
kokostr
74 posts






我收到 🇯🇵 offer 了!!!
雖然是 contractor,但可以先拿工作簽證,薪資福利也都與正職相同,而且是我想做的後端職位,用日文面試但大家都會講英文,有口頭承諾未來可以轉正社員但我會持保留態度。
我想,夢想中的一步到位鮮少發生,通常是還沒準備好就得忐忑地邁出下一步,現在就先踏出這一步吧!
中文





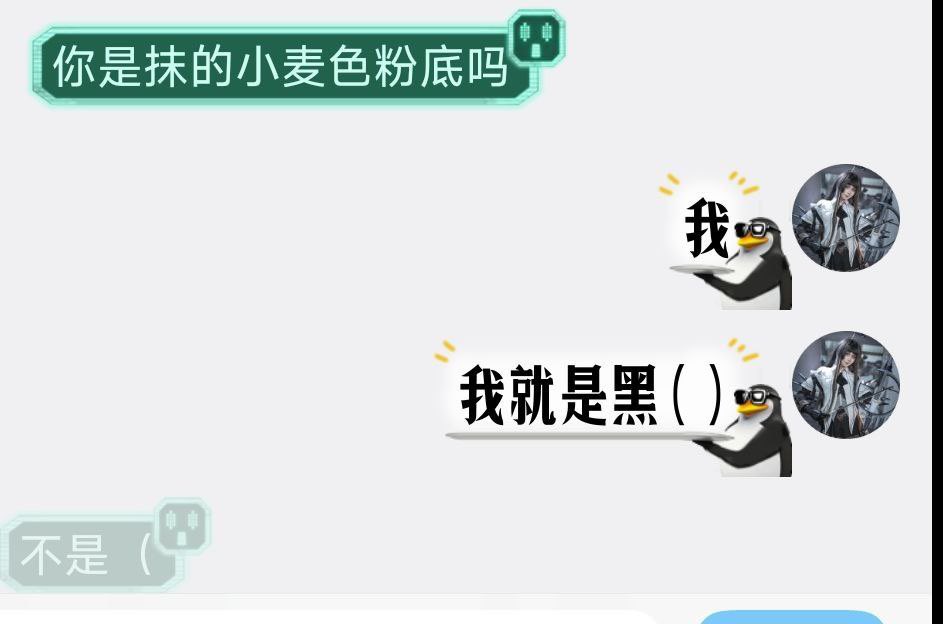
今天朋友圈都被那个人格测试刷屏了,本来就是个娱乐的玩意,我看有些人又当真了。
借着这个现象分享一个我个人的小经验,算是经历过N多样本后得出的结论,仅供参考:
那种上来就说自己是什么INFP、ENFJ人格,或者强调自己是什么星座的人大多脑回路和正常人不一样,几乎没有正常沟通和解决分歧的能力。
比如遇到矛盾和分歧喜欢强调“我就是这样的人,你得理解我,我改不了”
本来需要沟通就能解决的问题,她们却觉得“我是XX型,你是XX型,咱们当然合不来”,把动态的活人简化成几个固定模板,或者直接把责任甩给“人格”或“星盘”
总结就是巨婴、死倔,听不进去人话。
这种人通常也没有学习和自我成长的能力。
中文










通义千问新出的 Qwen3.5-35B-A3B,直接把单卡长上下文推理卷到了新高度。
350亿参数的模型,但每次生成只激活30亿参数,用的是门控增量混合架构:256个专家,每次只调用8个,每4层才做一次注意力计算,天生就省算力、省显存。
最离谱的是长上下文表现:
单张24GB显存的RTX 3090,直接开满 262K超长上下文,跑出 112 token/秒,而且从4K到262K上下文,速度几乎不掉!
传统35B模型一上长上下文,KV缓存爆炸、速度暴跌,24GB显存根本扛不住。
而这模型40层里只有10层用普通注意力,剩下30层是固定显存的循环结构,上下文再长,显存占用几乎不变。
满跑262K上下文,总显存才 22.4GB,24GB显卡轻松拿下。
更夸张的是社区力量:
5天、15块显卡,峰值速度冲到 176 tok/s。
48小时内,各路显卡都刷出了高分:
• 优化前:默认50 tok/s左右
• 优化后:直接翻倍,5090跑到176 tok/s
核心就5个参数,把层全卸到GPU、压缩KV缓存、开满上下文、精简循环状态、开Flash Attention,一夜之间性能质变。
总结一句话:
一张消费级显卡、24GB显存、零API费用,就能跑35B级、262K上下文、百tok/s级的大模型。
这不是小升级,是本地AI推理的里程碑式突破。
中文

