
Viktor Andersen
331 posts
Viktor Andersen
@vikfand
Profile picture by @johnnyacurso
Remote Katılım Ağustos 2010
270 Takip Edilen52 Takipçiler

If we made /slow mode in Codex, would you use it? What for?
(Slower inference at a cheaper cost)
English
@jgwtt @FistedFoucault He’s telling us about the mindset of German villagers of that time. They’re practical and not sentimental.
It’s probably exaggerated a bit and meant to be humorous.
English

@FistedFoucault Started watching. Why is he silently starts helping the father at the smithy. Like no hugs, no words exchanged,wtf? Is it common in Germany or is the director trying to say something to us?
English

Someone finally decided to upload the 9 part German miniseries HEIMAT from 1982 onto Youtube, with hardcoded eng subs👍
Some of the best TV that you will ever watch, it's about life in the fictional Hunsruck village of Schabbach from 1919 to 1982

English
Viktor Andersen retweetledi

"Dem rape me - I bin carry my six-year-old pikin wit me. Dem rape her too," one woman tell BBC.
She continue: "Den dem kill my younger broda for our front."
bbc.com/pidgin/article…
English
@hestehov_pavel @arvidkahl Whisper x med large-v2 er min erfaring
Dansk

OpenAI just released a new transcription model called "whisper-large-v3-turbo" — which is 8 times as fast(!!!) as their most recent highest-quality model. 🤯
I am currently deploying this to my fleet of servers.
This single change will likely 2x-4x the number of podcasts I can handle per day.
Besides that, it will increase the baseline quality of ALL transcriptions on Podscan. It will EVEN allow me to go through my backlog much faster. That means faster alerts and more historical search data for Podscan.fm customers.
OpenAI is the gift that keeps on giving.
English
Made my first website with bolt.new - visualize password strength based on length and types of characters. Made only by AI!
@stackblitz

English
@thepatwalls The Wizper model from fal.ai is the cheapest and fastest available
Just make an account there and you can use it from the browser
You can also use my app Teksta.no if you want to have the transcriptions stored on your account, searchable, etc.
English

@nikelsnik @nextjs Thanks! Very js that there is an external library for safe actions
English

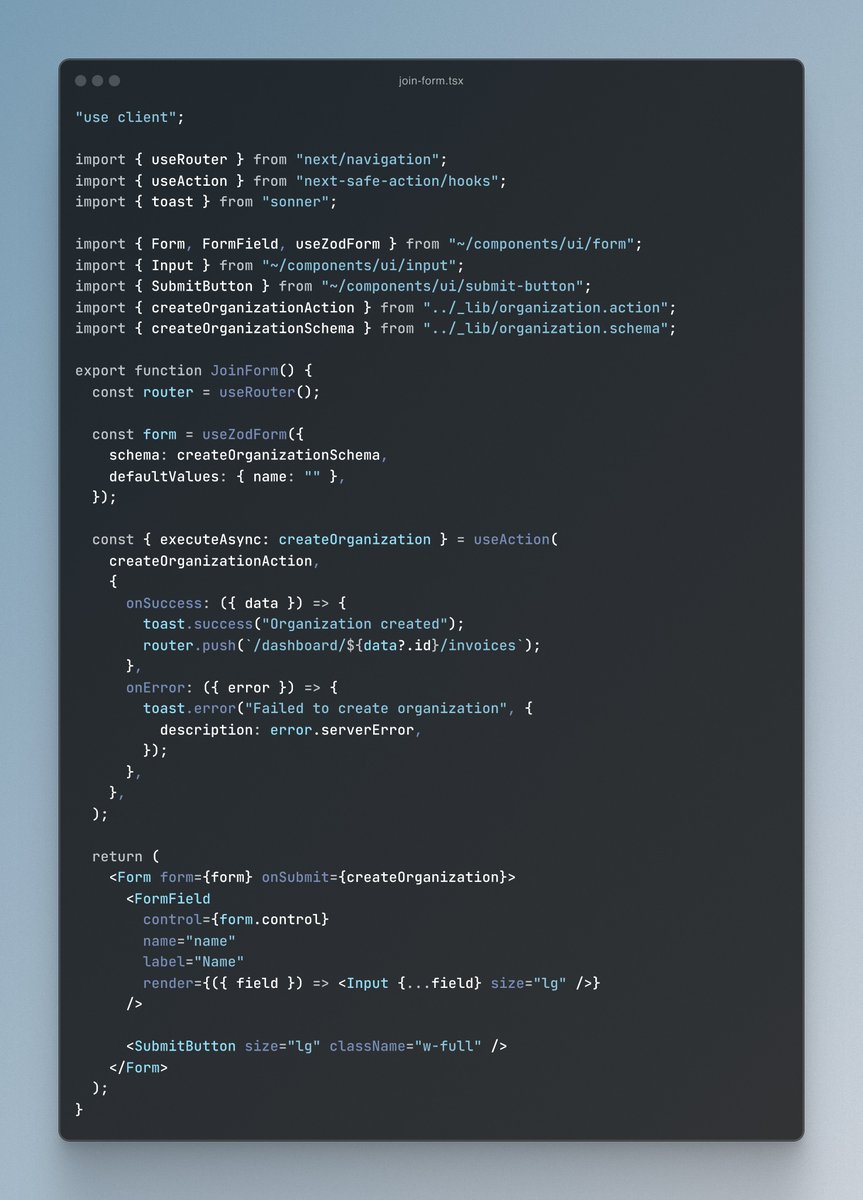
My go-to method for handling forms in @nextjs
* react-hook-form -> form handling 📋
* zod -> validation ✅
* shadcn/ui -> UI components 🧱
* next-safe-action -> server actions ☁️
* sonner -> success/error toast messages 🍞
English

Added audio + voice now to this using @synclabs
Nicolas Neubert@iamneubert
Let's bring in some motion, shall we?
English
@ky__zo There are many ways to run Whisper. See github.com/viktorfa/aweso….
If speed is important, use Gladia or Sieve or run your own work e.g. Modal.
Replicate can be quite slow because of boot time.
English

I was wrong:
1) Apparently, Whisper is not one, but multiple different models from which large-v3 is the best one
2) For some reason OpenAI's API is not based on large-v3, but large-v2 (which is ambiguously called whisper-1 in the docs). There's no way to change the model
3) For whisper-1 (large-v2), I used "Prompt" (not initial prompt, but prompt) as guidance for the model of how to spell the words. I assumed it'd work if I just paste the full text of the transcript. This was the reason why sentences or individual words were skipped in the transcript.
4) I moved from OpenAI API to Replicate (large-v3) and the result is much better, although latency increased (from ~3 sec to ~10 sec for 1-minute long audio).
5) Everyone is recommending deepgram.com and I don't know it that's because it's really that good or it's just marketing.
kyzo@ky__zo
OpenAI's Whisper is SO BAD, I can't... I regret using it in copycopter.ai. It randomly skips words and full sentences in the transcript. What should I use instead?
English
English

@levelsio Does it work with a piece of clothing as input, but a completely ai generated person?
Clothing companies could be OK with 10 photos of a random person, and not a specific ai model
English
The cool thing is after dressing your AI model with clothes, you can also change the setting and light simply by writing a prompt text with PhotoAI.com
🏝️ In this case I put my AI model "on a beach at sunset on a tropical island" with this specific jacket
There may be less need to fly around models and crews of photographers, light people, directors, producers, etc. half way around the world for a shoot in the future:
Just upload clothes, choose your AI model and prompt your shoot
Not perfect yet but will get better and possibilities are infinite, it works already on Photo AI now


@levelsio@levelsio
English
@nootropicguy Is this the same as normal galangal used in many Thai dishes?
English

Why is nobody talking about Thai Ginger yet?
It’s Nature’s Ritalin but without the jitters & irritability
Why?
It’s one of the only herbs that can supercharge dopamine levels after 1 dose
- Writing is almost effortless
- Makes boring work more fun
- Flow state w/o irritability
Recent studies show its both a potent nootropic & aphrodisiac herb:
1) Enhances alertness within 30 minutes WITHOUT any jitters or sleep disruption
2) Enhances motivation & focus by increasing dopamine levels (through dopamine reuptake inhibition like Ritalin)
3) Enhances attention for 3 hours when combined with caffeine
4) Enhances memory by increasing acetylcholine levels (via AChE inhibition)
5) Reduces mental fatigue for 5 hours (via modulating adenosine signaling)
6) Increases testosterone levels
7) Reverses SSRI-induced erectile dysfunction
8) Boosts LH & FSH secretion
9) Enhances fertility including sperm count, ejaculate volume, sperm motility, etc
10) Increases blood flow to and size of testicles
11) Protects testicles from oxidative stress damage
The best part?
Multiple human trials have shown Thai Ginger is extremely safe even at high dosages
And unlike caffeine & Ritalin, it doesn't affect heart rate, blood pressure, or sleep
It actually outperforms caffeine when it comes to boosting focus
One of the most impactful herbs I tried in 2023




English
@alonewolfchen @KhaosodEnglish Read the early life section on their Wikipedia page
English

@KhaosodEnglish How many are ethnically Chinese? My guess is 90%
English

Here are top Thai billionaires (in US dollars) according to Forbes. Worth noting are Dhanin Chearavaranont of CP Group at Number 1 with 12.5 billion dollars. At # 2, Beer Chang, or Thai Bev's Charoen Sirivadhanabhakdi, with 11.3 billion & Thaksin at # 10 with 2.1 billions.

English
Norsk

Dataen finnes der ute, om du veit hvor du skal leite:
– Jeg tror man kunne fått til en utrolig stor verdiskapning, sier @digdir_no. 💪
– Men løsningene er nok dessverre ikke så godt kjent blant utviklere.
kode24.no/artikkel/samle…
Norsk
@sanjudotio @arvidkahl I'm my experience it does as you would expect 😂 Especially in other languages than English
English

@arvidkahl How does whisper do with company names / proprietary words (like startup names)? I can imagine that being a limitation for enterprisey users.
Such a cool project btw.
English
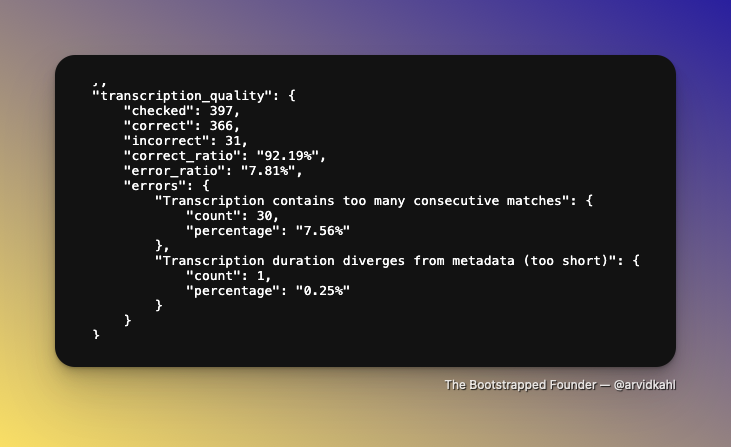
Took me two days to get the Podscan.fm transcription quality levels from 75% to 92%+!
I had to slow down my backend, switch tech, and track a lot of errors. Here's what I did:
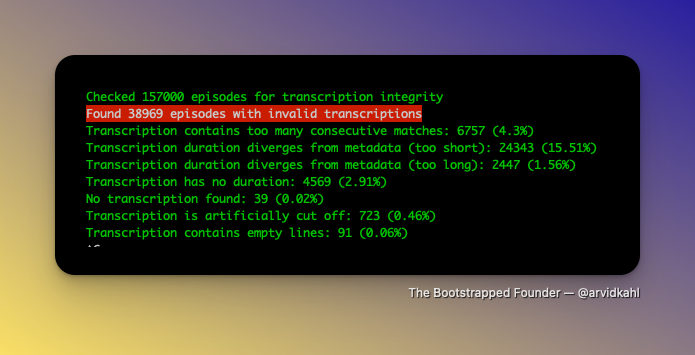
The green/red image shows yesterday's data. A LOT of incomplete (too short) transcripts. I turned on a lot of logging to investigate where this happened.
I had a few suspects: my really crappy handwritten SRT parser, or maybe the Python script calling insanely-fast-whisper, or ifw itself.
Turns out it was insanely-fast-whisper itself. It's SO fast that in 20% of cases, it produces results that may lead to a process crashing, cutting the transcript short.
So i changed it to faster-whisper, which I had used before. Obviously, as they're aptly named, this has cut my transcription speed in half, but going from 15% "too short" to just 0.25% is worth taking the hit.
Once my API was reconfigured to run faster-whisper, the error rates just plummeted.
Over the next weeks, I'll slowly and autoamtically retranscribe all older episodes with incomplete transcripts.
Oh, and the consecutive match error is hit-or-miss. A fraction of that is actually a problem, but I track it to make sure the system doesn't hallucinate too much.
The more I work on this, the more I understand why noone has built this before. It's hard. Data is weird, and at scale, it's SUPER weird. Edge cases everywhere.
English
@arvidkahl YouTube view numbers are public. But linking from podcast feed to its YouTube video is perhaps not trivial
English
Ha, ran into an interesting problem. At some point during early development of Podscan, I decided that 2hours would be my cutoff point for transcripts, cause it costs a lot to transcribe hours.
But pods like Lex Friedman go 3h on the regular.
Need to rethink the limit.
Either, I lift it completely or I change the limit on a per-podcast level. The first one has more risk, but the second one has more tedious work and maintenance requirements.
Hmm...
Not a very challenging change, but one that impacts the product.
Might just raise it to 4h for now.
English
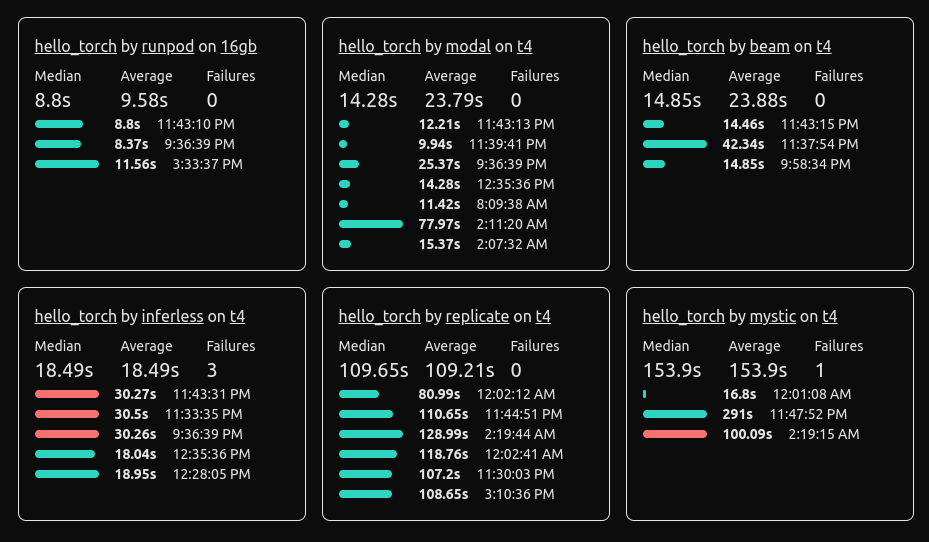
I tested 6 different cloud providers for serverless GPU and benchmarked their cold starts.
Some variance in performance, but I discovered quite amazing ways to deploy code.
English
@ytrevenstrenett Forskjellige deler av utenriksapparatet er under påvirkning av forskjellige krefter.
Norsk

Jeg forstår ikke rasjonalet bak å støtte den ene parten med våpen og den andre med nødhjelp.
Hva er det USA vil?
🪖MilitaryNewsUA🇺🇦@front_ukrainian
⚡️🇺🇸American products dropped from US Air Force aircraft on the coast of the blockaded Gaza Strip.
Norsk