. Beats GPT-4.5 and Qwen2.5-VL-72B.
Built at MIT. Published in ASME Journal of Mechanical Design.
100% Open Source.
English
Marcin Kliks retweetledi

Qwen3.5 quantization: INT4 vs NVFP4 vs FP8 vs BF16
I ran full evaluations of quantized Qwen3.5 9B, 27B, and 35B — all vLLM-compatible.
Article:
kaitchup.substack.com/p/qwen35-quant…
A few practical takeaways:
- A good 4-bit Qwen3.5 27B remains much stronger than Qwen3.5 9B while fitting into a similar memory budget
- Be careful with the label “INT4”: some INT4 models end up nearly as large as the FP8 version because many sensitive layers are kept in higher precision.
- Quantized Qwen3.5 tends to think longer. So, while the models are faster and more memory-efficient, they will generate more tokens.
- For best quality, start by not quantizing linear attention. If needed, keep full attention in 16-bit too. That is also the strategy Qwen used for its INT4 releases, and it works well.
For MoE models: do not quantize the shared expert.
I ran these experiments on B200, H200, and RTX Pro 6000 GPUs, provided by @verdacloud (compute sponsorship).
English
Marcin Kliks retweetledi

Published some notes on @tobi's autoresearch PR that improved the performance benchmark scores of the Liquid template language (which Tobi created for Shopify 20 years ago) by a hefty 53% simonwillison.net/2026/Mar/13/li…

English
Marcin Kliks retweetledi

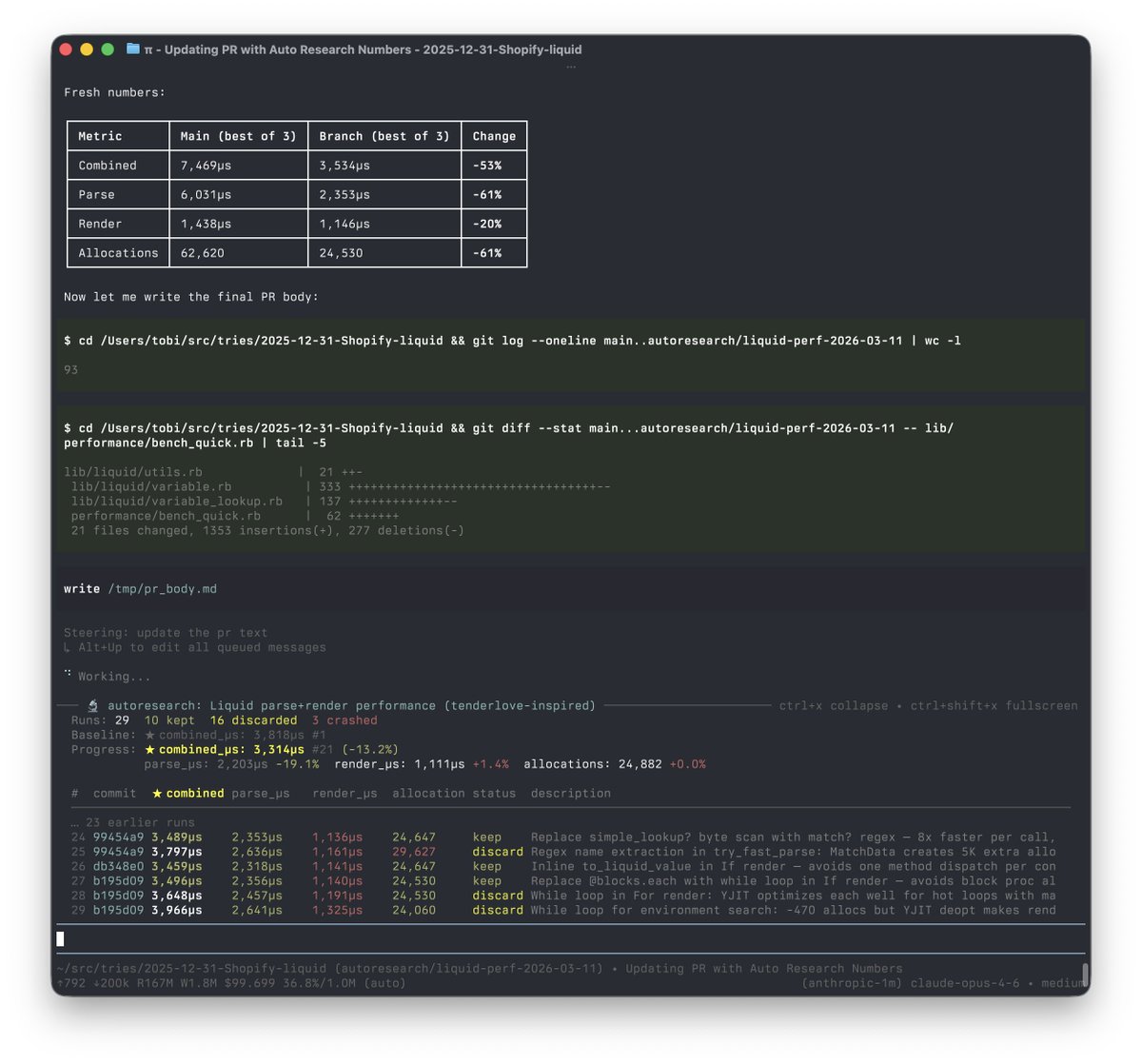
OK, well. I ran /autoresearch on the the liquid codebase.
53% faster combined parse+render time, 61% fewer object allocations.
This is probably somewhat overfit, but there are absolutely amazing ideas in this.
English
Marcin Kliks retweetledi

Huge congrats to the NVIDIA teams behind Nemotron 3 + NVIDIA AI-Q for taking the top spots on DeepResearch Bench I & II 🏆
DRB-I measures report quality — comprehensiveness, insight, instruction-following, and readability.
DRB-II pushes even further on recall, analysis, and presentation.
JFPuget 🇺🇦🇨🇦🇬🇱@JFPuget
Very proud that a cross NVIDIA effort led to top positions in Deep Research Bench I and II. DRB-I evaluates overall report quality: comprehensiveness, insight, instruction-following, and readability whereas DRB-II is more difficult and tests for information recall, analysis, and presentation. This was led by David Austin and @raja_biswas from my team. I contributed a bit. We will share more ASAP. huggingface.co/spaces/muset-a… #leaderboard" target="_blank" rel="nofollow noopener">agentresearchlab.com/benchmarks/dee…
English
English
Marcin Kliks retweetledi

Nemotron 3 Super is here! 🚀
Big capability jump, especially on agentic benchmarks, while staying built for efficient inference. Released the @nvidia way: weights + training recipes + code + datasets.
HF: huggingface.co/nvidia/NVIDIA-…
Tech report: research.nvidia.com/labs/nemotron/…

English
Marcin Kliks retweetledi

Fragments: reporting fines, engaging with gen AI, experience engineering, watching the ralph loop, migrating COBOL
martinfowler.com/fragments/2026…
English


