Vim retweetledi
Vim
25.2K posts


Vim
@vim_dzl
Presidential Fitness Test Award Winner | 🤘🌁🗽| Training/Finetuning @basetenco, ex-@Plaid | Professional Attender of Weddings | DM for consulting inquiries
New York, USA Katılım Temmuz 2017
1.3K Takip Edilen935 Takipçiler


Vim retweetledi

This was one of our early steps to explore the characteristics of different learning algorithms. How important is it to be on-policy? How important is it to have dense rewards? We can roughly place different approaches (SFT, RL, vanilla distillation, on-policy distillation, on-policy self-distillation, iSFT) on this grid of "on-policiness vs reward density" and use constitutional alignment as the test bed to explore how they drive internalised behavioural changes in the model. We find that being on-policy AND having dense rewards both matter for internalising the values in the constitution we're training on, and that this internalisation generalises in surprising ways (eg significant improvements on BullshitBench v2). Awesome stuff from @kirkby_max!
Max Kirkby@kirkby_max
English
New hiring strategy is to sit in barbershops and see who can successfully prompt their barber about what haircut they want. If you can prompt that you can prompt Opus 4.6 to find your context parallelism bug
English
Vim retweetledi

The Posit team is behind some of the most widely used data science tools, including RStudio and Positron. Posit uses Basten Training and the Baseten Inference Stack to:
-> Spin up training compute in 1 minute
-> Generate code edit suggestions in <200ms (60% faster than other providers)
We're excited to power @posit_pbc's newest AI features!
Read the full case study here: baseten.co/resources/cust…
English
Vim retweetledi
This is one of the early steps we took into researching truly infinite context with repeated, smart KV cache compaction. We have some more bitter lesson continual learning/cache research coming soon!
Baseten@baseten
Long-running agents accumulate context while model memory stays fixed. This leads to a tradeoff: either discard older information or compress it. New work by @oneill_c explores repeated KV-cache compression for persistent agents using Attention Matching. Our research shows one-shot compaction preserves detailed information remarkably well with 65–80% accuracy at 2–5× compression. This far outperforms text summarization. But what happens when you compress, add more context, and compress again repeatedly? baseten.co/research/repea…
English
@HEBenjoyer @stfukhi Ah I do not have that data. But I will take your word for it.
English


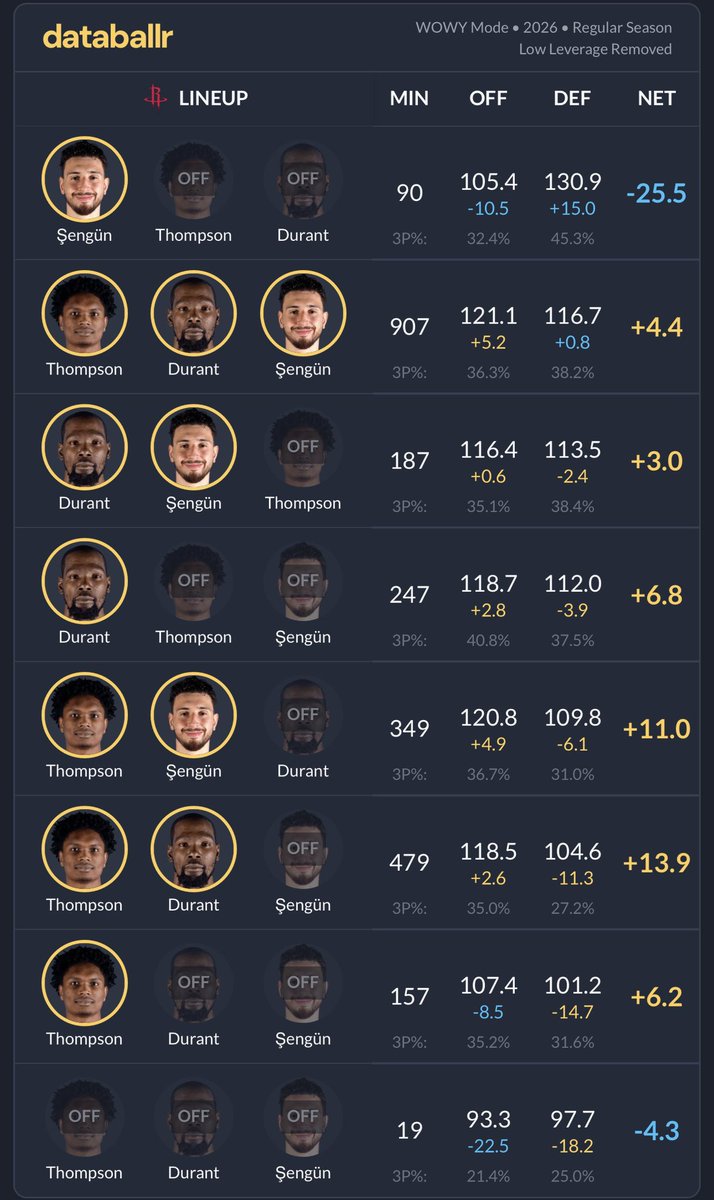
@HEBenjoyer @stfukhi Matches exactly what we saw against the Knicks to start fourth. Every possession they attacked Reed and Sengun.
English
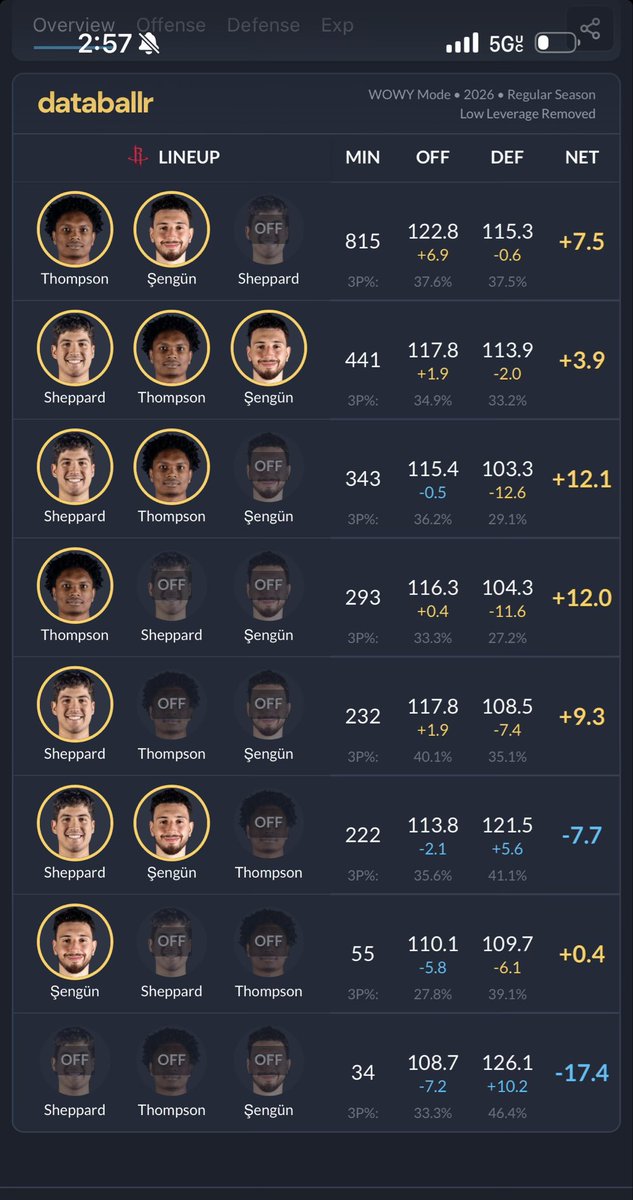
Can't wait to rip through this. If you're interested in the inference space, this is a must cop
Philip Kiely@philipkiely
Inference Engineering launches today. baseten.com/inference-engi…
English

In December 2025, I suffered significant head trauma from a snowboarding incident. After an ER visit, I had tons of questions about how to best recover.
I went to see my PCP, and upon hearing out my case, they turned their screen around and it's @OpenEvidence 💚🧡
Baseten@baseten
"No other product lets you launch ten different training jobs on four different datasets." –Head of Clinical NLP, OpenEvidence Over 40% of U.S. physicians trust @EvidenceOpen's platform for fast, accurate medical information. Their secret: custom, specialized models built on Baseten Training. Here's how we helped them save $1.9M via model training and improved their latency 23x to power 100M+ clinical consultations per year. baseten.co/resources/cust…
English
Vim retweetledi
GLM 5 is live on Baseten.
Opus 4.6 level performance at 10% of the cost.
It takes the intelligence from its predecessors and layers in long-horizon agentic capabilities and complex systems engineering. That means your model can now do more than just chat (or code). It can solve sticky issues, call tools, and cohesively answer the problems we face in real life use cases at work.
Get access on Baseten with our Model APIs or a dedicated deployment.
baseten.co/library/glm-5/
English
So blessed to work with the most talented + humble folks I’ve ever met. Come join us at Baseten!
Charlie O'Neill@oneill_c
Come join @baseten where you get to research and be part of an index on AI to expose yourself to all of it
English
Loved reading this one - really awesome work from the team. Baseten Training to the moon
Baseten@baseten
We replicated Microsoft Research's Generative Adversarial Distillation (GAD) to distill Qwen3-4B from GPT-5.2. Standard black-box distillation teaches a student to copy teacher outputs, but at inference the student generates from its own prefixes, small errors compound and it drifts off the expert distribution. GAD reframes this as an on-policy distillation problem, training a co-evolving discriminator that provides adaptive reward signals on the student's own generations. Exploring methods like this are how our post-training team surfaces new training patterns. Read here: baseten.co/resources/rese…
English