
wellback000
4.6K posts
wellback000
@wellback000
Hold on your bitcoin. There's only 21M! Buy the gold. Gold is real money! Bitcoin is e-gold in the future.
Katılım Mart 2019
2K Takip Edilen232 Takipçiler

wellback000 retweetledi

wellback000 retweetledi

温斯顿·丘吉尔曾用砌砖来对抗抑郁症。他在肯特郡的乡间别墅里一砌就是好几个小时。他还加入了砌砖工工会。1921年,他撰文阐述了这种方法为何奏效。心理学界又花了75年才追上这一发现。
他将自己的抑郁症称为“黑狗”。几十年来,它如影随形。他对抗抑郁的方法听起来很简单,做起来也确实如此:一块接一块地砌砖,一小时又一小时地砌。
丘吉尔在《斯特兰德杂志》上发表的一篇长文中详细阐述了这一理论。他写道,以思考为生的人,不能仅靠休息来修复疲惫的大脑。他们必须调动自身另一部分——那部分能驱动双眼和双手的部分。木工、化学、装订、砌砖、绘画……任何能让身体投入到大脑无法独自解决的问题中的活动。
现代心理学将此称为“行为激活”。这是目前研究最广泛的抑郁症治疗方法之一。抑郁症会设下行为陷阱:你感到难受,于是停止行动;行动减少,就更难获得愉悦感;情绪恶化又让你进一步减少行动。这个循环不断收紧,直到你窒息其中。
行为激活从行动层面打破了这个循环。你先安排好活动,即使你全身心都不愿意。付诸行动会带来微小的回报:墙壁变得更笔直,画作逐渐填满,凌乱的房间变得整洁。这些微小的回报会慢慢重塑大脑。行动在先,感觉随后。
华盛顿大学的研究人员于2006年对此进行了验证。他们研究了241名重度抑郁症成年患者,并对比了三种治疗方法:行为激活疗法、常规谈话疗法和抗抑郁药物。对于抑郁症状最严重的患者,行为激活疗法的效果与药物相当,且优于谈话疗法。2014年对26项试验中超过1500名患者的研究综述也证实了这一结果。
像砌砖这样的体力劳动在此基础上还起到了额外的作用。它排除了“反刍”——即在抑郁最严重的时期,那些循环往复的消极念头会让人精疲力竭。砌砖需要双手操作,且能带来逐块砖的反馈:每块砖都是笔直的或歪斜的。一小时后,你能清楚地看到自己砌了多少墙。再也没有空间让那些消极念头在脑海中反复咀嚼了。
乔治·麦克(George Mack)在帖子中写道:“抑郁症讨厌移动的目标”,这句诗意盎然。而其背后的科学原理则更为精辟:抑郁症讨厌那种心系别处的大脑。

中文
wellback000 retweetledi


wellback000 retweetledi

Stanford CS336 上,Tatsu 讲了一节 LLM 架构课,把过去 3 年所有主流 LLM 拆开,看它们的共通模板
结论挺爆:90% 的架构选择已经收敛,你随便挑一个开源大模型,它跟其他模型在这些维度上几乎一模一样
讲师的原话
- 2024 年大家都在 cosplay Llama2
- 2025 年的主题是「怎么训得不崩」
- 2026 年的主题是「怎么扛住长上下文」
下面是 2026 年开源 LLM 的标准模板 你训自己的模型可以直接抄
【架构层 已经收敛的 7 件事】
1)Layer Norm 挪出残差流(pre-norm)
原版 Transformer 把 LN 放在残差里 几乎所有现代模型都挪到外面
原因:keep your residual stream clean 梯度反传更稳
2)RMS Norm 替代 LayerNorm
LayerNorm 的减均值 + 加 bias 那部分实际没怎么帮上忙
丢掉之后 flops 只省 0.17% 但运行时省到 25%
(瓶颈在数据搬运 计算反而次要)
3)所有 bias 项全删
跟 RMS Norm 一个道理 系统层省内存搬运
4)激活函数用 SwiGLU 或 GeGLU
gated linear unit 几乎所有现代模型都用
Llama 系 / Qwen / Mistral 用 SwiGLU
Google 系(Gemma / T5)用 GeGLU
区别极小 选哪个都行
5)位置编码用 RoPE
2024 年之后基本统一了
原理:把每对维度按位置旋转一个角度 让 inner product 只依赖相对位置
6)Transformer block 串联(不是并联)
GPT-J / Palm 试过并联 现在基本被放弃
串联的实现优化得太好了 并联省的那点系统开销不值得损失表达力
7)Layer norm 可以「撒」
哪儿不稳就在哪儿加 LN
attention 之前能加 之后能加 两边都加(double norm)也可以
现代模型很多这样做
【超参数 已经收敛的 5 个数】
1)feedforward 维度 / hidden 维度
- 非 GLU 模型:4 倍
- GLU 模型:8/3 ≈ 2.67 倍(因为 GLU 多一组矩阵 要保持总参数量)
- Llama 系:3.5 倍
- T5 1.0 试过 64 倍 后来 T5 1.1 改回标准 别学
2)head 数 × head 维度 ≈ hidden 维度
几乎所有模型都遵守 T5 是为数不多的例外
3)模型纵横比(hidden / 层数)≈ 100
太深 pipeline parallel 难做
太宽 表达力受限
100 这个数字是系统约束 + 表达力的平衡点
4)vocab size
单语模型:30K 左右(早期 GPT-2 那种)
多语 / 通用模型:100K-200K(GPT-4 / Llama 3 / Gemma 都在这个范围)
现代基本都是后者
5)weight decay
仍然普遍使用
但研究发现它在 LLM 里干的事其实是优化器干预 让你最终能收敛到更深的最优点
跟你想的「防过拟合」没什么关系
所以别因为「单 epoch 不会过拟合」就把它关掉
【稳定性 三个救命 trick】
训练大模型最怕中途 loss 突然飙升 然后 NaN 全军覆没
现代模型用三个 trick 防这件事
1)Z-loss
output softmax 的 normalizer 容易爆
加一个 (log Z)² 的正则项 让 Z 始终接近 1
DCLM / Olmo 都用
2)QK norm
attention 的 Q 和 K 在矩阵乘之前各加一个 LN
让 softmax 的输入永远是单位尺度
multimodal 圈先用起来 现在所有大模型都加
3)Logit soft cap(仅 Google 系)
attention logit 用 tanh 硬封顶
Gemma 2/3/4 都在用 但会损失一点点性能 慎用
【Attention 两个新趋势】
1)GQA(Grouped Query Attention)几乎统一
原版 multi-head 推理时 KV cache 会让算术强度崩到 1/h
GQA 共享 K 和 V 但保留多个 Q
表达力几乎不损失 推理成本砍掉 80%
现在所有要做生产部署的大模型 没有不用 GQA 的
2)局部 + 全局 attention 交替
处理长上下文的新方式
Cohere Command A 起头 现在 Llama 4 / Gemma 4 / Olmo 3 全在用
比如每 4 层有 1 层 full attention 其他 3 层是 sliding window 只看附近的 token
比纯 SSM 更稳 比纯 full attention 便宜得多
(Qwen 3.5 做了变体 把 sliding window 那 3 层换成 SSM)
收尾一句
如果你正在训自己的 LLM,上面这一套就是 2026 年的「默认配置」 不需要重新发明,直接抄
如果你只是想看懂 GitHub 上那些 modeling_xxx.py
这一份足够你不再被术语吓住
Roan@RohOnChain
Anthropic pays $750,000+ a year for engineers who can build LLM architectures from scratch. Stanford taught the entire thing in 1 hour lecture & released it for free. Bookmark & watch this today before someone takes it down.
中文
wellback000 retweetledi

兄弟们!Google 刚刚更新了Code Wiki!
Google 直接把开发者最头疼的“读代码”瓶颈,一键干掉了。
他们刚刚发布的 Code Wiki,让任何一个代码仓库Github都能瞬间拥有一个永远最新、结构化、 智能可聊的 Wiki。
核心三招狠活:
- 自动扫描仓库,代码一改文档就实时更新,再也不用担心文档过时
- Gemini 驱动的智能聊天,直接把整个 Wiki 当知识库,回答问题还能超链接跳到具体代码行
- 自动生成架构图、类图、时序图,点一下就能从解释直达源码
新手第一天就能上手,老代码没人维护也能秒懂,大库小库通吃。
Google 自己都说:“读现有代码是软件开发里最大、最贵的瓶颈之一。”
现在,这个时代终于要结束了。
公共仓库已开放预览:codewiki.google
你觉得 Code Wiki 会不会成为下一代代码理解标配,把“读代码”从痛苦变成享受?

中文
wellback000 retweetledi

中国的一位女开发者
用ClaudeCode做了一个音乐电台Agent
起名叫Claudio
是一个24小时在线的AI电台主播
蒸馏了她十四年的歌单
从歌单、到界面交互、到审美,都很棒
Claudio的声音也很有磁性
会介绍音乐
会根据日程安排和时间选择播放什么音乐
整体非常有调性
让人看到“去APP化”、全民高定agent服务会是未来可能的方向
#ClaudeCode
#VibeCoding
中文
wellback000 retweetledi

wellback000 retweetledi
wellback000 retweetledi

【Codex 真的牛!】
还在剪映里一帧一帧手动抠视频?
醒醒,AI已经把剪辑效率卷疯了
我只在 Codex 里敲了一行字,装上 HyperFrames 插件,
一句话就能生成想要的任何视频。
动效、转场、字幕、配音全自动,不满意继续打字改就行,秒出新版本。 还可以批量生成。
下面这个视频是我让codex生成 【人类编程进化史】的视频,太酷了~
用会 Codex,你就真正打开了 AI 内容创作的新世界大门。
我强烈建议所有自媒体人、内容创作者都要学会codex,这套玩法真的能把效率直接拉高十倍。
还有更多玩法,以后分享哦~
爱丽丝呀!@BTCqzy1
【Codex 保姆级 小白入门】带你从0到1创建你的第一个项目 很多人下载完 Codex 打开界面就懵了,不知道第一步该干嘛~ 这期零基础小白教程,我手把手从安装开始,带你一步步搞懂 Codex 的工作逻辑、正确打开方式、权限设置,最后和你一起做出第一个项目~ 看完你就能彻底摆脱界面恐惧,把 Codex 用到自己的日常开发里!
中文
wellback000 retweetledi




wellback000 retweetledi

有个工具悄悄干掉了好几个付费软件
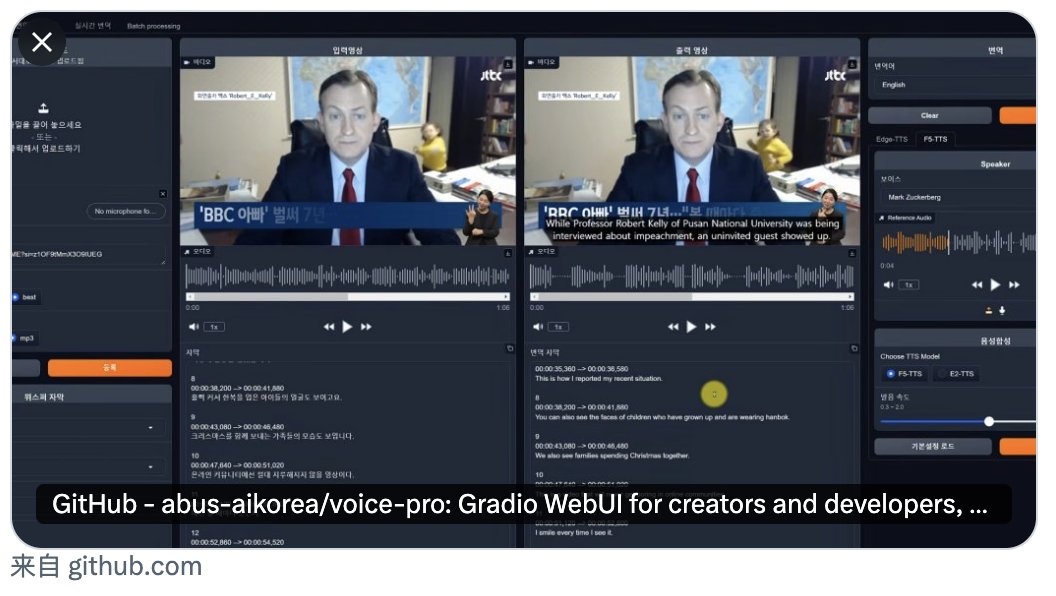
Voice-Pro,开源免费,一键安装
它能做什么: 听三秒声音,克隆任何人的声音 把任意
YouTube 视频变成 100 种语言的配音版 人声和背景音一键分离 实时变声,边说边变
这些功能加在一起 放到 SaaS 平台上卖,每个月至少 $100 起
Voice-Pro 全部免费 代码全部开源 一个韩国小团队做的,成立才一年
8000 个 star 大多数人还不知道它的存在
现在知道了👇
中文
wellback000 retweetledi

wellback000 retweetledi

做油管视频副业搞钱的都懂😭
下载油管视频、消人声、转字幕、翻译、多语言重新配音
以前手动一套折腾半小时,还频繁翻车浪费时间
挖到开源神器 Voice-Pro 直接封神✨
扔个YouTube链接全自动一条龙搞定:
✅一键下载油管视频
✅高清智能去人声
✅精准语音转录字幕
✅100+语种一键翻译
✅原声克隆自动配音
全程本地离线运行、完全免费、不用联网,隐私超安心🔒
从前半小时的活,现在2分钟搞定!
做多语言账号、搬运二次剪辑、靠油管副业变现效率直接拉满,省下超多时间专心搞收益☕
GitHub直达👉 github.com/abus-aikorea/v…
靠油管做副业、做自媒体变现的一定要冲!
有没有被剪辑流程搞崩溃的?还有啥好工具大家可以评论区推荐一下
中文

wellback000 retweetledi

Google TPU被视作未来云业务最强的增长点之一,2026年出货量预计为300 万片。那这么大的需求,参与生产的厂商和环节有哪些呢?
📕芯片设计(ASIC Design)
Broadcom $AVGO — TPU 8t 训练芯片
MediaTek 联发科— TPU 8i 推理芯片
$GOOG — 架构定义 + 软件协同
📗 晶圆制造
$TSMC (N3 现役 / N2 规划中)
📦 先进封装
$TSMC CoWoS-L(主力)+ ASE/SPIL(补充)
📔高带宽内存(HBM)
Samsung — HBM4 主力供应商
SK Hynix — HBM3E 现有供应
Micron $MU — HBM4 爬坡中
📒网络与互联(Networking)
Google 自研 — Virgo switch ASIC (核心)
Marvell $MRVL — 网络 ASIC
Lumentum $LITE — OCS 候选供应商(采样中,未确认) $AAOI / $COHR — 光收发器潜在受益方(无直接 TPU 供应关系披露)
📁 存储(Storage)
DDN — Managed Lustre 10T 后端(EXAScaler)
Google — TPUDirect Storage / Hyperdisk
中文
wellback000 retweetledi

自建AI中转站成本计算
VPS 一台 5美元一个月
域名 10美元一年
下面程序都不要钱,随便选一个
New API - 开源中转程序不要钱
One API - 开源中转程序不要钱
All API Hub - 用于管理多个中转站的仪表盘工具。
Sub2API - 逆向工具,可将官方网页订阅或特定服务转化为标准 API 格式
客户端,不要钱,随便选一个
Lobe Chat 功能最丰富的 AI 客户端。
Chatbox 桌面端和网页端工具。
NextChat 适合个人快速部署的轻量化开源 UI。
Cherry Studio 支持多模型,桌面客户端
买下面账号一枚就行了
OpenAI
Anthropic
这样搞下来,你就自己能稳定使用,还不会保留自己的隐私,也不会被人骗。
中文

