
d6i
670 posts









多数股民没有见过真正的牛市
没有见过真正泡沫
以至于泡沫来的时候,太胆小
因为害怕早早地了结了头寸
我告诉你们,这一轮
GPU
DRAM
CPU
CPO……
的浪潮将是史无前例的。要炒到大票50倍市盈率以上都不算过分
中文

from @tombkeeper
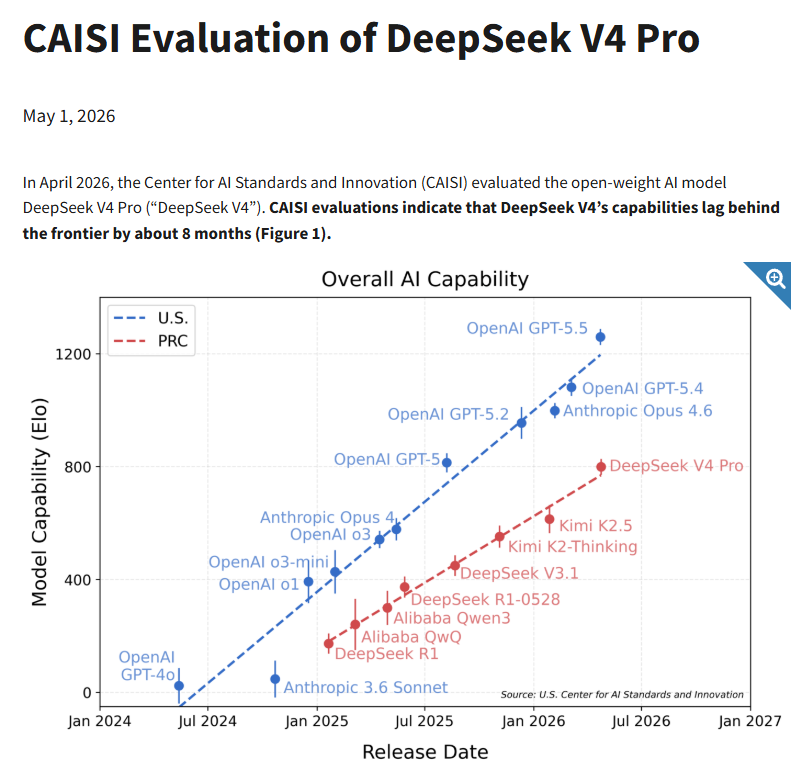
2026 年 5 月 1 日,美国国家标准与技术研究院(NIST)下属的人工智能标准与创新中心(CAISI)发布了对 DeepSeek V4 的测试。结论是:
1、DeepSeek V4 是迄今为止 CAISI 评估过的最强大中国 AI 模型。
2、CAISI 认为 DeepSeek V4 的性能与 8 个月前发布的 GPT-5 类似,而 DeepSeek 自己的测试报告则认为与 Opus 4.6 和 GPT-5.4 类似。
3、和同类模型相比,DeepSeek V4 最大的优势是成本低廉。
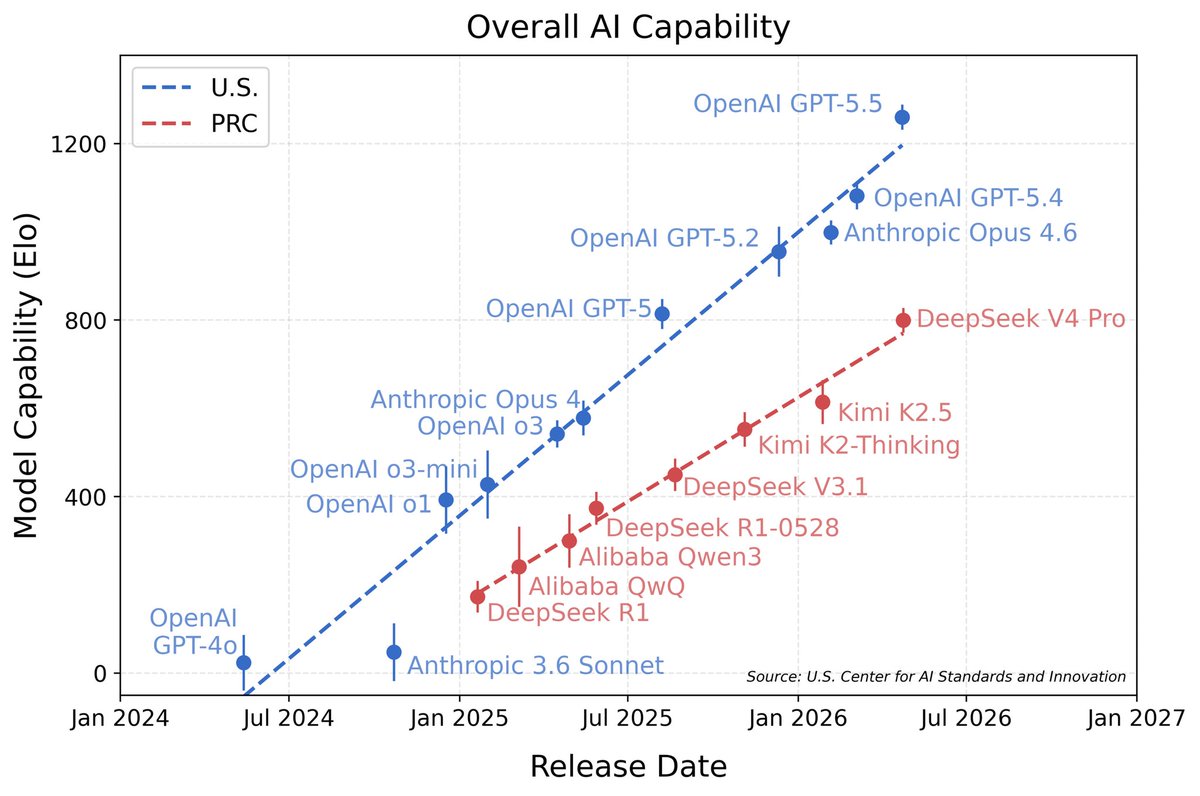
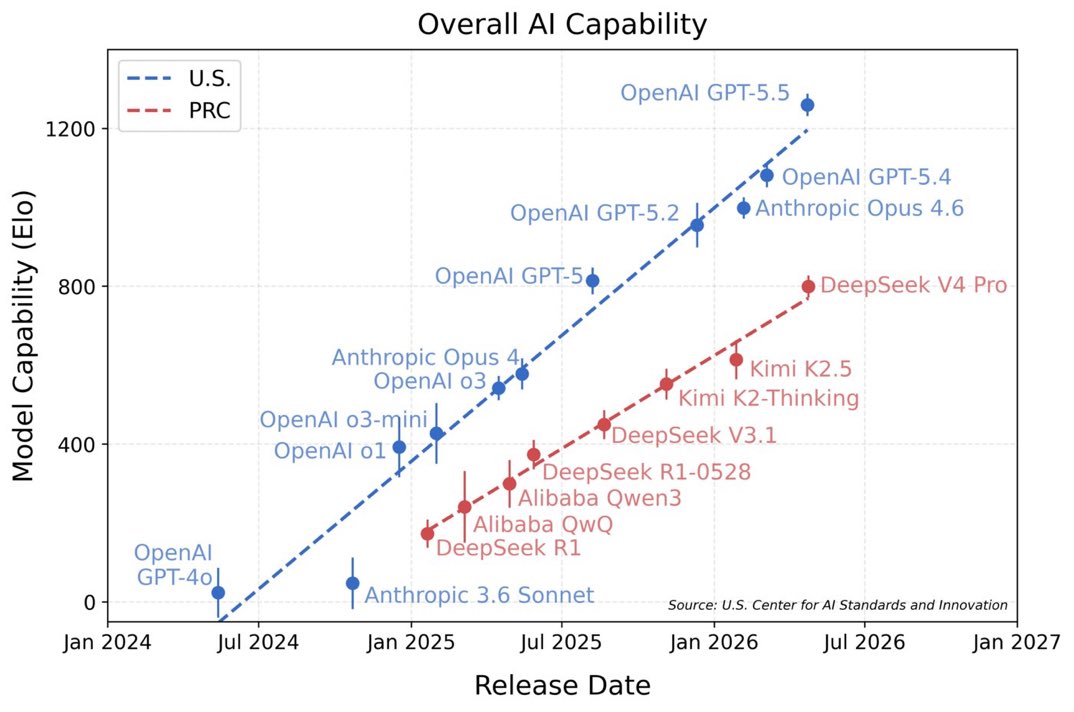
CAISI 评估报告中最引人注意的是下面这张图。这张图暗示了自 DeepSeek R1 发布以来,中国最强大的模型和美国最强大的模型之间的差距实际上在慢慢扩大。
论文链接放评论区
中文




NIST(美国国家标准与技术研究院)出的报告说Deepseek v4落后美国AI顶尖模型8个月。
乍一看挺唬人的,但是你如果细看它用的那套评价体系...你就会发现这等于美国政府出具的、关于美国模型在自己擅长的非公开考题上表现更佳的报告:
报告采用了IRT(项目反应理论)的方式进行能力分数转换和回归拟合,给出的结论是DeepSeek V4的Elo约800,落后美国最前沿约8个月。
问题不在于IRT方法本身,它确实比简单平均准确率更科学,能够建模不同题目的难度差异;而在于如何选择“锚定模型”来校准800分的含义。如果校准用的参考模型本身是闭源、非公开评测体系的产物,那么拟合出的“8个月差距”可能反映的是参考系的选择效应,而非纯粹的技术差距。
报告中显示的“差距”主要集中在两个CAISI内部/私有的基准上:CTF-Archive-Diamond(网络安全)和PortBench(软件工程)。在这两项上,DeepSeek V4 Pro的得分显著低于参考模型。
在公开基准上,DeepSeek V4 Pro的表现与顶尖模型相当接近:OTIS-AIME-2025数学基准达到97%(GPT-5.5为100%),PUMaC 2024数学基准达到96%(与GPT-5.5持平),SMT 2025达到96%(GPT-5.5为99%),GPQA-Diamond达到90%(GPT-5.5为96%)。
这也与Hacker News社区对该报告的总结一致—DeepSeek在公开基准上表现优异,但内部私有基准是差距的主要来源。CAISI内部基准的非公开性质带来了一个根本性的测量问题:这些基准无法被独立验证。
科学评估的基本原则是可重复性和透明度。当基准本身不公开,而模型开发者(尤其是非美国企业)无法获取其具体任务和评判标准时,意味着这种评估本身就是个黑箱。
报告单独承认了DeepSeek V4的成本效率优势:在7个基准测试中有5个的性价比优于GPT-5.4 mini(注意,这是拿最便宜GPT的来比都比不过),但在加权解读时明显给了这一优势较低的权重。
DeepSeek V4-Pro-Max在LiveCodeBench上以93.5分位列所有模型全球第一,在Codeforces评分上以3206分超过GPT-5.4的3168分和Gemini 3.1的3052分,在SWE-bench Verified上达到80.6%与Claude Opus 4.6持平,在Agentic Coding基准上也超过Claude和Gemini。这意味着在编程这一大模型商业化最核心的应用场景之一,DeepSeek已具备与顶尖闭源模型正面竞争的能力。
报告聚焦的网络安全、抽象推理等领域的落后固然存在,但商业落地的核心价值恰恰在于用户最常用的数学推理、科学计算、代码生成等高频任务,而非某些仅出现在评测中的边缘维度。
所以这份报告真正的价值不是技术评测,而是政治安慰剂。
中文

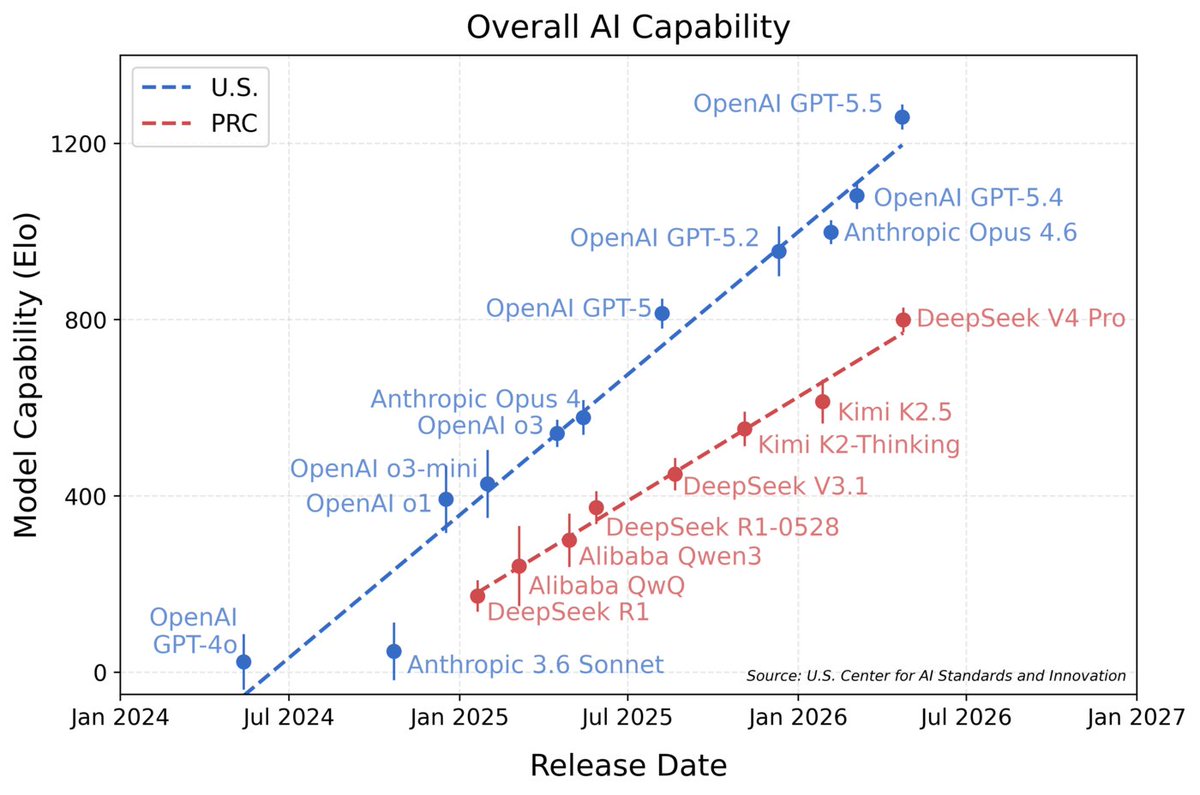
美国国家标准与技术研究院锐评DeepSeek V4 Pro:目前最强中国AI,真实能力落后美国最前沿约8个月。虽然DeepSeek官方自测时觉得已经跟刚发布2个月的GPT-5.4 差不多了,但NIST用没有公开过的私密题库一考,发现它实际水平大概相当于8个月前发布的GPT-5。DeepSeek V4 Pro被拿来和GPT-5.4 mini放在一起讨论
中文

美国商务部标准研究院:Deepseek V4 Pro在非公开benchmark上能力和GPT 5相当,差距8个月。Deepseek V4 Pro可比模型是GPT 5.4 mini而非Claude Opus 4.6和GPT 5.4
Séb Krier@sebkrier
DeepSeek V4’s capability lags behind leading U.S. models by about 8 months. nist.gov/news-events/ne…
中文

这个研究最大的方法论错误是忽略开源的巨大成本优势。在Deepseek V4 Pro差距SOTA模型并不多,但价格几十倍下降的情况下,你觉得用户会担心这所谓8个月的赛马差距吗?用户不是每个任务都是黑进华尔街和破解p=Np难题。用户需要能打、便宜、稳定、能控制的模型。
Lisan al Gaib@scaling01
chinese models are ~8 months behind and are falling further behind
中文






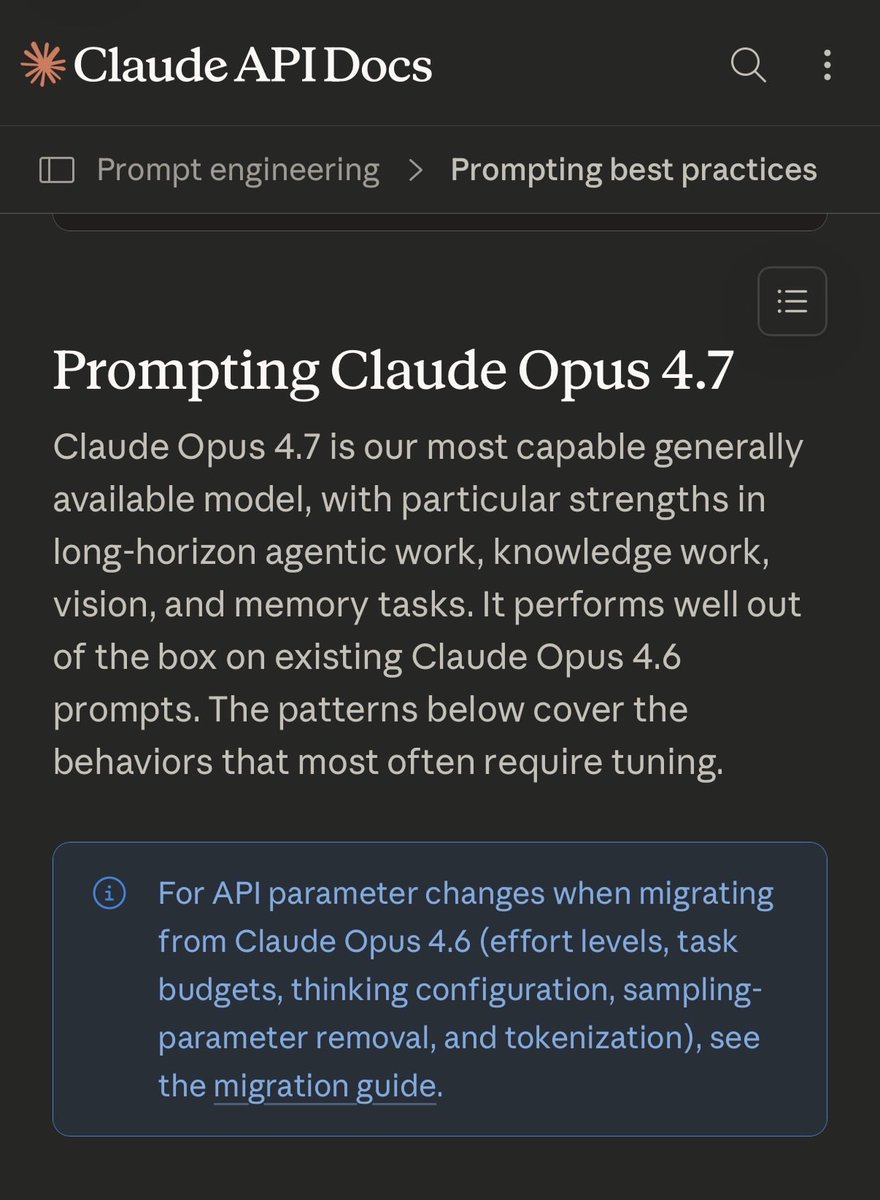
GPT-5.5 和 Claude Opus 4.7 同一天发了官方提示工程指南。
两家的建议完全相反,
1️⃣OpenAI 说:少给流程,说清楚你要什么结果,让模型自己选路径。
2️⃣Anthropic 说:别指望它猜你意思,意图、格式、成功标准,一个都不能含糊。
一个嫌你管太多,一个嫌你说不清楚。
Claude 首席工程师 Boris Cherny 说,他自己都需要几天适应🤣
→ Anthropic Claude Opus 4.7 迁移指南:
platform.claude.com/docs/en/build-…
→ OpenAI GPT-5.5 提示工程指南:
developers.openai.com/api/docs/guide…
→ OpenAI《使用 GPT-5.5》官方文档:
developers.openai.com/api/docs/guide…
→ Boris Cherny(Claude Code 首席工程师)
→ t.co/ZXSgy1uIMA 对数百个社区帖子的深度分析(提示具体性与输出质量高度正相关)
阿绎 AYi@AYi_AInotes
我终于明白为啥最近很多人都在说,GPT和Claude突然变笨了, 昨天OpenAI和Anthropic同时发布了官方提示工程指南, 看完我才发现,并不是模型变笨了, 是它们终于聪明到,不再容忍人类懒得想清楚了🤣🤣🤣 而且最有意思的是, 两个模型的进化方向,居然是完全相反的, Claude Opus 4.7变得越来越字面, 以前它会主动帮你补全模糊的指令, 现在你说什么它就做什么,多一个字都不会猜🤣🤣 GPT-5.5变得越来越自主, 以前你要手把手教它每一步怎么做, 现在你只要告诉它你想要什么结果,它自己会选最优路径, 所以老提示失效的原因也完全相反, 用在Claude上的模糊提示,会得到越来越窄的输出, 用在GPT上的详细流程,会变成多余的噪声, 过去三年我们一直在学怎么教模型做事, 现在反过来了, 模型开始要求我们,先把自己的思考结构化, 其实就是提示工程的本质, 已经从教模型怎么做,变成了先把自己想明白, 所以真正的瓶颈可能不是模型的能力,而是写提示的那个人的思考清晰度, 我感觉以后赢的人,不会是提示写得最长最复杂的人,而是那个最知道自己真正想要什么的人🤔
中文

彭博:高盛分析师建议投资 AI 超大规模服务商而非芯片制造商
"我们建议做多超大规模企业,同时低配半导体股,"高盛股票研究联席主管、资深半导体分析师科维洛在周四给客户的一份报告中写道。"这一观点的出发点是,市场对超大规模企业的投资回报率已计入了相当程度的怀疑,这反映在该类公司估值倍数的大幅压缩上。"
科维洛认为,有两种情况会使这种相对价值交易获得回报。第一种情况是,超大规模企业开始展示出积极的投资回报率,使投资者对其支出不那么警惕,从而推动这些公司的估值回升。他表示,鉴于市场已经对芯片股给予了回报,它们的上涨空间将较小。
"我们认为这是该交易策略的最佳情境,因为超大规模云服务商将因现金流前景改善而迎来显著反弹,而半导体股将因云服务商资本支出降低对其营收的负面影响而遭遇重挫。"他说道。

中文
我终于明白为啥最近很多人都在说,GPT和Claude突然变笨了,
昨天OpenAI和Anthropic同时发布了官方提示工程指南,
看完我才发现,并不是模型变笨了,
是它们终于聪明到,不再容忍人类懒得想清楚了🤣🤣🤣
而且最有意思的是,
两个模型的进化方向,居然是完全相反的,
Claude Opus 4.7变得越来越字面,
以前它会主动帮你补全模糊的指令,
现在你说什么它就做什么,多一个字都不会猜🤣🤣
GPT-5.5变得越来越自主,
以前你要手把手教它每一步怎么做,
现在你只要告诉它你想要什么结果,它自己会选最优路径,
所以老提示失效的原因也完全相反,
用在Claude上的模糊提示,会得到越来越窄的输出,
用在GPT上的详细流程,会变成多余的噪声,
过去三年我们一直在学怎么教模型做事,
现在反过来了,
模型开始要求我们,先把自己的思考结构化,
其实就是提示工程的本质,
已经从教模型怎么做,变成了先把自己想明白,
所以真正的瓶颈可能不是模型的能力,而是写提示的那个人的思考清晰度,
我感觉以后赢的人,不会是提示写得最长最复杂的人,而是那个最知道自己真正想要什么的人🤔

中文