Vinod Sharma retweetledi

This is the single best read on World Models and one of the most important reads in AI.
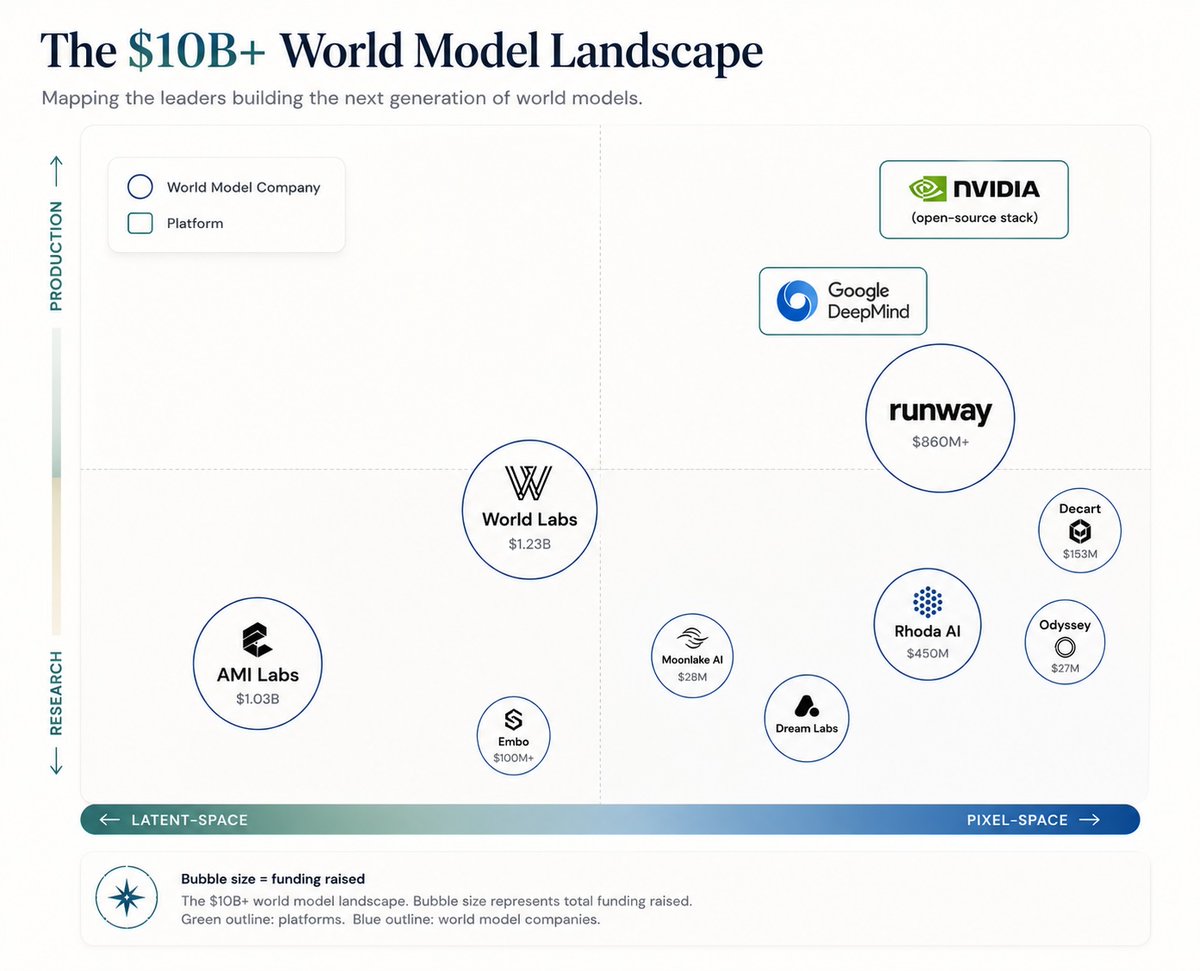
$10B has flowed into "world models" in the last 18mos, from Yann LeCun to FeiFei Li. The promise is, like LLMs, world models will provide the data it takes to scale robotics foundation models, and solve robotics.
..but the word has been abused to mean one of many things.
This post unpacks:
– What 5 traits makes a world model?
– How do the different approaches stack up?
– What is it used for within and beyond robotics?
– Where is the opportunity?
– Citations to research, news and blog posts
Companies / products in the space include:
– BigCo products: Google Genie, Tesla Optimus, Nvidia DreamDojo, DreamZero, Microsoft Muse
– Pure world model: AMI Labs, World Labs, Runway, Rhoda, Decart, Spaitial, Odyssey, Embo, Dream Labs, OneWorld
– Robot foundation model cos: Skild, Physical Intelligence, Figure, Mind
Very likely one of the seminal technologies of the next decade.
English