MAX retweetledi

MAX
4.8K posts


Ronin. Is. Home. Migration to Ethereum complete ⚔ Five years ago, Ronin was a new Ethereum sidechain with a single game aboard: Axie Infinity. Over the years, Ronin emerged as THE gaming chain, onboarding millions of players through more games like Pixels, Cambria, Angry Dynomites, and many others. Today, we plugged our engine into the mothership: Ethereum. Here’s what that means 🧵👇


Today's a day we've been building towards for years. @Ronin_Network is officially an Ethereum Layer 2. @VitalikButerin recently said that the era of generalized L2s is over. We agree. Ronin was built for a very specific use-case. To scale Axie beyond crypto, to everyday people. Over the years, it's become more than just the chain for Axie. A crew formed. An alliance of games and apps looking to make crypto fun, accessible, and educational. Today we've plugged Ronin back into Ethereum to become the most interesting, entertaining, and welcoming way for regular people to step into crypto. We are Ethereum's gamification engine. This is a full circle moment, and wouldn't be possible without the tireless, often thankless efforts of the @ethereum developer community, who've made it much much more sensible to run an L2 compared to an L1 or side chain. When we created Ronin, L2s were just an idea. Today, blob fees are affordable. The tech and security is battle tested. The benefits: > By using Ethereum for security we no longer have to pay for our own security costs via inflation while inheriting the security of the largest smart contract platform ever created > Much easier to tap into liquidity and shared network effects from Ethereum > Reduced inflation and improved $RON tokenomics due to the costs we save on incentivizing network security > Ronin is now 50% faster Today we're also rolling out upgrades that make Ronin even more unique: > The proof of distribution system is now live and operational, programmatically dispersing rewards to builders based on metrics that have been most correlated with $RON momentum in the past: pod.roninchain.com > The Ronin treasury has been bolstered with new streams of value: 1.25% of all NFT volume on Ronin, all sequencer fees, and 90 M RON that was previously set aside for staking rewards > We've rolled out a new landing page for welcoming participants to the ecosystem: roninchain.com It's been a long journey. From the early days in the CryptoKitty community. From 30 users to millions. From Axie to an entire roster of games. And somehow, it's clear to me: this is just one more step on a path that stretches many years ahead of us. We choose to move forward, not because it's easy, but because it's hard and if it works, we have a chance to make history. Again.


0/ Clear signing is now live. An open standard to end blind signing, making human-readable transactions default. This effort brings a major UX and Security upgrade to transaction signing on Ethereum.



好像不是2018年的剧本哦! BTC已实现盈亏比的90d-sma已经坚定的站上1(由红转绿),这是个重要的分水岭。 我在图中用蓝色虚线箭头标出了在过去12年里与之相对应的位置。BTC都无一例外的从“深熊”步入“熊/牛转换”阶段。 直到此刻我都不敢相信,这次竟然只用了短短75天。 主观上我希望BTC再下去一回,最好能破前底,因为我还没买满。但客观上数据告诉我,这个概率已经越来越小了。 啊,真的有点人格分裂了..... 你们说,我接下来应该喊多,还是喊空好呢?🤣🤣🤣



Blind signing has contributed to billions of dollars in losses across the ecosystem. Every transaction you sign should clearly show who you're interacting with, what you're authorizing, and on what terms. At Trezor, we are committed to security and transparency, and we will be implementing Ethereum Foundation's Clear Signing open standard across all our products over the coming months. Security shouldn’t require technical expertise.


1/ Two years after BUIDL, Blackrock launches two more tokenized funds — on the most biggest, most institutional public blockchain: Ethereum.



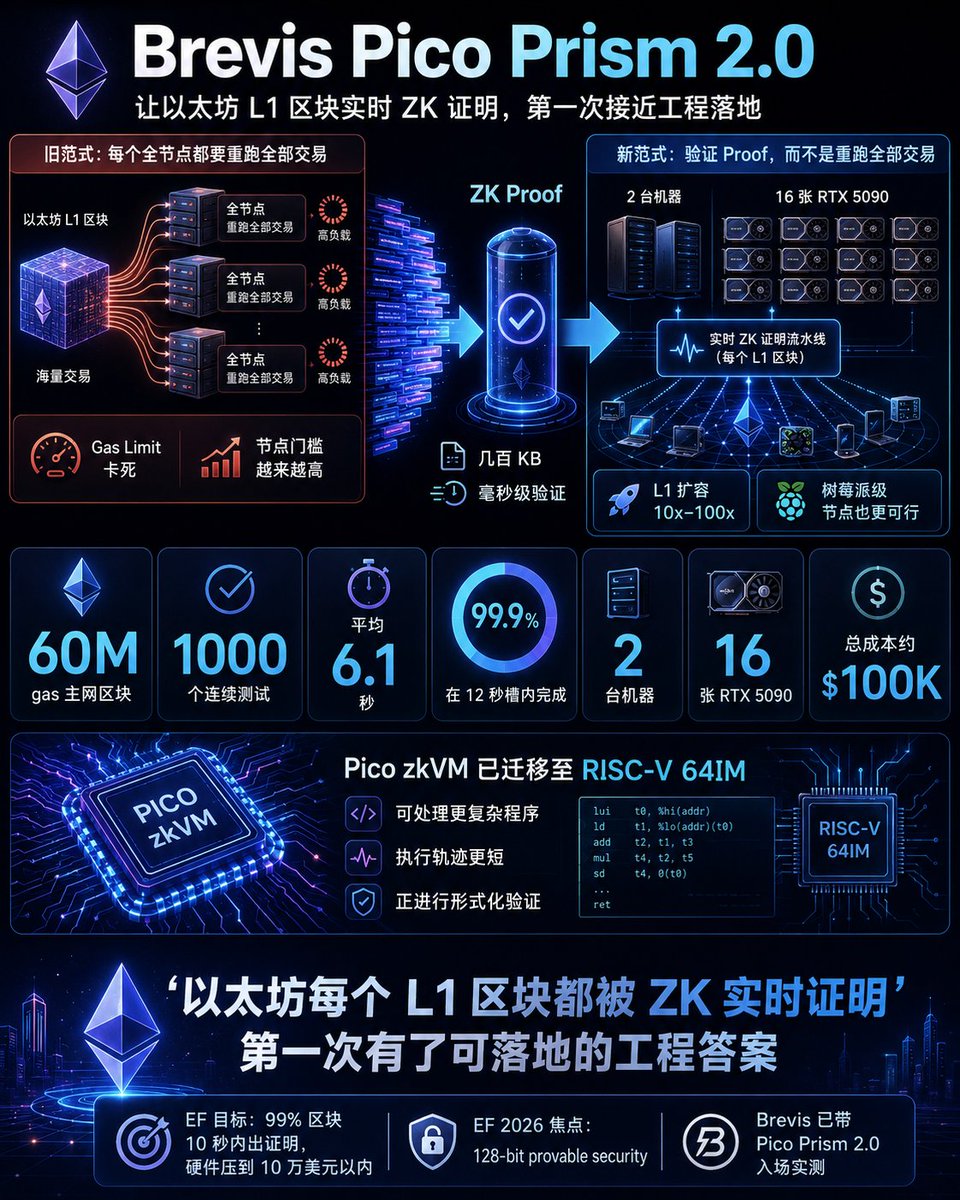
Pico Prism 2.0 is live 🔥 Real-time Ethereum proving on the 60M gas mainnet blocks Ethereum runs today. 🧵


INSIGHTS: Vitalik just said what the data already showed. For years banks said: we want blockchain. But not Bitcoin. Not Ethereum. We'll build our own. Their blockchains promised the best of both worlds. They delivered the worst. Centralized enough to be controlled. Decentralized enough to be slow. Private enough to exclude the public. Open enough to exclude real privacy. His solution: Don't rebuild. Retrofit. Add cryptographic proof to existing servers. Anchor to Ethereum. Done. The man who built Ethereum just told institutions: You don't need your own chain. You need ours.


1/ Two years after BUIDL, Blackrock launches two more tokenized funds — on the most biggest, most institutional public blockchain: Ethereum.


Downloading now... 1M token context window with supposedly usable coding agent capability all on a 128GB Macbook Pro is 🤯
